spark rdd转dataframe 写入mysql的实例讲解
dataframe是在spark1.3.0中推出的新的api,这让spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式易用的前提下,据说计算性能更还快了两倍。spark在离线批处理或者实时计算中都可以将rdd转成dataframe进而通过简单的sql命令对数据进行操作,对于熟悉sql的人来说在转换和过滤过程很方便,甚至可以有更高层次的应用,比如在实时这一块,传入kafka的topic名称和sql语句,后台读取自己配置好的内容字段反射成一个class并利用出入的sql对实时数据进行计算,这种情况下不会spark streaming的人也都可以方便的享受到实时计算带来的好处。
下面的示例为读取本地文件成rdd并隐式转换成dataframe对数据进行查询,最后以追加的形式写入mysql表的过程,scala代码示例如下
import java.sql.Timestamp
import org.apache.spark.sql.{SaveMode, SQLContext}
import org.apache.spark.{SparkContext, SparkConf}
object DataFrameSql {
case class memberbase(data_date:Long,memberid:String,createtime:Timestamp,sp:Int)extends Serializable{
override def toString: String="%d\t%s\t%s\t%d".format(data_date,memberid,createtime,sp)
}
def main(args:Array[String]): Unit ={
val conf = new SparkConf()
conf.setMaster("local[2]")
// ----------------------
//参数 spark.sql.autoBroadcastJoinThreshold 设置某个表是否应该做broadcast,默认10M,设置为-1表示禁用
//spark.sql.codegen 是否预编译sql成java字节码,长时间或频繁的sql有优化效果
// spark.sql.inMemoryColumnarStorage.batchSize 一次处理的row数量,小心oom
//spark.sql.inMemoryColumnarStorage.compressed 设置内存中的列存储是否需要压缩
// ----------------------
conf.set("spark.sql.shuffle.partitions","20") //默认partition是200个
conf.setAppName("dataframe test")
val sc = new SparkContext(conf)
val sqc = new SQLContext(sc)
val ac = sc.accumulator(0,"fail nums")
val file = sc.textFile("src\\main\\resources\\000000_0")
val log = file.map(lines => lines.split(" ")).filter(line =>
if (line.length != 4) { //做一个简单的过滤
ac.add(1)
false
} else true)
.map(line => memberbase(line(0).toLong, line(1),Timestamp.valueOf(line(2)), line(3).toInt))
// 方法一、利用隐式转换
import sqc.implicits._
val dftemp = log.toDF() // 转换
/*
方法二、利用createDataFrame方法,内部利用反射获取字段及其类型
val dftemp = sqc.createDataFrame(log)
*/
val df = dftemp.registerTempTable("memberbaseinfo")
/*val sqlcommand ="select date_format(createtime,'yyyy-MM')as mm,count(1) as nums " +
"from memberbaseinfo group by date_format(createtime,'yyyy-MM') " +
"order by nums desc,mm asc "*/
val sqlcommand="select * from memberbaseinfo"
val sel = sqc.sql(sqlcommand)
val prop = new java.util.Properties
prop.setProperty("user","etl")
prop.setProperty("password","xxx")
// 调用DataFrameWriter将数据写入mysql
val dataResult = sqc.sql(sqlcommand).write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/test","t_spark_dataframe_test",prop) // 表可以不存在
println(ac.name.get+" "+ac.value)
sc.stop()
}
}
上面代码textFile中的示例数据如下,数据来自hive,字段信息分别为 分区号、用户id、注册时间、第三方号
20160309 45386477 2012-06-12 20:13:15 901438 20160309 45390977 2012-06-12 22:38:06 901036 20160309 45446677 2012-06-14 21:57:39 901438 20160309 45464977 2012-06-15 13:42:55 901438 20160309 45572377 2012-06-18 14:55:03 902606 20160309 45620577 2012-06-20 00:21:09 902606 20160309 45628377 2012-06-20 10:48:05 901181 20160309 45628877 2012-06-20 11:10:15 902606 20160309 45667777 2012-06-21 18:58:34 902524 20160309 45680177 2012-06-22 01:49:55 20160309 45687077 2012-06-22 11:23:22 902607
这里注意字段类型映射,即case class类到dataframe映射,从官网的截图如下
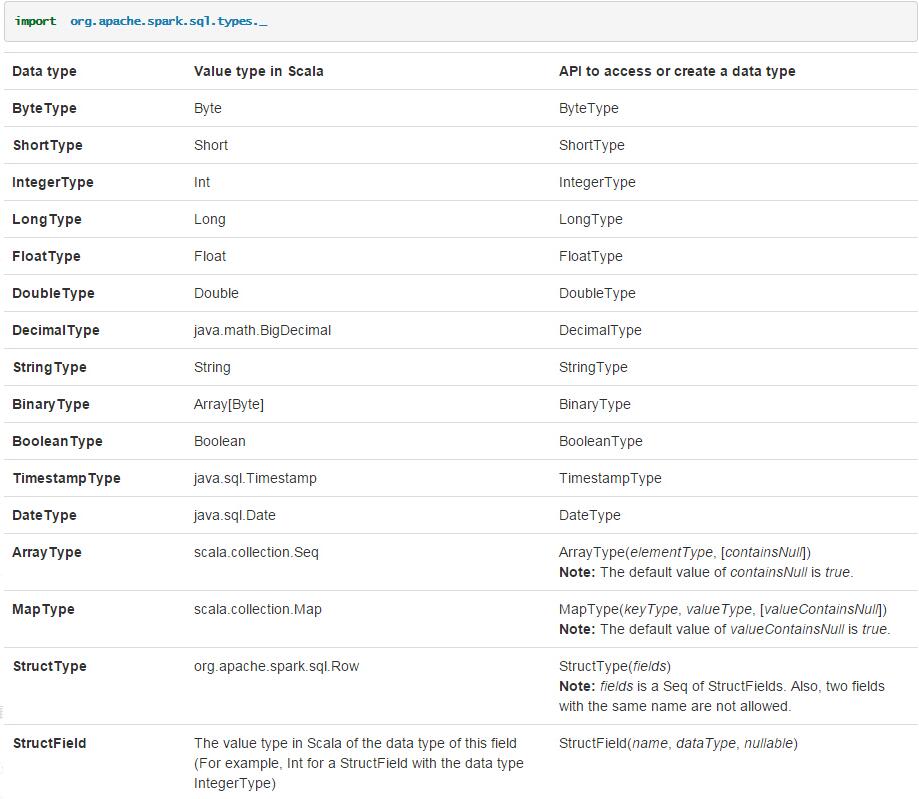
更多明细可以查看官方文档 Spark SQL and DataFrame Guide
以上这篇spark rdd转dataframe 写入mysql的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
spark: RDD与DataFrame之间的相互转换方法
DataFrame是一个组织成命名列的数据集.它在概念上等同于关系数据库中的表或R/Python中的数据框架,但其经过了优化.DataFrames可以从各种各样的源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD. DataFrame API 可以被Scala,Java,Python和R调用. 在Scala和Java中,DataFrame由Rows的数据集表示. 在Scala API中,DataFrame只是一个类型别名Dataset[Row].而在Java API中,用户需要
-
Java和scala实现 Spark RDD转换成DataFrame的两种方法小结
一:准备数据源 在项目下新建一个student.txt文件,里面的内容为: 1,zhangsan,20 2,lisi,21 3,wanger,19 4,fangliu,18 二:实现 Java版: 1.首先新建一个student的Bean对象,实现序列化和toString()方法,具体代码如下: package com.cxd.sql; import java.io.Serializable; @SuppressWarnings("serial") public class Stude
-
spark rdd转dataframe 写入mysql的实例讲解
dataframe是在spark1.3.0中推出的新的api,这让spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式易用的前提下,据说计算性能更还快了两倍.spark在离线批处理或者实时计算中都可以将rdd转成dataframe进而通过简单的sql命令对数据进行操作,对于熟悉sql的人来说在转换和过滤过程很方便,甚至可以有更高层次的应用,比如在实时这一块,传入kafka的topic名称和sql语句,后台读取自己配置好的内容字段反射成一个class并利用出入的sql对实时数据进行
-
php使用flock阻塞写入文件和非阻塞写入文件的实例讲解
阻塞写入代码:(所有程序会等待上次程序执行结束才会执行,30秒会超时) <?php $file = fopen("test.txt","w+"); $t1 = microtime(TRUE); if (flock($file,LOCK_EX)) { sleep(10); fwrite($file,"Write something"); flock($file,LOCK_UN); echo "Ok locking file!&quo
-
linux安装redis和mysql的实例讲解
linux环境下安装redis和mysql 安装redis(版本3.2.10): 下载地址:https://redis.io/download,这里我下载3.2.10 // 解压 tar zxvf redis-3.2.10.tar.gz cd redis-3.2.10 make cd src make install // 设置redis服务后台启动 cd .. vi redis.conf 设置daemonize yes // 安装redis服务 mkdir -p的意思是递归创建 即同时创建/u
-

python 3.6 +pyMysql 操作mysql数据库(实例讲解)
版本信息:python:3.6 mysql:5.7 pyMysql:0.7.11 ################################################################# #author: 陈月白 #_blogs: http://www.cnblogs.com/chenyuebai/ ################################################################# # -*- coding: utf-8
-
Spark SQL数据加载和保存实例讲解
一.前置知识详解 Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作, Load:可以创建DataFrame, Save:把DataFrame中的数据保存到文件或者说与具体的格式来指明我们要读取的文件的类型以及与具体的格式来指出我们要输出的文件是什么类型. 二.Spark SQL读写数据代码实战 import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD;
-
python测试mysql写入性能完整实例
本文主要研究的是python测试mysql写入性能,分享了一则完整代码,具体介绍如下. 测试环境: (1) 阿里云服务器centos 6.5 (2) 2G内存 (3) 普通硬盘 (4) mysql 5.1.73 数据库存储引擎为 InnoDB (5) python 2.7 (6) 客户端模块 mysql.connector 测试方法: (1) 普通写入 (2) 批量写入 (3) 事务加批量写入 普通写入: def ordinary_insert(count): sql = "insert int
-
python通过elixir包操作mysql数据库实例代码
本文研究的主要是python通过elixir包操作mysql数据库的相关实例,具体如下. python操作数据库有很多方法,下面介绍elixir来操作数据库.elixir是对sqlalchemy lib的一个封装,classes和tables是一一对应的,能够一步定义classes,tables和mappers,支持定义多个primary key. 定义model.py from elixir import sqlalchemy from elixir import * engine =sqla
-
pandas 对series和dataframe进行排序的实例
本问主要写根据索引或者值对series和dataframe进行排序的实例讲解 代码: #coding=utf-8 import pandas as pd import numpy as np #以下实现排序功能. series=pd.Series([3,4,1,6],index=['b','a','d','c']) frame=pd.DataFrame([[2,4,1,5],[3,1,4,5],[5,1,4,2]],columns=['b','a','d','c'],index=['one','