Python2.7下安装Scrapy框架步骤教程
由于毕业设计的要求,需要在网站上抓取大量的数据,那么使用Scrapy框架可以让这一过程变得简单不少,毕竟Scrapy是一个为了爬去网站数据、提取结构性数据而编写的应用框架。于是,便开始了我的安装Scrapy框架之旅。可以说这个过程并不是很愉快,各种错误各种出,不过到最后,终于安装上了Scrapy框架。下面总结一下我的Scrapy框架的安装。
1.安装python2.7
由于Scrapy不支持Python3.0,于是我卸载了Python3.0,又重新安装了Python2.7(python2.7安装包),在安装Python2.7的时候,会有一个自动设置环境变量的选项,建议在这里将选项选上,省下后期自己添加环境变量。我们后期自己添加环境变量,就是根据自己实际安装的路径,在系统的环境变量path中添加这两条语句就可以。
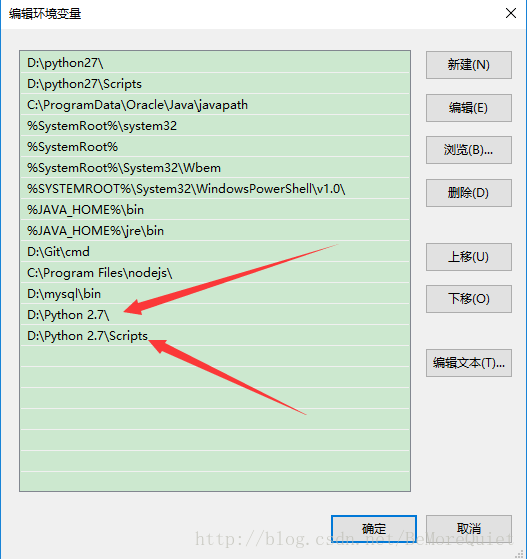
在配置完环境之后,我们测试一下我们是否安装配置环境成功。只要在cmd中输入 python –version ,然后能够显示正确的python版本就可以了。如果未能显示,则重启一下cmd试试。
2.安装pywin32
在安装配置好python2.7之后,我们还不能直接安装Scrapy,我们首先需要安装Scrapy依赖的几个工具。接下来安装pywin32(pywin32安装包),这个软件安装的时候一直next就可以了。
3.安装pip
pip实际上一款比较方便的在线软件安装工具,类似于easy install,我们现在安装pip,在之后的软件安装的时候我们就可以使用 pip install 命令了。首先我们要下载get-pip.py(get-pip.py文件) ,下载完成之后,我们在cmd下进行安装,首先切换到文件所在目录,然后输入python get-pip.py语句,便可以进行安装了,但是最头疼的问题出现了,由于该文件会将一些配置文件自动写入到我们的C盘用户文件目录下,而我的用户目录是中文名,就会产生编码异常。
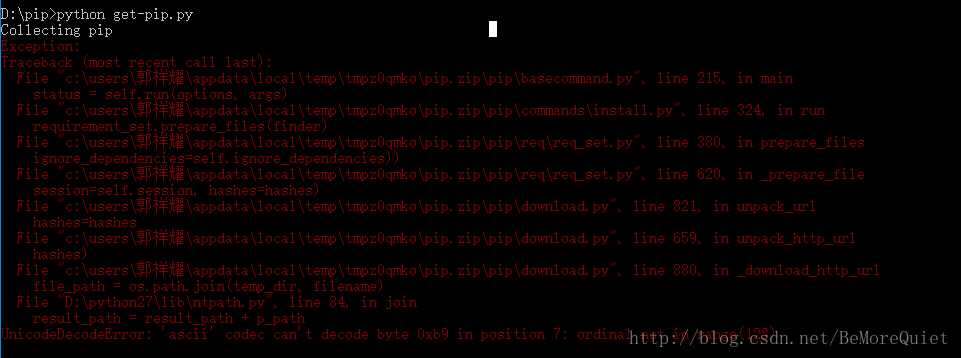
在查找一番资料之后,终于将问题解决了,为了解决中文路径的问题,我们只需要在 D:\python27\Lib\site-packages的目录下新建一个名为
sitecustomize.py的文件即可。

然后在文件内输入以下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
当然不一定一定要设置为gbk编码,这个根据自己的电脑的编码来设置。这样我们的中文路径问题就算解决了,我们在重启cmd,在执行安装pip语句之后,pip便顺利完成了。安装完成之后,我们可以进行一下检验,在cmd中输入pip –version,如果显示正确的版本号则说明正确。

4.安装lxml
在安装完成pip之后,本想可以轻松的使用pip install lxml命令来进行安装,但是意外发生了,由于使用pip需要vc2008的环境,而且只能是2008的,2013的都不行。没办法为了使用这款工具,只能在去求教度娘,终于找到了解决办法,原来微软给我们提供了VcForPython(VCForPython安装包),这样我们就不用安装VC2008了,这样之后,我们便可以使用 pip install lxml进行安装了。
5.安装pyOpenSSL
在安装这个工具的时候我们便可以使用 pip install pyOpenSSL 语句来进行安装了,安装的速度取决于网速了。
6.安装Scrapy
终于经历一波坎坷之后,我们终于可以安装Scrapy框架了,在cmd中输入 pip install Scrapy命令之后,我们就可以等着享受成功的喜悦了。在安装完成之后,我们在cmd中输入Scrapy来检测一下,是否真正的安装成功。
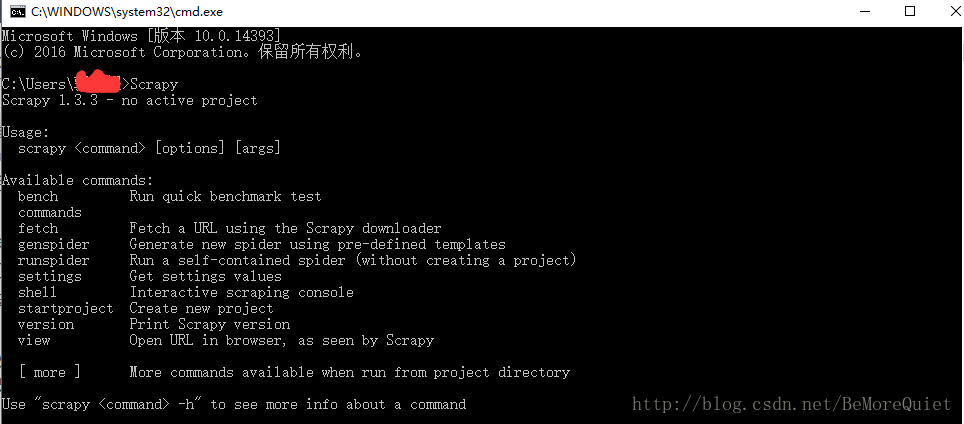
终于安装好了,还是有点成就感的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

在Linux系统上安装Python的Scrapy框架的教程
这是一款提取网站数据的开源工具.Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展.我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS. 安装 Scrapy Scrapy依赖于Python.开发库和pip.Python最新的版本已经在Ubuntu上预装了.因此我们在安装Scrapy之前只需安装pip和python开发库就可以了. pip是作为python包索引器easy_install的替代品,用于安装和管理Python
-
Mac中Python 3环境下安装scrapy的方法教程
前言 最近抽空想学习一下python的爬虫框架scrapy,在mac下安装的时候遇到了问题,逐一解决了问题,分享一下,话不多说了,来一起看看详细的介绍吧. 步骤如下: 1. 从官网 下载最新版本Python 3.6.3(本地快速下载安装:http://www.jb51.net/softs/583651.html) # 在Mac上Python3环境下安装scrapy 2. 安装 Python3 在终端输入python3出现下面的内容表示安装成功 ➜ ~ python3 Python 3.6.3 (
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
python安装Scrapy图文教程
安装方法 pip install Scrapy 如果顺利的话不用管直接一路下来就OK 验证是否安装成功 安装成功 不顺利的情况 1)lxml安装不成功 使用whl进行安装,不过需要先安装whl pip install wheel 安装完成后下载lxml的whl文件 网址: http://www.lfd.uci.edu/~gohlke/pythonlibs/ whl版本挑选 进入cmd-->import pip-->print pip.pep425tags.get_supported(),按照截
-
windows10系统中安装python3.x+scrapy教程
官网下载就好, https://www.python.org/downloads/release/python-352/ 用installer下载比较方便,它直接把环境变量都帮你配了. 当然也可以在本站下载 http://www.jb51.net/softs/416037.html 升级pip 安装好之后在cmd里执行 python -m pip install -upgrade pip 把pip提到最新版本 下载lxml lxml是解析网页用的,scrapy依赖于它,它是一个第三方的库,这里推
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
python中安装Scrapy模块依赖包汇总
本地虚拟环境开发完成之后,上线过程中需要一一安装依赖包,做个记录如下: CentOS 安装python3.5.3 wget https://www.python.org/ftp/python/3.5.3/Python-3.5.3.tgz tar -xf Python-3.5.3.tgz cd Python-3.5.3 ./configure --prefix=/usr/local/python353 make & make install 完成安装python3.5.3,在不删除系统自带的pyt
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
零基础写python爬虫之爬虫框架Scrapy安装配置
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫框架Scrapy就这样出场了! Scrapy = Scrach+Python,Scrach这个单词是抓取的意思, Scrapy的官网地址:点我点我. 那么下面来简单的演示一下Scrapy的安装流程. 具体流程参照:http://www.jb51.net/article/48607.htm 友情提醒:
-
Python3安装Scrapy的方法步骤
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Pytho