python实现决策树、随机森林的简单原理
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容。
一、概念
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本:
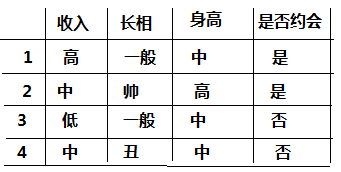
对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树,决策树如下图所示:
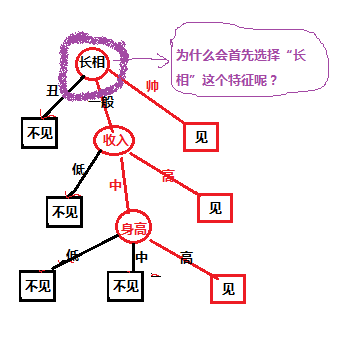
对于上图中的决策树,有个疑问,就是为什么第一个选择是“长相”这个特征,我选择“收入”特征作为第一分类的标准可以嘛?下面我们就对构建决策树选择特征的问题进行讨论;在考虑之前我们要先了解一下相关的数学知识:
信息熵:熵代表信息的不确定性,信息的不确定性越大,熵越大;比如“明天太阳从东方升起”这一句话代表的信息我们可以认为为0;因为太阳从东方升起是个特定的规律,我们可以把这个事件的信息熵约等于0;说白了,信息熵和事件发生的概率成反比:数学上把信息熵定义如下:H(X)=H(P1,P2,…,Pn)=-∑P(xi)logP(xi)
互信息:指的是两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性
现在我们就把信息熵运用到决策树特征选择上,对于选择哪个特征我们按照这个规则进行“哪个特征能使信息的确定性最大我们就选择哪个特征”;比如上图的案例中;
第一步:假设约会去或不去的的事件为Y,其信息熵为H(Y);
第二步:假设给定特征的条件下,其条件信息熵分别为H(Y|长相),H(Y|收入),H(Y|身高)
第三步:分别计算信息增益(互信息):G(Y,长相) = I(Y,长相) = H(Y)-H(Y|长相) 、G(Y,) = I(Y,长相) = H(Y)-H(Y|长相)等
第四部:选择信息增益最大的特征作为分类特征;因为增益信息大的特征意味着给定这个特征,能很大的消除去约会还是不约会的不确定性;
第五步:迭代选择特征即可;
按以上就解决了决策树的分类特征选择问题,上面的这种方法就是ID3方法,当然还是别的方法如 C4.5;等;
二、决策树的过拟合解决办法
若决策树的度过深的话会出现过拟合现象,对于决策树的过拟合有二个方案:
1.剪枝-先剪枝和后剪纸(可以在构建决策树的时候通过指定深度,每个叶子的样本数来达到剪枝的作用)
2.随机森林 --构建大量的决策树组成森林来防止过拟合;虽然单个树可能存在过拟合,但通过广度的增加就会消除过拟合现象
三、随机森林
随机森林是一个最近比较火的算法,它有很多的优点:
- 在数据集上表现良好
- 在当前的很多数据集上,相对其他算法有着很大的优势
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
- 训练速度快
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
- 实现比较简单
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
上一段决策树代码:
# 花萼长度、花萼宽度,花瓣长度,花瓣宽度
iris_feature_E = 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
iris_class = 'Iris-setosa', 'Iris-versicolor', 'Iris-virginica'
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
path = '..\\8.Regression\\iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
x = data[range(4)]
y = pd.Categorical(data[4]).codes
# 为了可视化,仅使用前两列特征
x = x.iloc[:, :2]
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=1)
print y_test.shape
# 决策树参数估计
# min_samples_split = 10:如果该结点包含的样本数目大于10,则(有可能)对其分支
# min_samples_leaf = 10:若将某结点分支后,得到的每个子结点样本数目都大于10,则完成分支;否则,不进行分支
model = DecisionTreeClassifier(criterion='entropy')
model.fit(x_train, y_train)
y_test_hat = model.predict(x_test) # 测试数据
# 保存
# dot -Tpng my.dot -o my.png
# 1、输出
with open('iris.dot', 'w') as f:
tree.export_graphviz(model, out_file=f)
# 2、给定文件名
# tree.export_graphviz(model, out_file='iris1.dot')
# 3、输出为pdf格式
dot_data = tree.export_graphviz(model, out_file=None, feature_names=iris_feature_E, class_names=iris_class,
filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf('iris.pdf')
f = open('iris.png', 'wb')
f.write(graph.create_png())
f.close()
# 画图
N, M = 50, 50 # 横纵各采样多少个值
x1_min, x2_min = x.min()
x1_max, x2_max = x.max()
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.stack((x1.flat, x2.flat), axis=1) # 测试点
print x_show.shape
# # 无意义,只是为了凑另外两个维度
# # 打开该注释前,确保注释掉x = x[:, :2]
# x3 = np.ones(x1.size) * np.average(x[:, 2])
# x4 = np.ones(x1.size) * np.average(x[:, 3])
# x_test = np.stack((x1.flat, x2.flat, x3, x4), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = model.predict(x_show) # 预测值
print y_show_hat.shape
print y_show_hat
y_show_hat = y_show_hat.reshape(x1.shape) # 使之与输入的形状相同
print y_show_hat
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x_test[0], x_test[1], c=y_test.ravel(), edgecolors='k', s=150, zorder=10, cmap=cm_dark, marker='*') # 测试数据
plt.scatter(x[0], x[1], c=y.ravel(), edgecolors='k', s=40, cmap=cm_dark) # 全部数据
plt.xlabel(iris_feature[0], fontsize=15)
plt.ylabel(iris_feature[1], fontsize=15)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid(True)
plt.title(u'鸢尾花数据的决策树分类', fontsize=17)
plt.show()
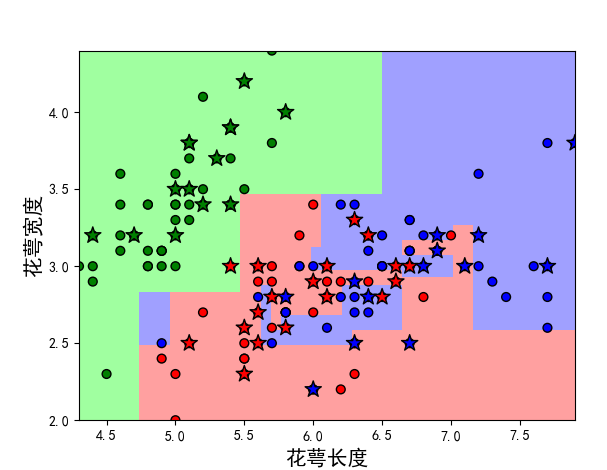

以上就是决策树做分类,但决策树也可以用来做回归,不说直接上代码:
if __name__ == "__main__":
N =100
x = np.random.rand(N) *6 -3
x.sort()
y = np.sin(x) + np.random.randn(N) *0.05
x = x.reshape(-1,1)
print x
dt = DecisionTreeRegressor(criterion='mse',max_depth=9)
dt.fit(x,y)
x_test = np.linspace(-3,3,50).reshape(-1,1)
y_hat = dt.predict(x_test)
plt.plot(x,y,'r*',ms =5,label='Actual')
plt.plot(x_test,y_hat,'g-',linewidth=2,label='predict')
plt.legend(loc ='upper left')
plt.grid()
plt.show()
#比较决策树的深度影响
depth =[2,4,6,8,10]
clr = 'rgbmy'
dtr = DecisionTreeRegressor(criterion='mse')
plt.plot(x,y,'ko',ms=6,label='Actual')
x_test = np.linspace(-3,3,50).reshape(-1,1)
for d,c in zip(depth,clr):
dtr.set_params(max_depth=d)
dtr.fit(x,y)
y_hat = dtr.predict(x_test)
plt.plot(x_test,y_hat,'-',color=c,linewidth =2,label='Depth=%d' % d)
plt.legend(loc='upper left')
plt.grid(b =True)
plt.show()
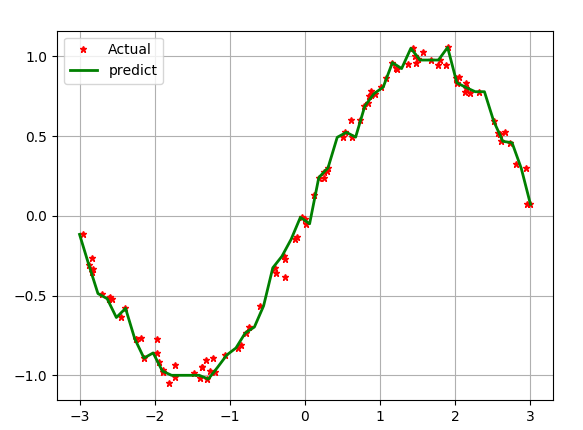
不同深度对回归的 影响如下图:

下面上个随机森林代码
mpl.rcParams['font.sans-serif'] = [u'SimHei'] # 黑体 FangSong/KaiTi mpl.rcParams['axes.unicode_minus'] = False path = 'iris.data' # 数据文件路径 data = pd.read_csv(path, header=None) x_prime = data[range(4)] y = pd.Categorical(data[4]).codes feature_pairs = [[0, 1]] plt.figure(figsize=(10,9),facecolor='#FFFFFF') for i,pair in enumerate(feature_pairs): x = x_prime[pair] clf = RandomForestClassifier(n_estimators=200,criterion='entropy',max_depth=3) clf.fit(x,y.ravel()) N, M =50,50 x1_min,x2_min = x.min() x1_max,x2_max = x.max() t1 = np.linspace(x1_min,x1_max, N) t2 = np.linspace(x2_min,x2_max, M) x1,x2 = np.meshgrid(t1,t2) x_test = np.stack((x1.flat,x2.flat),axis =1) y_hat = clf.predict(x) y = y.reshape(-1) c = np.count_nonzero(y_hat == y) print '特征:',iris_feature[pair[0]],'+',iris_feature[pair[1]] print '\t 预测正确数目:',c cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF']) cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) y_hat = clf.predict(x_test) y_hat = y_hat.reshape(x1.shape) plt.pcolormesh(x1,x2,y_hat,cmap =cm_light) plt.scatter(x[pair[0]],x[pair[1]],c=y,edgecolors='k',cmap=cm_dark) plt.xlabel(iris_feature[pair[0]],fontsize=12) plt.ylabel(iris_feature[pair[1]], fontsize=14) plt.xlim(x1_min, x1_max) plt.ylim(x2_min, x2_max) plt.grid() plt.tight_layout(2.5) plt.subplots_adjust(top=0.92) plt.suptitle(u'随机森林对鸢尾花数据的两特征组合的分类结果', fontsize=18) plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python实现的随机森林算法与简单总结
- Python决策树和随机森林算法实例详解
- python实现随机森林random forest的原理及方法
- 用Python实现随机森林算法的示例
- 用Python从零实现贝叶斯分类器的机器学习的教程
- Python语言实现机器学习的K-近邻算法
- 机器学习python实战之手写数字识别
- python机器学习之神经网络(一)
- Python机器学习之决策树算法实例详解
- python机器学习之随机森林(七)
相关推荐
-
python实现随机森林random forest的原理及方法
引言 想通过随机森林来获取数据的主要特征 1.理论 随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系,可同时生成的并行化方法: 前者的代表是Boosting,后者的代表是Bagging和"随机森林"(
-

机器学习python实战之手写数字识别
看了上一篇内容之后,相信对K近邻算法有了一个清晰的认识,今天的内容--手写数字识别是对上一篇内容的延续,这里也是为了自己能更熟练的掌握k-NN算法. 我们有大约2000个训练样本和1000个左右测试样本,训练样本所在的文件夹是trainingDigits,测试样本所在的文件夹是testDigits.文本文件中是0~9的数字,但是是用二值图表示出来的,如图.我们要做的就是使用训练样本训练模型,并用测试样本来检测模型的性能. 首先,我们需要将文本文件中的内容转化为向量,因为图片大小是32*32,所以
-
python机器学习之随机森林(七)
机器学习之随机森林,供大家参考,具体内容如下 1.Bootstraping(自助法) 名字来自成语"pull up by your own bootstraps",意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法.其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样. (2) 根据抽出的样本计算给定的统计量T. (3) 重复上述N次(一般大于100
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有
-
Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
python机器学习之神经网络(一)
python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干个突触的输入求和后进行调节.为了便于观察,这里的数据采用二维数据. 目标函数是训练结果的误差的平方和,由于目标函数是一个二次函数,只存在一个全局极小值,所以采用梯度下降法的策略寻找目标函数的最小值. 代码如下: import numpy
-
用Python从零实现贝叶斯分类器的机器学习的教程
朴素贝叶斯算法简单高效,在处理分类问题上,是应该首先考虑的方法之一. 通过本教程,你将学到朴素贝叶斯算法的原理和Python版本的逐步实现. 更新:查看后续的关于朴素贝叶斯使用技巧的文章"Better Naive Bayes: 12 Tips To Get The Most From The Naive Bayes Algorithm" 朴素贝叶斯分类器,Matt Buck保留部分版权 关于朴素贝叶斯 朴素贝叶斯算法是一个直观的方法,使用每个属性归属于某个类的概率来做预测.你可以使用这
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取
-
Python语言实现机器学习的K-近邻算法
写在前面 额...最近开始学习机器学习嘛,网上找到一本关于机器学习的书籍,名字叫做<机器学习实战>.很巧的是,这本书里的算法是用Python语言实现的,刚好之前我学过一些Python基础知识,所以这本书对于我来说,无疑是雪中送炭啊.接下来,我还是给大家讲讲实际的东西吧. 什么是K-近邻算法? 简单的说,K-近邻算法就是采用测量不同特征值之间的距离方法来进行分类.它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,