Windows下Node爬虫神器Puppeteer安装记
对于爬虫,相信大家并不陌生。当希望得到一些网站的数据并做一些有趣的事时,必不可少要爬取网页,用到爬虫。而目前网络上也有很多爬虫的教程资料,不过又尤以python语言居多。想来自己是做web的,就希望以js的方式解决问题,于是希望利用nodejs。今天介绍一款node的爬虫利器:Puppeteer。
Puppeteer正如其名“木偶”,它允许我们像牵线木偶一样操纵它。它是一个建立在DevTools协议上的提供控制无头Chrome或Chromium的高级接口的Node库。官网上对其应用举了几个例子:
- - 生成网页的截屏(目前仅支持支持jpeg、png格式)和pdf文件
- - 爬取SPA和异步渲染网页
- - 自动表单提交、键盘输入、UI测试等
- - 创建最新的自动测试环境,也就是说可以使用最新的浏览器特性
- - 捕获站点的时间线以帮助分析性能问题
Puppeteer本质上是一个headless chrome。无头浏览器,相信如果大家做爬虫肯定有所耳闻。其实就是一个没有UI界面的浏览器,它包含了浏览器应该具有的功能,通常做web测试用,不过做爬虫也是没问题的。PhantomJS就提供这样的功能,基于webkit内核,已经有好几年历史了。不过因为Puppeteer有背景(谷歌Chrome团队开发),我最后还是选择了Puppeteer。它们之间的不同点是后者只关注于Chromium或Chrome。这也导致了最坑的一点是总是绑定最新版本的Chromium。
上面说到Puppeteer会绑定最新版本的Chromium,这意味着每次使用npm i puppeteer安装使用它时都会下载最新版本的Chromium,该版本在Windows上大约是130Mb。本来下载npm包就很不易,还要下载一个一百多兆的东西更是难上加难了。当然可以使用cnpm,下图是我下载的一个界面。可以看到下载了55分钟,这固然有我网络慢的问题,但是能不下载Chromium就尽量不下载了吧。

官网讲到可以通过设置环境变量或配置npm config的方式避免下载。但设置环境变量我一直没有成功,所以接下来讲解配置npm config的方式。PUPPETEER_SKIP_CHROMIUM_DOWNLOAD参数可以避免下载,所以可以在安装puppeteer之前使用下面的命令:
npm config set puppeteer_skip_chromium_download = 1
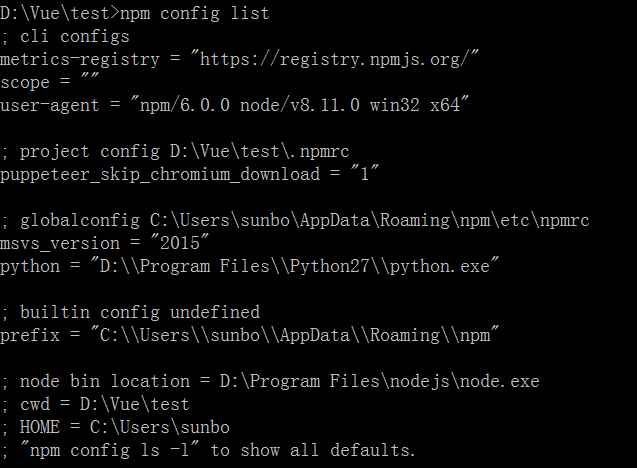
但这样每次都要敲这个命令总不是办法,所以可以将其写入.npmrc文件中。npm官网讲到有四个影响npm配置的文件,分别是:项目配置文件(/path/to/my/project/.npmrc)、用户配置文件 (~/.npmrc)、全局配置文件($PREFIX/etc/npmrc)、npm内置配置文件(/path/to/npm/npmrc)。可以使用npm config list来查看影响npm的配置文件有哪些。不过这里面有个问题,就是上面的介绍文档是针对npm最新的6.0版本的。而一般随nodejs下载的npm版本没有这么高,只是npm4.x,导致项目中的配置文件不生效。可以从下面两张图片看到两种版本的npm的配置文件的不同(上面一张:npm4.0.2,下面一张npm6.0),可以看到后者多出一个project config列表。

身为强迫症的我,当然希望直接在项目目录中更改配置文件了,所以使用下面的命令安装最新版本的npm:
npm install npm@latest -g
然后在项目目录下建立.npmrc文件,输入以下配置命令:
puppeteer_skip_chromium_download = 1
这样配置之后,就可以跳过下载了,如图所示:

接着就可以使用它了,以官网的例子为例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
以为这样就完了吗?不,虽然跳过下载的事情解决了,但是因为没有下载会导致puppeteer无法得知要使用的Chrome或Chromium在哪里,所以还需要指明启动路径。修改一下:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
// headless: false,//不使用无头chrome模式
executablePath: 'C:\\Users\\sunbo\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe',//path to your chrome
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
更改executablePath参数指向你本地chrome所在目录,注意一定要指向chrome.exe才能正常使用。headless参数也是挺有趣的,如果其值为false,就会真的为我们启动一个chrome进程,让我们可以可视化整个程序运行的过程。
好了,安装配置好就可以尽情享受Puppeteer带给我们的美好世界了。最后说一点,官网例子使用async/await和promise,所以有必要了解这些异步知识,这些东西运用好,简直打开了异步编程的新世界。祝好运!!!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Puppeteer环境搭建的详细步骤
简介 Puppeteer是Google开发并开源的一款工具,可用代码驱动浏览器操作. 由于诸多优秀的特性,Puppeteer常被用在爬虫与自动化测试上.详细介绍参见官方 README. Puppeteer本身是个NodeJS的库,自动化脚本也需要使用NodeJS编写,如果对JS不了解建议先学习JavaScript基础语法,或者使用Selenium等其他工具去实现. 对于一个陌生的工具,应当先检查是否适合自己,再去尝试使用,切莫盲目从众. Puppeteer 用处 利用网页生成PDF.图片 爬取S
-
puppeteer库入门初探
puppeteer 是一个Chrome官方出品的headless Chrome node库.它提供了一系列的API, 可以在无UI的情况下调用Chrome的功能, 适用于爬虫.自动化处理等各种场景 根据官网上描述,puppeteer 具有以下作用: 生成页面截图和 PDF 自动化表单提交.UI 测试.键盘输入等 创建一个最新的自动化测试环境.使用最新的 JavaScript 和浏览器功能,可以直接在最新版本的 Chrome 中运行测试. 捕获站点的时间线跟踪,以帮助诊断性能问题. 爬取 SPA
-

node基于puppeteer模拟登录抓取页面的实现
关于热图 在网站分析行业中,网站热图能够很好的反应用户在网站的操作行为,具体分析用户的喜好,对网站进行针对性的优化,一个热图的例子(来源于ptengine) 上图中能很清晰的看到用户关注点在那,我们不关注产品中热图的功能如何,本篇文章就热图的实现做一下简单的分析和总结. 热图主流的实现方式 一般实现热图显示需要经过如下阶段: 1.获取网站页面 2.获取经过处理后的用户数据 3.绘制热图 本篇主要聚焦于阶段1来详细的介绍一下主流的在热图中获取网站页面的实现方式 4.使用iframe直接嵌入用户网
-
爬虫利器Puppeteer实战
Puppeteer 介绍 Puppeteer 翻译是操纵木偶的人,利用这个工具,我们能做一个操纵页面的人. Puppeteer 是一个 Nodejs 的库,支持调用 Chrome的API来操纵Web ,相比较 Selenium 或是 PhantomJs ,它最大的特点就是它的操作 Dom 可以完全在内存中进行模拟既在 V8 引擎中处理而不打开浏览器,而且关键是这个是Chrome团队在维护,会拥有更好的兼容性和前景. Puppeteer 用处 利用网页生成PDF.图片 爬取SPA应用,并生成预渲染
-
详解Puppeteer 入门教程
1.Puppeteer 简介 Puppeteer 是一个node库,他提供了一组用来操纵Chrome的API, 通俗来说就是一个 headless chrome浏览器 (当然你也可以配置成有UI的,默认是没有的).既然是浏览器,那么我们手工可以在浏览器上做的事情 Puppeteer 都能胜任, 另外,Puppeteer 翻译成中文是"木偶"意思,所以听名字就知道,操纵起来很方便,你可以很方便的操纵她去实现: 1) 生成网页截图或者 PDF 2) 高级爬虫,可以爬取大量异步渲染内容的网页
-
使用puppeteer爬取网站并抓出404无效链接
检查网页无效链接 前言 自动化技术可以帮助我们做自动化测试,同样也可以帮助我们完成别的事情,比如今天我们要做的检查网站404无效链接. 原理 实现这样的功能,大致分为以下步骤: 1.打开官网首页,获取页面上所有的链接. 2.添加规则对这些链接过滤,把外链去掉. 3.遍历访问这些链接,打开打开其中的每一个链接,检查是否为404,如果是距离下来. 4.重复执行1,2,3.直到把整个网站所有的链接都遍历完. 准备 CukeTest 一款可以专业的编辑自动化脚本的工具.cuketest.com/ pup
-
详解Node使用Puppeteer完成一次复杂的爬虫
本文介绍了详解Node使用Puppeteer完成一次复杂的爬虫,分享给大家,具体如下: 架构图 Puppeteer架构图 Puppeteer 通过 devTools 与 browser 通信 Browser 一个可以拥有多个页面的浏览器(chroium)实例 Page 至少含有一个 Frame 的页面 Frame 至少还有一个用于执行 javascript 的执行环境,也可以拓展多个执行环境 前言 最近想要入手一台台式机,笔记本的i5在打开网页和vsc的时候有明显卡顿的情况,因此打算配1台 i7
-
Node Puppeteer图像识别实现百度指数爬虫的示例
之前看过一篇脑洞大开的文章,介绍了各个大厂的前端反爬虫技巧,但也正如此文所说,没有100%的反爬虫方法,本文介绍一种简单的方法,来绕过所有这些前端反爬虫手段. 下面的代码以百度指数为例,代码已经封装成一个百度指数爬虫node库: https://github.com/Coffcer/baidu-index-spider note: 请勿滥用爬虫给他人添麻烦 百度指数的反爬虫策略 观察百度指数的界面,指数数据是一个趋势图,当鼠标悬浮在某一天的时候,会触发两个请求,将结果显示在悬浮框里面: 按照常规
-
Puppeteer 爬取动态生成的网页实战
Puppeteer 相关介绍与安装不过多介绍,可通过以下链接进行学习 一.Puppeteer 开源地址 英文文档 中文社区 二.爬取动态网页 1. 需求 首先,了解下我们的需求: 爬取zoomcharts文档中 Net Chart 目录下所有访问连接对应的页面,并保存到本地 2. 研究 ZoomCharts 文档页面结构 首先,我们得研究透 ZoomCharts 页面如何加载,以及左侧导航的 DOM 树结构,才好进行下一步操作 页面首次加载 页面首次加载,左侧导航第一个目录 Introducti
-
Windows下Node爬虫神器Puppeteer安装记
对于爬虫,相信大家并不陌生.当希望得到一些网站的数据并做一些有趣的事时,必不可少要爬取网页,用到爬虫.而目前网络上也有很多爬虫的教程资料,不过又尤以python语言居多.想来自己是做web的,就希望以js的方式解决问题,于是希望利用nodejs.今天介绍一款node的爬虫利器:Puppeteer. Puppeteer正如其名"木偶",它允许我们像牵线木偶一样操纵它.它是一个建立在DevTools协议上的提供控制无头Chrome或Chromium的高级接口的Node库.官网上对其应用举了
-
解析windows下使用命令的方式安装mysql5.7的方法
解压zip压缩包,创建my.ini文件内容如下 这里注意一下sql_mode 这里写的是让MySQL使用习惯类似Oracle,具体哪些什么意思大家很容易百度查到 [mysql] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] sql_mode='NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO
-
Windows下PHP5和Apache的安装与配置
在这里以PHP5为例介绍一下Windows下Apache和PHP5的安装与配置方法. 一 下载安装程序 Apache可以从http://www.apache.org/dyn/closer.cgi/httpd/binaries/win32/下载 PHP可以从http://www.php.net下载. 二 安装程序 1.Apache的程序安装相对来说要较为的简单一些,我们从网站下来的是一个Windows下的安装程序,我们可以直接双击运行,这样我们就便利Apache在我们的电脑上安下家来了. 2.我们
-
Windows下mysql 8.0.11 安装教程
本文记录了Windows下mysql 8.0.11 安装教程,供大家参考,具体内容如下 1.官方下载mysql-8.0.11-winx64.zip 2.解压下载文件到安装目录 (当前 D:\mysql-8.0.11) 3.创建my.ini文件,(当前放置于D:\mysql-8.0.11目录下) [mysql] #设置mysql客户端默认字符集 default-character-set=utf8mb4 [mysqld] default_password_lifetime=0 #设置3307端口
-
windows下mysql 8.0.12安装步骤及基本使用教程
本文实例为大家分享了windows下mysql 8.0.12安装步骤及使用教程,供大家参考,具体内容如下 1.到官网下载下载SQL. (1.1)下载地址 打开网页后,点击go to download page如下图: (1.2)然后选择第二个'Windows (x86, 32-bit), MSI Installer',点击'download' (1.3)点击'No thanks, just start my download.'如下图 2.进行安装 (2.1)下载后,进行安装,进入license
-
Windows 下 MySQL 8.X 的安装教程
之前一直使用的是MySQL5.7,但由于MySQL增加了一些新特性,所以选择了更新. 下载MySQL 进入MySQL官网下载地址,选择Windows (x86, 64-bit), ZIP Archive. 下载地址:https://dev.mysql.com/downloads/mysql/ 可不用登录,直接跳过.下载过程也许有丢丢慢,耐心等待下. 下载完成后,直接解压到自己喜欢的位置即可. 卸载原有版本 如果之前有安装低版本的MySQL,需要先卸载之前的MySQL.如果没有安装过,可直接跳过该
-
Windows下Anaconda和PyCharm的安装与使用详解
1. Anaconda (下面都是一些口水话,可以稍微了解一下,不必过于斟酌��) Anaconda是将Python和许多常用的package(Python开源包)打包直接来使用的Python发行版本,支持Windows.Linux和macOS系统,并有一个conda(开源包packages和虚拟环境environment的管理系统)强大的执行工具. Anaconda的优点总结起来就八个字:省时省心.分析利器. 省时省心: Anaconda通过管理工具包.开发环境.Python版本,
-
Windows下CMake的下载与安装过程
一.CMake介绍 CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程).它能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake. 二.CMake的下载与安装 CMake下载链接:https://cmake.org/download/.下载最新稳定版即可(Latest Release): 下载完成后,单击“Next”按钮,在下图中勾选“I accept the terms in the L
-
Windows下mysql 8.0.28 安装配置方法图文教程
本文为大家分享了Windows下mysql 8.0.28 安装配置方法图文教程,供大家参考,具体内容如下 本教程只针对于8.0版本及以上的版本5.0版本不能以这方法安装 第一步:先去MySql官网下载8.0.28的安装包MySQL :: Download MySQL Community Server 或点击这里下载 推荐下载第一个 第二步:解压在本地盘符 创建my.ini配置文件,因为下面会有控制台创建data文件,所以在这里不要自己创建data文件夹,不要自己创建data文件夹,不要自己创建d
-
Windows下Node.js安装及环境配置方法
一.安装环境 1.本机系统:Windows 10 Pro(64位) 2.Node.js:v6.9.2LTS(64位) 二.安装Node.js步骤 1.下载对应你系统的Node.js版本:https://nodejs.org/en/download/ 2.选安装目录进行安装 3.环境配置 4.测试 三.前期准备 1.Node.js简介 简单的说 Node.js 就是运行在服务端的 JavaScript.Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境.Node