C语言数据结构 链表与归并排序实例详解
C语言数据结构 链表与归并排序实例详解
归并排序适合于对链表进行原址排序,即只改变指针的连接方式,不交换链表结点的内容。
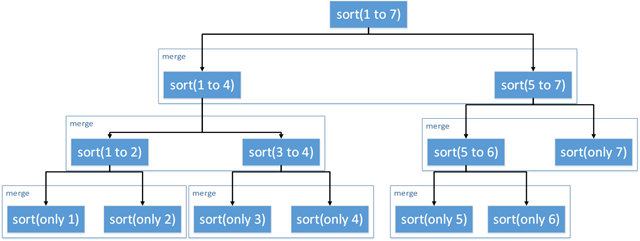
归并排序的基本思想是分治法:先把一个链表分割成只有一个节点的链表,然后按照一定顺序、自底向上合并相邻的两个链表。
只要保证各种大小的子链表是有序的,那么最后返回的链表就一定是有序的.
归并排序分为分割和合并两个子过程。分割是用递归的方法,把链表对半分割成两个子链表;合并是在递归返回(回朔)的时候,把两个有序链表合并成一个有序链表。
(注意:只有一个节点的链表一定是有序的)
这里sort过程就是分割过程;merge过程就是合并且排序的过程
说到分割链表,那么问题来了:链表不是随机访问的,我怎么知道分割点在哪里?一个宝贵的经验就是:维护两个指针,一快一慢。快指针每次后移两个单位,慢指针每次只移动一个单位。当快指针移动到tail或者最后一个有效节点时,慢指针就指向了中间的节点。
sort过程:
Node* sort (Node* beg)
{
if(beg==tail || beg->next==tail) return beg;
Node* a = beg; Node* b = beg->next;
while(b!=tail && b->next != tail)
{
a = a->next; b = b->next->next;
}
b = a->next; //the beginning of right part
a->next = tail; //the end of left part
return merge(sort(beg), sort(b));
}
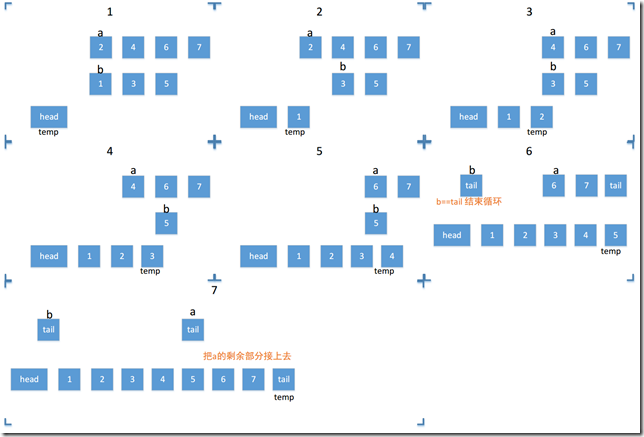
把链表分割之后就要合并。merge操作传入的参数是两个有序链表,返回的是合并后的有序的链表。两个有序链表简单拼接之后不一定是有序的,需要对每一个元素重排。这个重排的过程是从两个链表各自最小(最大)元素开始,谁小(大)就把谁放到新的链表里。
Node* LinkedList<T>::merge(Node* a, Node* b)
{
Node dummy = Node();
Node* head = &dummy;
// temp是正在合并的表的节点
Node* temp = head;
while(a!=tail && b!=tail) //逐个比较链表a和链表b的每个元素
{
if(a->data <= b->data)
{
// 如果a比b小, 那么当前结点的后继就是a
temp->next = a;
// 把当前节点移向后继
temp = a;
// a后移
a = a->next;
}
else
{
temp->next = b;
temp = b;
b = b->next;
}
// 如果原表a已经排完,那么新表后面就放b的剩余元素
// 否则仍然以a为标准和b进行比较
temp->next = (a==tail) ? b : a;
}
return head->next;
}
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
java数据结构排序算法之归并排序详解
本文实例讲述了java数据结构排序算法之归并排序.分享给大家供大家参考,具体如下: 在前面说的那几种排序都是将一组记录按关键字大小排成一个有序的序列,而归并排序的思想是:基于合并,将两个或两个以上有序表合并成一个新的有序表 归并排序算法:假设初始序列含有n个记录,首先将这n个记录看成n个有序的子序列,每个子序列长度为1,然后两两归并,得到n/2个长度为2(n为奇数的时候,最后一个序列的长度为1)的有序子序列.在此基础上,再对长度为2的有序子序列进行亮亮归并,得到若干个长度为4的有序子序列.如此重
-

C语言中数据结构之链表归并排序实例代码
C语言中数据结构之链表归并排序实例代码 问题 设有两个无头结点的单链表,头指针分别为ha,hb,链中有数据域data,链域next,两链表的数据都按递增排序存放,现要求将hb表归到ha表中,且归并后ha仍递增序,归并中ha表中已有的数据若hb中也有,则hb中的数据不归并到ha中,hb的链表在算法中不允许破坏. 源程序 #include <stdio.h> #include<stdlib.h> #define N1 6 /*链表La的长度*/ #define N2 6 /*链表Lb的
-
数据结构之归并排序的实例详解
归并排序 基本思想 归并排序是建立在二路归并和分治法的基础上的一个高效排序算法,将已有序的子序列合并,得到完全有序的序列:即先使每个子序 列有序,再使子序列段间有序.若将两个有序表合并成一个有序表,称为二路归并. 将待排序序列R[0...n-1]看成是n个长度为1的有序序列,将相邻的有序表成对归并,得到n/2个长度为2的有序表:将这些有序序列 再次归并,得到n/4个长度为4的有序序列:如此反复进行下去,最后得到一个长度为n的有序序列.所以呢,我们总结一下归并排序 其实就只有两步:
-
C语言数据结构 链表与归并排序实例详解
C语言数据结构 链表与归并排序实例详解 归并排序适合于对链表进行原址排序,即只改变指针的连接方式,不交换链表结点的内容. 归并排序的基本思想是分治法:先把一个链表分割成只有一个节点的链表,然后按照一定顺序.自底向上合并相邻的两个链表. 只要保证各种大小的子链表是有序的,那么最后返回的链表就一定是有序的. 归并排序分为分割和合并两个子过程.分割是用递归的方法,把链表对半分割成两个子链表:合并是在递归返回(回朔)的时候,把两个有序链表合并成一个有序链表. (注意:只有一个节点的链表一定是有序的) 这
-
C语言 数据结构之中序二叉树实例详解
C语言数据结构 中序二叉树 前言: 线索二叉树主要是为了解决查找结点的线性前驱与后继不方便的难题.它只增加了两个标志性域,就可以充分利用没有左或右孩子的结点的左右孩子的存储空间来存放该结点的线性前驱结点与线性后继结点.两个标志性域所占用的空间是极少的,所有充分利用了二叉链表中空闲存的储空间. 要实现线索二叉树,就必须定义二叉链表结点数据结构如下(定义请看代码): left leftTag data rightTag right 说明: 1. leftTag=false时,表示left
-
C语言数据结构之 折半查找实例详解
数据结构 折半查找 实例代码: /* 名称:折半查找 语言:数据结构C语言版 编译环境:VC++ 6.0 日期: 2014-3-26 */ #include <stdio.h> #include <malloc.h> #include <windows.h> #define N 11 // 数据元素个数 typedef int KeyType; // 设关键字域为整型 typedef struct // 数据元素类型 { KeyType key; // 关键字域 int
-
C语言复杂链表的复制实例详解
目录 一.题目描述 示例1: 示例2: 示例3: 示例4: 二.思路分析 三.整体代码 总结 一.题目描述 请实现 copyRandomList 函数,复制一个复杂链表.在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null. 示例1: 输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]] 示例2: 输
-
C语言树状数组的实例详解
C语言树状数组的实例详解 最近学了树状数组,给我的感觉就是 这个数据结构好神奇啊^_^ 首先她的常数比线段树小,其次她的实现复杂度也远低于线段树 (并没有黑线段树的意思=-=) 所以熟练掌握她是非常有必要的.. 关于树状数组的基础知识与原理网上一搜一大堆,我就不赘述了,就谈一些树状数组的应用好了 1,单点修改,求区间和 #define lowbit(x) (x&-x) // 设 x 的末尾零的个数为 y , 则 lowbit(x) == 2^y void Update(int i,int v)
-
数据结构串的操作实例详解
数据结构串的操作实例详解 串是一种特殊的线性表,它的每个结点是一个字符,所以串也称作字符串. 关于串的操作主要有求串长,串复制,串连接,求子串,串插入,串删除,子串定位等.串的操作也是C语言笔试中常考的一部分. 下面的代码实现了串的主要操作. #include <stdio.h> #include <stdlib.h> #define MAXSIZE 20 char *String_Create(); //创建串 int String_Length(char *s); //求串长
-
c语言数据结构之栈和队列详解(Stack&Queue)
目录 简介 栈 一.栈的基本概念 1.栈的定义 2.栈的常见基本操作 二.栈的顺序存储结构 1.栈的顺序存储 2.顺序栈的基本算法 3.共享栈(两栈共享空间) 三.栈的链式存储结构 1.链栈 2.链栈的基本算法 3.性能分析 四.栈的应用——递归 1.递归的定义 2.斐波那契数列 五.栈的应用——四则运算表达式求值 1.后缀表达式计算结果 2.中缀表达式转后缀表达式 队列 一.队列的基本概念 1.队列的定义 2.队列的常见基本操作 二.队列的顺序存储结构 1.顺序队列 2.循环队列 3.循环队列
-
redis数据结构之intset的实例详解
redis数据结构之intset的实例详解 在redis中,intset主要用于保存整数值,由于其底层是使用数组来保存数据的,因而当对集合进行数据添加时需要对集合进行扩容和迁移操作,因而也只有在数据量不大时redis才使用该数据结构来保存整数集合.其具体的底层数据结构如下: typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; }
-
Kotlin 语言中调用 JavaScript 方法实例详解
Kotlin 语言中调用 JavaScript 方法实例详解 Kotlin 已被设计为能够与 Java 平台轻松互操作.它将 Java 类视为 Kotlin 类,并且 Java 也将 Kotlin 类视为 Java 类.但是,JavaScript 是一种动态类型语言,这意味着它不会在编译期检查类型.你可以通过动态类型在 Kotlin 中自由地与 JavaScript 交流,但是如果你想要 Kotlin 类型系统的全部威力 ,你可以为 JavaScript 库创建 Kotlin 头文件. 内联 J
-
数据结构 栈的操作实例详解
数据结构 栈的操作实例详解 说明: 往前学习数据结构,想运行一个完整的顺序栈的程序都运行不了,因为书上给的都是一部分一部分的算法,并没有提供一个完整可运行的程序,听了实验课,自己折腾了一下,总算可以写一个比较完整的顺序栈操作的小程序,对于栈也慢慢开始有了感觉.下面我会把整个程序拆开来做说明,只要把这些代码放在一个文件中,用编译器就可以直接编译运行了. 一.实现 1.程序功能 关于栈操作的经典程序,首当要提及进制数转换的问题,利用栈的操作,就可以十分快速地完成数的进制转换. 2.预定义.头文件导入