Python使用Django实现博客系统完整版
今天花了一些时间搭了一个博客系统,虽然并没有相关于界面的美化,但是发布是没问题的。
开发环境
操作系统:windows 7 64位
Django: 1.96
Python:2.7.11
IDE: PyCharm 2016.1
功能篇
既然是博客系统,发布的自然是博客了。让我们想想,一篇博客有什么属性。所以我们要有能添加博客,删除博客,修改博客,以及给博客发评论,贴标签,划分类等功能。
关系分析
属性
博客:标题,内容。
标签:标签名
分类:分类的名称
评论:评论人,评论人email,评论内容
关系
博客:一篇博客可以有多个标签,多个评论,属于一个分类
标签:一类标签可以赋予多篇博客,一个博客也可以由多个标签,所以是多对多的关系
分类:一个分类内部可以有多个博客,所以和博客是一对多的关系
评论:很明显一个评论属于一个博客,而一个博客可以有很多的评论,所以是一对多的关系。
模型层设计
废话不多说,根据上一步的关系分析,直接设计即可。
# coding:utf8
from __future__ import unicode_literals
from django.db import models
# Create your models here.
class Catagory(models.Model):
"""
博客分类
"""
name = models.CharField('名称',max_length=30)
def __unicode__(self):
return self.name
class Tag(models.Model):
"""
博客标签
"""
name = models.CharField('名称',max_length=16)
def __unicode__(self):
return self.name
class Blog(models.Model):
"""
博客
"""
title = models.CharField('标题',max_length=32)
author = models.CharField('作者',max_length=16)
content = models.TextField('博客正文')
created = models.DateTimeField('发布时间',auto_now_add=True)
catagory = models.ForeignKey(Catagory,verbose_name='分类')
tags = models.ManyToManyField(Tag,verbose_name='标签')
def __unicode__(self):
return self.title
class Comment(models.Model):
"""
评论
"""
blog = models.ForeignKey(Blog,verbose_name='博客')
name = models.CharField('称呼',max_length=16)
email = models.EmailField('邮箱')
content = models.CharField('内容',max_length=240)
created = models.DateTimeField('发布时间',auto_now_add=True)
def __unicode__(self):
return self.content
数据库设置
# Database
# https://docs.djangoproject.com/en/1.9/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
然后Django就可以根据我们刚才的模型来逆向的生成数据库底层的业务逻辑。然后就需要调用相关的命令即可。
python manage.py makemigrations python manage.py migrate
这样,框架就会帮助我们完成底层的数据库操作了。而且不用担心表与表之间的关系。

管理层
由于我们完成了模型的创建了,所以想当然的需要来个管理的,那么让admin登场吧,所以我们需要将模型注册到admin上面,这样就会在管理页面出现这三个选项了。
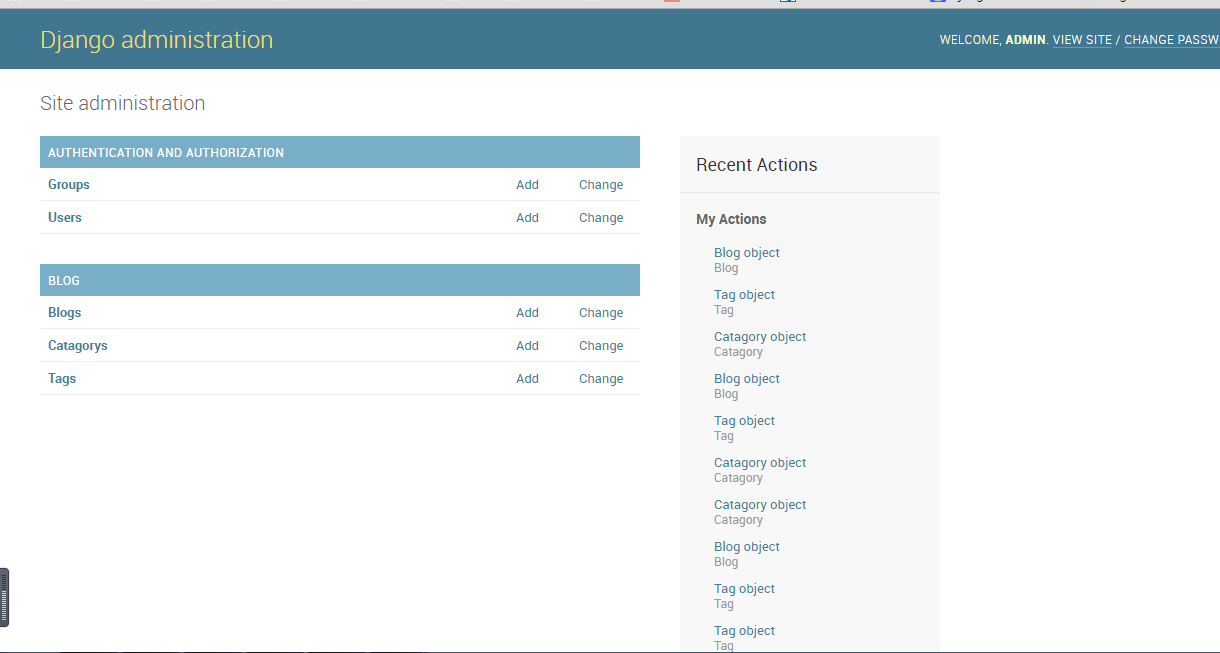
Controller层设计
其实就是urls.py 的书写,没什么好说的了吧,如下:
# coding:utf8 from django.contrib import admin # Register your models here. from Blog.models import * # 注册的目的就是为了让系统管理员能对注册的这些模型进行管理 admin.site.register([Catagory,Tag,Blog])
接下来就是urls.py 的详细信息。
"""MyDjango2 URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/1.9/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.conf.urls import url, include
2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))
"""
from django.conf.urls import url
from django.contrib import admin
from Blog.views import *
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^blogs/$',get_blogs),
url(r'^detail/(\d+)/$',get_details ,name='blog_get_detail'),
]
View层
视图层的展示如下:
from django.shortcuts import render,render_to_response
# Create your views here.
from Blog.models import *
from Blog.forms import CommentForm
from django.http import Http404
def get_blogs(request):
blogs = Blog.objects.all().order_by('-created')
return render_to_response('blog-list.html',{'blogs':blogs})
def get_details(request,blog_id):
try:
blog = Blog.objects.get(id=blog_id)
except Blog.DoesNotExist:
raise Http404
if request.method == 'GET':
form = CommentForm()
else:
form = CommentForm(request.POST)
if form.is_valid():
cleaned_data = form.cleaned_data
cleaned_data['blog'] = blog
Comment.objects.create(**cleaned_data)
ctx = {
'blog':blog,
'comments':blog.comment_set.all().order_by('-created'),
'form':form
}
return render(request,'blog_details.html',ctx)
想必大家也看到了模板html,所以接下来介绍一下模板的书写。
模板系统
这里的模板主要是用到了两个,一个是博客列表模板,另一个是博客详情界面模板。配合了模板变量以及模板标签,就是下面这个样子了。
先看blog_list.html
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>My Blogs</title>
<style>
.blog{
padding:20px 0px;
}
.blog .info span {
padding-right: 10px;
}
.blog .summary {
padding-top:20px;
}
</style>
</head>
<body>
<div class="header">
<h1 align="center">My Blogs</h1>
</div>
{% for blog in blogs %}
<div align="center" class="blog">
<div class="title">
<a href="{% url 'blog_get_detail' blog.id %}" rel="external nofollow" rel="external nofollow" ><h2>{{ blog.title }}</h2></a>
</div>
<div class="info">
<span class="catagory" style="color: #ff9900;">{{ blog.catagory.name }}</span>
<span class="author" style="color: #4a86e8;">{{ blog.author }}</span>
<span class="created" style="color: #6aa84e;">{{ blog.created |date:"Y-m-d H:i" }}</span>
</div>
<div class="summary">
{{ blog.content | truncatechars:100 }}
</div>
</div>
{% endfor %}
</body>
</html>
接下来是blog_details.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ blog.title }}</title>
<style>
.blog {
padding: 20px 0px;
}
.blog .info span {
padding-right: 10px;
}
.blog .summary {
padding-top: 20px;
}
</style>
</head>
<body>
<div class="header">
<span><a href="{% url 'blog_get_detail' blog.id %}" rel="external nofollow" rel="external nofollow" >{{ blog.title }}</a></span>
</div>
<div class="content">
<div class="blog">
<div class="title">
<a href="#" rel="external nofollow" ><h2>{{ blog.title }}</h2></a>
</div>
<div class="info">
<span class="category" style="color: #ff9900;">{{ blog.category.name }}</span>
<span class="author" style="color: #4a86e8">{{ blog.author }}</span>
<span class="created" style="color: #6aa84f">{{ blog.created|date:"Y-m-d H:i" }}</span>
</div>
<div class="summary">
{{ blog.content }}
</div>
</div>
<div class="comment">
<div class="comments-display" style="padding-top: 20px;">
<h3>评论</h3>
{% for comment in comments %}
<div class="comment-field" style="padding-top: 10px;">
{{ comment.name }} 说: {{ comment.content }}
</div>
{% endfor %}
</div>
<div class="comment-post" style="padding-top: 20px;">
<h3>提交评论</h3>
<form action="{% url 'blog_get_detail' blog.id %}" method="post">
{% csrf_token %}
{% for field in form %}
<div class="input-field" style="padding-top: 10px">
{{ field.label }}: {{ field }}
</div>
<div class="error" style="color: red;">
{{ field.errors }}
</div>
{% endfor %}
<button type="submit" style="margin-top: 10px">提交</button>
</form>
</div>
</div>
</div>
</body>
</html>
添加评论
这里借助Django的forms模块可以方便的集成评论功能。
我们需要在Blog应用中新建一个forms.py来做处理。
# coding:utf-8
from django import forms
"""
借此实现博客的评论功能
"""
class CommentForm(forms.Form):
"""
评论表单用于发表博客的评论。评论表单的类并根据需求定义了三个字段:称呼、邮箱和评论内容。这样我们就能利用它来快速生成表单并验证用户的输入。
"""
name = forms.CharField(label='称呼',max_length=16,error_messages={
'required':'请填写您的称呼',
'max_length':'称呼太长咯'
})
email = forms.EmailField(label='邮箱',error_messages={
'required':'请填写您的邮箱',
'invalid':'邮箱格式不正确'
})
content = forms.CharField(label='评论内容',error_messages={
'required':'请填写您的评论内容!',
'max_length':'评论内容太长咯'
})
这个文件的使用在views.py中的ctx中,以及blog_details.html模板文件中可以体现出来。
启动服务
python manage.py runserver
调用这个功能,就可以启动我们的开发服务器了,然后在浏览器中输入http://127.0.0.1:8000/blogs 你就会发现下面的这个界面。

随便点进去一个,就可以进入博客的详情页面了。
由于界面很难看,这里就不演示了,但是功能确实是很强大的,特别是对评论的验证功能。
总结
完成了这个比较“cool”的博客系统,其实并没有完成。加上一些CSS特效的话会更好。还有集成一下富媒体编辑器的话效果会更好。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python 爬虫爬取指定博客的所有文章
- Python采用Django开发自己的博客系统
- python实现批量下载新浪博客的方法
- python抓取最新博客内容并生成Rss
- 通过Python爬虫代理IP快速增加博客阅读量
- 如何使用python爬取csdn博客访问量
- 使用Python实现博客上进行自动翻页
- Python实现新浪博客备份的方法
- 用Python的Tornado框架结合memcached页面改善博客性能
- 使用python和Django完成博客数据库的迁移方法
相关推荐
-
Python实现新浪博客备份的方法
本文实例讲述了Python实现新浪博客备份的方法.分享给大家供大家参考,具体如下: Python2.7.2版本实现,推荐在IDE中运行. # -*- coding:UTF-8 -*- # ''' Created on 2011-12-18 @author: Ahan ''' import re import sys import os import time import socket import locale import datetime import codecs from urllib
-

使用python和Django完成博客数据库的迁移方法
上一讲完成了基本博客的配置和项目工程的生成.这次开始将博客一些基本的操作主要是数据库方面学习. 1.设计博客数据库表结构 博客最主要的功能就是展示我们写的文章,它需要从某个地方获取博客文章数据才能把文章展示出来,通常来说这个地方就是数据库.我们把写好的文章永久地保存在数据库里,当用户访问我们的博客时,Django 就去数据库里把这些数据取出来展现给用户. 博客的文章应该含有标题.正文.作者.发表时间等数据.一个更加现代化的博客文章还希望它有分类.标签.评论等.为了更好地存储这些数据,我们需要合理
-
Python采用Django开发自己的博客系统
好久之前就想做一下自己的博客系统了,但是在网上查了查好像是需要会一些Node.js的相关知识,而且还要安装辣么多的库什么的,就不想碰了.但是我遇到了Django这么一款神器,没想到我的博客系统就这么建立起来了.虽然是最基础的类型.但是也算是成功了,这篇博客比较适合对Django有了一定了解的童鞋,如果是新手的话,建议先看一下django的基础知识点再来做实验,这样效率更高! 好了,话不多说,开始吧. 搭建框架 •创建项目及应用 搭建框架的意思,就是安装Django以及做好相关的配置.因为我是在
-
通过Python爬虫代理IP快速增加博客阅读量
写在前面 题目所说的并不是目的,主要是为了更详细的了解网站的反爬机制,如果真的想要提高博客的阅读量,优质的内容必不可少. 了解网站的反爬机制 一般网站从以下几个方面反爬虫: 1. 通过Headers反爬虫 从用户请求的Headers反爬虫是最常见的反爬虫策略.很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer). 如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agen
-
用Python的Tornado框架结合memcached页面改善博客性能
原因 Blog是一个更新并不很频繁的一套系统,但是每次刷新页面都要更新数据库反而很浪费资源,添加静态页面生成是一个解决办法,同时缓存是一个更好的主意,可以结合Memcached添加少量的代码进行缓存,而且免去去了每次更新文章都要重新生成静态页面,特别当页面特别多时. 实现 主要通过页面的uri进行缓存,结合tornado.web.RequestHandler的prepare和on_finish方法函数, prepare 主要是请求前执行,on_finish()是请求结束之前执行.在渲染模板时缓存
-
Python 爬虫爬取指定博客的所有文章
自上一篇文章 Z Story : Using Django with GAE Python 后台抓取多个网站的页面全文 后,大体的进度如下: 1.增加了Cron: 用来告诉程序每隔30分钟 让一个task 醒来, 跑到指定的那几个博客上去爬取最新的更新 2.用google 的 Datastore 来存贮每次爬虫爬下来的内容..只存贮新的内容.. 就像上次说的那样,这样以来 性能有了大幅度的提高: 原来的每次请求后, 爬虫才被唤醒 所以要花大约17秒的时间才能从后台输出到前台而现在只需要2秒不到
-
python抓取最新博客内容并生成Rss
osc的rss不是全文输出的,不开心,所以就有了python抓取osc最新博客生成Rss # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import urllib2 import datetime import time import PyRSS2Gen from email.Utils import formatdate import re import sys import os reload(sys) sys.setdefaul
-
python实现批量下载新浪博客的方法
本文实例讲述了python实现批量下载新浪博客的方法.分享给大家供大家参考.具体实现方法如下: # coding=utf-8 import urllib2 import sys, os import re import string from BeautifulSoup import BeautifulSoup def encode(s): return s.decode('utf-8').encode(sys.stdout.encoding, 'ignore') def getHTML(url
-
如何使用python爬取csdn博客访问量
最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注,博客专家请勿喷,因为我不是专家,我听他们说专家本身就有这个功能. 一.网址分析 进入自己的博客页面,网址为:http://blog.csdn.net/xingjiarong 网址还是非常清晰的就是cs
-
使用Python实现博客上进行自动翻页
先上一张代码及代码运行后的输出结果的图! 下面上代码: # coding=utf-8 import os import time from selenium import webdriver #打开火狐浏览器 需要V47版本以上的 driver = webdriver.Firefox()#打开火狐浏览器 url = "http://codelife.ecit-it.com"#这里打开我的博客网站 driver.get(url)#设置火狐浏览器打开的网址 time.sleep(2) #使