一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述
这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识。
什么是网络爬虫
简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据。专业的解释:百度百科
分析爬虫需求
确定目标
爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称、豆瓣评分、导演、编剧、主演、类型、制片国家/地区、语言、上映日期、片长、IMDb链接等信息。
分析目标
1.借助工具分析目标网页
首先,我们打开豆瓣电影·热门电影,会发现页面总共20部电影,但当查看页面源代码当时候,在源代码中根本找不到这些电影当信息。这是为什么呢?原来豆瓣在这里是通过ajax技术获取电影信息,再动态的将数据加载到页面中的。这就需要借助Chrome的开发者工具,先找到获取电影信息的API。

然后对电影详情页进行分析

思路分析
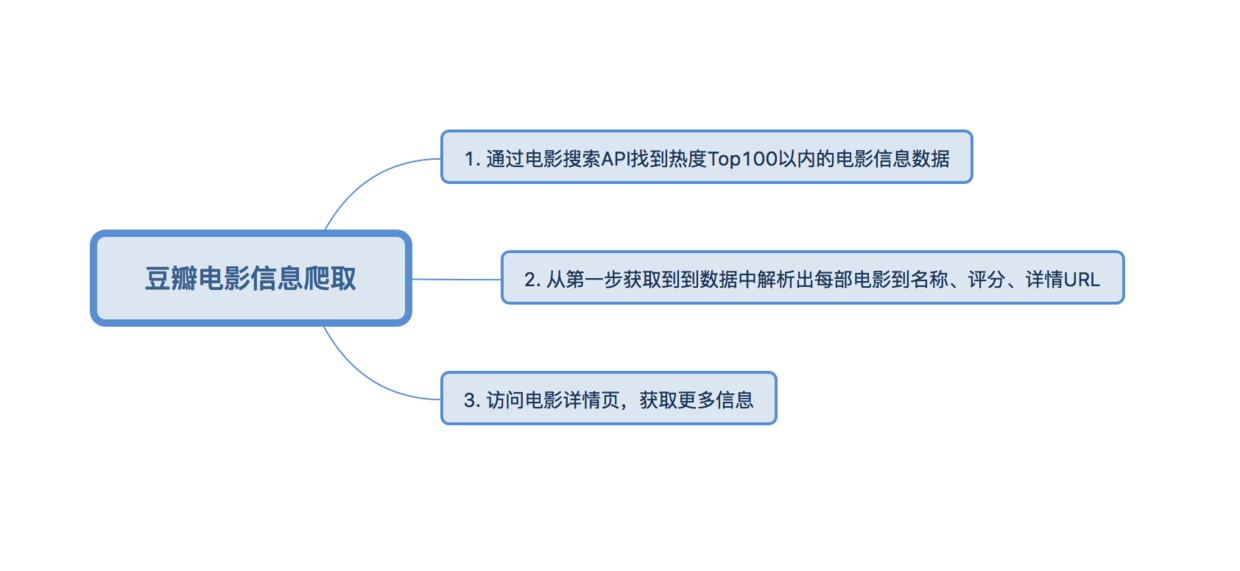
具体实现
开发环境
python3.6
pycharm
主要依赖库
urllib -- 基础性的网络相关操作
lxml -- 通过xpath语法解析HTML页面
json -- 对通过API获取的JSON数据进行操作
re -- 正则操作
代码实现
from urllib import request
from lxml import etree
import json
import re
import ssl
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
def get_headers():
"""
返回请求头信息
:return:
"""
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/65.0.3325.181 Safari/537.36"
}
return headers
def get_url_content(url):
"""
获取指定url的请求内容
:param url:
:return:
"""
content = ''
headers = get_headers()
res = request.Request(url, headers=headers)
try:
resp = request.urlopen(res, timeout=10)
content = resp.read().decode('utf-8')
except Exception as e:
print('exception: %s' % e)
return content
def parse_content(content):
"""
解析网页
:param content:
:return:
"""
movie = {}
html = etree.HTML(content)
try:
info = html.xpath("//div[@id='info']")[0]
movie['director'] = info.xpath("./span[1]/span[2]/a/text()")[0]
movie['screenwriter'] = info.xpath("./span[2]/span[2]/a/text()")[0]
movie['actors'] = '/'.join(info.xpath("./span[3]/span[2]/a/text()"))
movie['type'] = '/'.join(info.xpath("./span[@property='v:genre']/"
"text()"))
movie['initialReleaseDate'] = '/'.\
join(info.xpath(".//span[@property='v:initialReleaseDate']/text()"))
movie['runtime'] = \
info.xpath(".//span[@property='v:runtime']/text()")[0]
def str_strip(s):
return s.strip()
def re_parse(key, regex):
ret = re.search(regex, content)
movie[key] = str_strip(ret[1]) if ret else ''
re_parse('region', r'<span class="pl">制片国家/地区:</span>(.*?)<br/>')
re_parse('language', r'<span class="pl">语言:</span>(.*?)<br/>')
re_parse('imdb', r'<span class="pl">IMDb链接:</span> <a href="(.*?)" rel="external nofollow" '
r'target="_blank" >')
except Exception as e:
print('解析异常: %s' % e)
return movie
def spider():
"""
爬取豆瓣前100部热门电影
:return:
"""
recommend_moives = []
movie_api = 'https://movie.douban.com/j/search_subjects?' \
'type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend' \
'&page_limit=100&page_start=0'
content = get_url_content(movie_api)
json_dict = json.loads(content)
subjects = json_dict['subjects']
for subject in subjects:
content = get_url_content(subject['url'])
movie = parse_content(content)
movie['title'] = subject['title']
movie['rate'] = subject['rate']
recommend_moives.append(movie)
print(len(recommend_moives))
print(recommend_moives)
if __name__ == '__main__':
spider()
效果
 总结
总结
本文较详细的阐述了一个爬虫从需求->分析->实现的过程,并给出了具体的代码实现。通过对本文的学习,我们可以了解到网络爬虫的一些基本的知识,以及python的一些基本库的使用方法。接下来我会使用一些高级些的网络操作相关的库以及对抓取到的数据做个存储的方式,来更深层次的理解python网络爬虫。
特别声明
1. 本文涉及到的豆瓣网是国内知名网站,若有侵权之处,请告知。
2. 本文属作者原创,转载请标明出处;未经允许,不得用于商业用途。
3. 本文只是用作网络爬虫技术学习交流,读者涉及到的任何侵权问题,与本文作者无关。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python爬虫爬取网页表格数据
- Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
- python爬虫爬取快手视频多线程下载功能
- python爬虫爬取淘宝商品信息(selenum+phontomjs)
- python爬虫爬取淘宝商品信息
- python爬虫爬取某站上海租房图片
- Python爬虫爬取一个网页上的图片地址实例代码
- Python爬虫实例_城市公交网络站点数据的爬取方法
- 使用python爬虫实现网络股票信息爬取的demo
- 一个月入门Python爬虫学习,轻松爬取大规模数据
相关推荐
-

Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
一个月入门Python爬虫学习,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单.容易上手. 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容. 淘宝.京东:抓取商品.评论及销量数据,对各种商品及用户的消费场景进行分析. 安居客.链家:抓取房产买卖及租售信息,分析房价变化趋势.做不同区域的房价分
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加