Hadoop2.8.1完全分布式环境搭建过程
前言
本文搭建了一个由三节点(master、slave1、slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性。
本文集群三个节点基于三台虚拟机进行搭建,节点安装的操作系统为Centos7(yum源),Hadoop版本选取为2.8.0。作者也是初次搭建Hadoop集群,其间遇到了很多问题,故希望通过该博客让读者避免。
实验过程
1、基础集群的搭建
目的:获得一个可以互相通信的三节点集群
下载并安装VMware WorkStation Pro(支持快照,方便对集群进行保存)下载地址,产品激活序列号网上自行查找。
下载CentOS7镜像,下载地址。
使用VMware安装master节点(稍后其他两个节点可以通过复制master节点的虚拟机文件创建)。
三个节点存储均为30G默认安装,master节点内存大小为2GB,双核,slave节点内存大小1GB,单核
2、集群网络配置
目的:为了使得集群既能互相之间进行通信,又能够进行外网通信,需要为节点添加两张网卡(可以在虚拟机启动的时候另外添加一张网卡,即网络适配器,也可以在节点创建之后,在VMware设置中添加)。
两张网卡上网方式均采用桥接模式,外网IP设置为自动获取(通过此网卡进行外网访问,配置应该按照你当前主机的上网方式进行合理配置,如果不与主机通信的话可以采用NAT上网方式,这样选取默认配置就行),内网IP设置为静态IP。
本文中的集群网络环境配置如下:
master内网IP:192.168.1.100
slave1内网IP:192.168.1.101
slave2内网IP:192.168.1.102

设置完后,可以通过ping进行网络测试
注意事项:通过虚拟机文件复制,在VMware改名快速创建slave1和slave2后,可能会产生网卡MAC地址重复的问题,需要在VMware网卡设置中重新生成MAC,在虚拟机复制后需要更改内网网卡的IP。
每次虚拟机重启后,网卡可能没有自动启动,需要手动重新连接。
3、集群SSH免密登陆设置
目的:创建一个可以ssh免密登陆的集群
3.1 创建hadoop用户
为三个节点分别创建相同的用户hadoop,并在以后的操作均在此用户下操作,操作如下:
$su -
#useradd -m hadoop
#passwd hadoop
为hadoop添加sudo权限
#visudo
在该行root ALL=(ALL) ALL下添加hadoop ALL=(ALL) ALL保存后退出,并切换回hadoop用户
#su hadoop
注意事项:三个节点的用户名必须相同,不然以后会对后面ssh及hadoop集群搭建产生巨大影响
3.2 hosts文件设置
为了不直接使用IP,可以通过设置hosts文件达到ssh slave1这样的的效果(三个节点设置相同)
$sudo vim /etc/hosts
在文件尾部添加如下行,保存后退出:
192.168.1.100 master
192.168.1.101 slave1
192.168.1.102 slave2
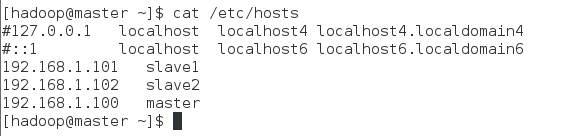
注意事项:不要在127.0.0.1后面添加主机名,如果加了master,会造成后面hadoop的一个很坑的问题,在slave节点应该解析出masterIP的时候解析出127.0.0.1,造成hadoop搭建完全正确,但是系统显示可用节点一直为0。
3.3 hostname修改
centos7默认的hostname是localhost,为了方便将每个节点hostname分别修改为master、slave1、slave2(以下以master节点为例)。
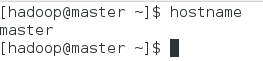
$sudo hostnamectl set-hostname master
重启terminal,然后查看:$hostname
3.3 ssh设置
设置master节点和两个slave节点之间的双向ssh免密通信,下面以master节点ssh免密登陆slave节点设置为例,进行ssh设置介绍(以下操作均在master机器上操作):
首先生成master的rsa密钥:$ssh-keygen -t rsa
设置全部采用默认值进行回车
将生成的rsa追加写入授权文件:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
给授权文件权限:$chmod 600 ~/.ssh/authorized_keys
进行本机ssh测试:$ssh maste r正常免密登陆后所有的ssh第一次都需要密码,此后都不需要密码
将master上的authorized_keys传到slave1
sudo scp ~/.ssh/id_rsa.pubhadoop@slave1:~/
登陆到slave1操作:$ssh slave1输入密码登陆
$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
修改authorized_keys权限:$chmod 600 ~/.ssh/authorized_keys
退出slave1:$exit
进行免密ssh登陆测试:$ssh slave1

4、java安装
目的:hadoop是基于Java的,所以要安装配置Java环境(三个节点均需要操作,以下以master节点为例)
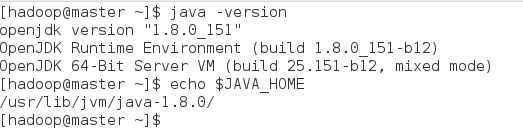
下载并安装:$sudo yum install java-1.8.0-openjdkjava-1.8.0-openjdk-devel
验证是否安装完成:$java -version
配置环境变量,修改~/.bashrc文件,添加行: export JAVA_HOME=/usr/lib/jvm/java-1.8.0
使环境变量生效:$source ~/.bashrc
5、Hadoop安装配置
目的:获得正确配置的完全分布式Hadoop集群(以下操作均在master主机下操作)
安装前三台节点都需要需要关闭防火墙和selinux
$sudo systemctl stop firewalld.service $sudo systemctl disable firewalld.service $sudo vim /usr/sbin/sestatus
将SELinux status参数设定为关闭状态
SELinux status: disabled
5.1 Hadoop安装
首先在master节点进行hadoop安装配置,之后使用scp传到slave1和slave2。
下载Hadoop二进制源码至master,下载地址,并将其解压在~/ 主目录下
$tar -zxvf ~/hadoop-2.8.1.tar.gz -C ~/
$mv~/hadoop-2.8.1/* ~/hadoop/
注意事项:hadoop有32位和64位之分,官网默认二进制安装文件是32位的,但是本文操作系统是64位,会在后面hadoop集群使用中产生一个warning但是不影响正常操作。
5.2 Hadoop的master节点配置
配置hadoop的配置文件core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves(都在~/hadoop/etc/hadoop文件夹下)
$cd ~/hadoop/etc/hadoop
$vimcore-site.xml其他文件相同,以下为配置文件内容:
1.core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> </property> </configuration>
2.hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> </configuration>
3.mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4.yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
5.slaves
slave1
slave2
5.3 Hadoop的其他节点配置
此步骤的所有操作仍然是在master节点上操作,以master节点在slave1节点上配置为例
复制hadoop文件至slave1:$scp -r ~/hadoop hadoop@slave1:~/
5.4 Hadoop环境变量配置
配置环境变量,修改~/.bashrc文件,添加行(每个节点都需要此步操作,以master节点为例):
#hadoop environment vars export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使环境变量生效:$source ~/.bashrc

6、Hadoop启动
格式化namenode:$hadoop namenode -format
启动hadoop:$start-all.sh
master节点查看启动情况:$jps
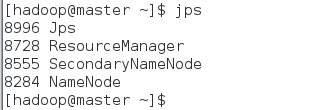
slave1节点查看启动情况:$jps
slave2节点查看启动情况:$jps
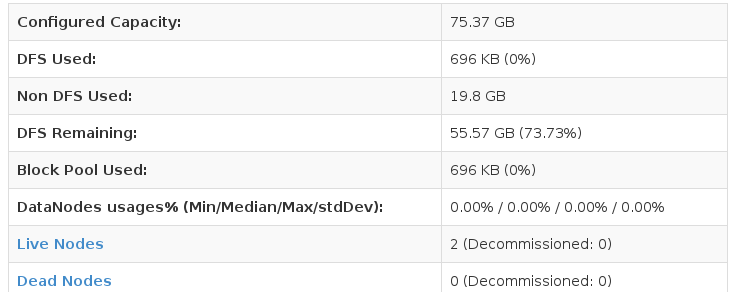
Web浏览器输入127.0.0.1:50070,查看管理界面

7、Hadoop集群测试
目的:验证当前hadoop集群正确安装配置
本次测试用例为利用MapReduce实现wordcount程序
生成文件testWordCount:$echo "My name is Xie PengCheng. This is a example program called WordCount, run by Xie PengCheng " >>testWordCount
创建hadoop文件夹wordCountInput:$hadoop fs -mkdir /wordCountInput
将文件testWordCount上传至wordCountInput文件夹:$hadoop fs -puttestWordCount/wordCountInput
执行wordcount程序,并将结果放入wordCountOutput文件夹:$hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /wordCountInput /wordCountOutput
注意事项:/wordCountOutput文件夹必须是没有创建过的文件夹
查看生成文件夹下的文件:$hadoop fs -ls /wordCountOutput

在output/part-r-00000可以看到程序执行结果:$hadoop fs -cat /wordCountOutpart-r-00000

总结
以上所述是小编给大家介绍的Hadoop2.8.1完全分布式环境搭建过程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

基于CentOS的Hadoop分布式环境的搭建开发
首先,要说明的一点的是,我不想重复发明轮子.如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录. 其次,我要说的是我也是新手,对于Hadoop也不是很熟悉.但是就是想实际搭建好环境,看看他的庐山真面目,还好,还好,最好看到了.当运行wordcount词频统计的时候,实在是感叹hadoop已经把分布式做的如此之好,即使没有分布式相关经验的人,也只需要做一些配置即可运行分布式集群环境. 好了,言归真传. 在搭建Hadoop环境中你要知道的一些事儿: 1.hadoop运行于
-
详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群 在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了. 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装. 2:在centos7中安装docker,docker的版本为1.8.2 安装步骤如下: <1>安装制定版本的docker yum install -y docker-1.8.2-10.el7.centos <2>安装的时候可能会报错,需要删除这个依赖 r
-
Hadoop1.2中配置伪分布式的实例
1.设置ssh 安装ssh相关软件包: 复制代码 代码如下: sudo apt-get install openssh-client openssh-server 然后使用下面两个命令之一启动/关闭sshd: 复制代码 代码如下: sudo /etc/init.d/ssh start|stopsudo service ssh start|stop 若成功启动sshd,我们能看到如下类似结果: 复制代码 代码如下: $ ps -e | grep ssh 2766 ? 00:00:00
-
Hadoop单机版和全分布式(集群)安装
Hadoop,分布式的大数据存储和计算, 免费开源!有Linux基础的同学安装起来比较顺风顺水,写几个配置文件就可以启动了,本人菜鸟,所以写的比较详细.为了方便,本人使用三台的虚拟机系统是Ubuntu-12.设置虚拟机的网络连接使用桥接方式,这样在一个局域网方便调试.单机和集群安装相差不多,先说单机然后补充集群的几点配置. 第一步,先安装工具软件编辑器:vim 复制代码 代码如下: sudo apt-get install vim ssh服务器: openssh,先安装ssh是为了使用远程终端工
-
Java访问Hadoop分布式文件系统HDFS的配置说明
配置文件 m103替换为hdfs服务地址. 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDFS,文件无法创建.读取. <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <co
-
详解VMware12使用三台虚拟机Ubuntu16.04系统搭建hadoop-2.7.1+hbase-1.2.4(完全分布式)
初衷 首先说明一下既然网上有那么多教程为什么要还要写这样一个安装教程呢?网上教程虽然多,但是有些教程比较老,许多教程忽略许多安装过程中的细节,比如添加用户的权限,文件权限,小编在安装过程遇到许多这样的问题所以想写一篇完整的教程,希望对初学Hadoop的人有一个直观的了解,我们接触真集群的机会比较少,虚拟机是个不错的选择,可以基本完全模拟真实的情况,前提是你的电脑要配置相对较好不然跑起来都想死,废话不多说. 环境说明 本文使用VMware® Workstation 12 Pro虚拟机创建并安装三台
-
Hadoop 2.x伪分布式环境搭建详细步骤
本文以图文结合的方式详细介绍了Hadoop 2.x伪分布式环境搭建的全过程,供大家参考,具体内容如下 1.修改hadoop-env.sh.yarn-env.sh.mapred-env.sh 方法:使用notepad++(beifeng用户)打开这三个文件 添加代码:export JAVA_HOME=/opt/modules/jdk1.7.0_67 2.修改core-site.xml.hdfs-site.xml.yarn-site.xml.mapred-site.xml配置文件 1)修改core-
-
用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
MapReduce与HDFS简介 什么是Hadoop? Google为自己的业务需要提出了编程模型MapReduce和分布式文件系统Google File System,并发布了相关论文(可在Google Research的网站上获得: GFS . MapReduce). Doug Cutting和Mike Cafarella在开发搜索引擎Nutch时对这两篇论文做了自己的实现,即同名的MapReduce和HDFS,合起来就是Hadoop. MapReduce的Data flow如下图,原始数据
-
Hadoop2.8.1完全分布式环境搭建过程
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三个节点基于三台虚拟机进行搭建,节点安装的操作系统为Centos7(yum源),Hadoop版本选取为2.8.0.作者也是初次搭建Hadoop集群,其间遇到了很多问题,故希望通过该博客让读者避免. 实验过程 1.基础集群的搭建 目的:获得一个可以互相通信的三节点集群 下载并安装VMware WorkS
-
Hadoop-3.1.2完全分布式环境搭建过程图文详解(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3.1.2.tar.gz ◦ jdk-8u221-linux-x64.tar.gz(Linux环境下的JDK) ◦ CertOS-7-x86_64-DVD-1810.iso(CentOS镜像) ◦工具:WinSCP(用于上传文件到虚拟机),SecureCRTP ortable(用于操作虚拟机,可复制粘
-
hadoop分布式环境搭建过程
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中. danieldu@daniels-MacBook-Pro-857 ~/Downloads scp jdk-8u121-linux-x64.tar.gz root@hadoop100:/opt/software root@hadoop100's password: danieldu@daniels
-
详解Hadoop 运行环境搭建过程
一,集群搭建步骤 1.先在一台虚拟机配置jdk,hadoop 2.克隆 3.修改网络等相关配置 当我们使用虚拟机时,可能自然而然的会想上面的步骤一样先搭建一台虚拟机,做好相关配置,然后进行克隆,继而修改一些网络配置来搭建集群,但是在生产过程中是买好的服务器,不存在克隆这一说,所以在此采用的步骤是: 1.建立一台虚拟机(仅带jdk安装包) 2.克隆 3.修改网络等相关配置 4.配置第一个hadoop节点,编写集群分发脚本使其他虚拟机完成配置 二,具体搭建过程 这里使用三台虚拟机来完成集群搭建,ha
-
Hadoop环境搭建过程中遇到的问题及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.ssh目录下查看是否有公钥私钥文件authorized_keys.id_rsa.id_rsa.pub 2)如果没有公钥私钥文件,则执行ssh-keygen -t rsa生成秘钥(master主机和slave主机都需要执行) 3)公钥私钥文件生成完成后,执行cat id_rsa.pub >> auth
-
初学者AngularJS的环境搭建过程
AngularJS是什么? AngularJS是一个开源Web应用程序框架.它最初是由MISKO Hevery和Adam Abrons于2009年开发.现在是由谷歌维护 AngularJS特性 AngularJS是一个功能强大的基于JavaScript开发框架用于创建富互联网应用(RIA). AngulajJS为开发者提供的选项(使用JavaScript)在一个干净的MVC(模型 - 视图 - 控制器)的方式来编写客户端应用程序. AngularJS写的应用都是跨浏览器兼容.AngularJS使
-
阿里云go开发环境搭建过程
开通了一个阿里云来玩,记录一下环境搭建的过程 运行环境 ECS Ubuntu 16.04 64位 过程 #切换到安装文件夹 cd /usr/local #下载go #由于墙的原因,直接下载官方的可能会失败,这里用国内一个论坛的 wget https://dl.gocn.io/golang/1.8.4/go1.8.4.linux-amd64.tar.gz #解压 tar -zxvf go1.8.4.linux-amd64.tar.gz #创建工作目录 mkdir -p GOPATH goProje
-
浅析SpringBoot及环境搭建过程
什么是SpringBoot Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. SpringBoot特性 独立运行的Spring项目 Spring Boot可以以jar包的形式来运行,运行一个Spring Boot项目我们只需要通过Java -jar xx.jar类运行.非常方便. 内嵌Servlet容器 Spring Boot可以内嵌Tomcat,这
-
vue.js多页面开发环境搭建过程
利用 vue-cli 搭建的项目大都是单页面应用项目,对于简单的项目,单页面就能满足要求.但对于有多个子项目的应用,如果创建多个单页面,显示有点重复,特别是 node_modules 会有多份相同的.如果全部放到单页面项目下,又显得有点乱,这时候通过改造 vue-cli 搭建的项目为多页面,就是一个比较好的解决方法. 如何改造单页面 vue.js 项目为多页面项目?下面是这次改造的具体过程. 一.创建单页面 vue.js 项目 这里直接使用官方提供的脚手架 vue-cli3 创建,具体的过程请