在python环境下运用kafka对数据进行实时传输的方法
背景:
为了满足各个平台间数据的传输,以及能确保历史性和实时性。先选用kafka作为不同平台数据传输的中转站,来满足我们对跨平台数据发送与接收的需要。
kafka简介:
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
总之:kafka做为中转站有以下功能:
1.生产者(产生数据或者说是从外部接收数据)
2.消费着(将接收到的数据转花为自己所需用的格式)
环境:
1.python3.5.x
2.kafka1.4.3
3.pandas
准备开始:
1.kafka的安装
pip install kafka-python
2.检验kafka是否安装成功
3.pandas的安装
pip install pandas
4.kafka数据的传输
直接撸代码:
# -*- coding: utf-8 -*-
'''
@author: 真梦行路
@file: kafka.py
@time: 2018/9/3 10:20
'''
import sys
import json
import pandas as pd
import os
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "xxx.xxx.x.xxx" #服务器端口地址
KAFAKA_PORT = 9092 #端口号
KAFAKA_TOPIC = "topic0" #topic
data=pd.read_csv(os.getcwd()+'\\data\\1.csv')
key_value=data.to_json()
class Kafka_producer():
'''
生产模块:根据不同的key,区分消息
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.key = key
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort)
)
def sendjsondata(self, params):
try:
parmas_message = params #注意dumps
producer = self.producer
producer.send(self.kafkatopic, key=self.key, value=parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print(e)
class Kafka_consumer():
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid,key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.key = key
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort)
)
def consume_data(self):
try:
for message in self.consumer:
yield message
except KeyboardInterrupt as e:
print(e)
def sortedDictValues(adict):
items = adict.items()
items=sorted(items,reverse=False)
return [value for key, value in items]
def main(xtype, group, key):
'''
测试consumer和producer
'''
if xtype == "p":
# 生产模块
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, key)
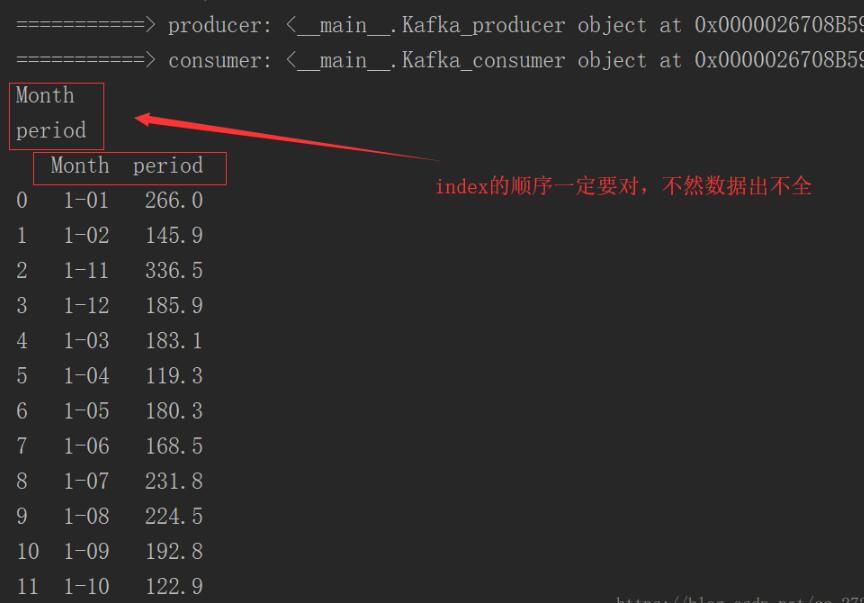
print("===========> producer:", producer)
params =key_value
producer.sendjsondata(params)
if xtype == 'c':
# 消费模块
consumer = Kafka_consumer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, group,key)
print("===========> consumer:", consumer)
message = consumer.consume_data()
for msg in message:
msg=msg.value.decode('utf-8')
python_data=json.loads(msg) ##这是一个字典
key_list=list(python_data)
test_data=pd.DataFrame()
for index in key_list:
print(index)
if index=='Month':
a1=python_data[index]
data1 = sortedDictValues(a1)
test_data[index]=data1
else:
a2 = python_data[index]
data2 = sortedDictValues(a2)
test_data[index] = data2
print(test_data)
# print('value---------------->', python_data)
# print('msg---------------->', msg)
# print('key---------------->', msg.kry)
# print('offset---------------->', msg.offset)
if __name__ == '__main__':
main(xtype='p',group='py_test',key=None)
main(xtype='c',group='py_test',key=None)
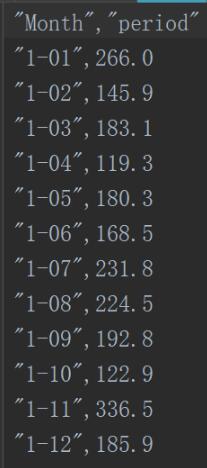
数据1.csv如下所示:
几点注意:
1、一定要有一个服务器的端口地址,不要用本机的ip或者乱写一个ip不然程序会报错。(我开始就是拿本机ip怼了半天,总是报错)
2、注意数据的传输格式以及编码问题(二进制传输),数据先转成json数据格式传输,然后将json格式转为需要格式。(不是json格式的注意dumps)
例中,dataframe->json->dataframe
3、例中dict转dataframe,也可以用简单方法直接转。
eg: type(data) ==>dict,data=pd.Dateframe(data)
以上这篇在python环境下运用kafka对数据进行实时传输的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在Spring Boot应用程序中使用Apache Kafka的方法步骤详解
第1步:生成我们的项目: Spring Initializr来生成我们的项目.我们的项目将提供Spring MVC / Web支持和Apache Kafka支持. 第2步:发布/读取Kafka主题中的消息: <b>public</b> <b>class</b> User { <b>private</b> String name; <b>private</b> <b>int</b> age
-
kafka-python批量发送数据的实例
如下所示: from kafka import KafkaClient from kafka.producer import SimpleProducer def send_data_2_kafka(datas): ''' 向kafka解析队列发送数据 ''' client = KafkaClient(hosts=KAFKABROKER.split(","), timeout=30) producer = SimpleProducer(client, async=False) curc
-
Docker搭建Zookeeper&Kafka集群的实现
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用的笔记本,所以每次连接网络IP都会改变,还要总是修改配置文件的,过于繁琐,不方便测试.(通过Docker虚拟网络的方式可以避免此问题,当时实验的时候没有了解到) Docker 安装 如果已经安装Docker请忽略此步骤 Docker支持以下的CentOS版本: CentOS 7 (64
-
Docker部署Kafka以及Spring Kafka实现
这篇文章主要介绍了Docker部署Kafka以及Spring Kafka实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 从https://hub.docker.com/查找kafka 第三个活跃并stars数量多 进去看看使用 我们使用docker-compose来构建镜像 查看使用文档中的docker-compose.yml 因为kafka要搭配zookeeper一起使用,所以文档中包含了zookeeper 我修改了一下版本号 以及变量参
-
通过pykafka接收Kafka消息队列的方法
没有Kafka环境,所以也没有进行验证.感觉今后应该能用到,所以借抄在此,备查. pykafka使用示例,自动消费最新消息,不重复消费: # -* coding:utf8 *- from pykafka import KafkaClient host = '192.168.200.38' client = KafkaClient(hosts="%s:9092" % host) print client.topics # 生产者 # topicdocu = client.topics['
-
对python操作kafka写入json数据的简单demo分享
如下所示: 安装kafka支持库pip install kafka-python from kafka import KafkaProducer import json ''' 生产者demo 向test_lyl2主题中循环写入10条json数据 注意事项:要写入json数据需加上value_serializer参数,如下代码 ''' producer = KafkaProducer( value_serializer=lambda v: json.dumps(v).encode('utf-8'
-
详解Spring Kafka中关于Kafka的配置参数
SpringKafka文档地址:https://docs.spring.io/spring-kafka/reference/htmlsingle kafka文档地址:http://kafka.apache.org/documentation SpringKafka中配置的Java配置实现类:https://github.com/spring-projects/spring-boot/blob/v1.5.4.RELEASE/spring-boot-autoconfigure/src/main/ja
-
python hbase读取数据发送kafka的方法
本例子实现从hbase获取数据,并发送kafka. 使用 #!/usr/bin/env python #coding=utf-8 import sys import time import json sys.path.append('/usr/local/lib/python3.5/site-packages') from thrift import Thrift from thrift.transport import TSocket from thrift.transport import
-
在python环境下运用kafka对数据进行实时传输的方法
背景: 为了满足各个平台间数据的传输,以及能确保历史性和实时性.先选用kafka作为不同平台数据传输的中转站,来满足我们对跨平台数据发送与接收的需要. kafka简介: Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现.kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外ka
-

在Linux环境下安装Kafka
目录 二.生产与消费 2.1 kafka-topics.sh 用于管理主题 2.2 kafka-console-consumer.sh用于消费消息 2.3 kafka-console-producer.sh用于生产消息 2.4 具体操作 一.环境准备 jdk下载地址链接:下载地址 zookeeper下载地址链接:下载地址 kafka下载地址链接:下载地址 1.1 Java环境为前提 1.1.1 上传jdk-8u261-linux-x64.rpm到服务器并安装 # 安装命令 rpm -ivh jd
-
python环境下OPenCV处理视频流局部区域像素值
参考我之前写的处理图片的文章:Python+OpenCV实现[图片]局部区域像素值处理(改进版) 开发环境:Python3.6.0 + OpenCV3.2.0 任务目标:摄像头采集图像(例如:480640),并对视频流每一帧(灰度图)特定矩形区域(48030)像素值进行行求和,得到一个480*1的数组,用这480个数据绘制条形图,即在逐帧采集视频流并处理后"实时"显示采集到的视频,并"实时"更新条形图.工作流程如下图: 源码: # -*- coding:utf-8
-
python环境下安装opencv库的方法
注意:安装opencv之前需要先安装numpy,matplotlib等 一.安装方法 方法一.在线安装 1.先安装opencv-python pip install opencv-python --user 我的python版本是3.6.8,可以看到opencv安装的默认版本是 opencv_python-4.1.0.25-cp36-cp36m-win_amd64.whl 2.再安装opencv-contrib-python pip install opencv-contrib-python -
-
Python环境下安装PyGame和PyOpenGL的方法
在进行增强现实的时候我们需要用到两个工具包:PyGame 和 PyOpenGL,本章在python环境下对这两个工具包的安装进行说明. 一.安装PyGame PyGame 是非常流行的游戏开发工具包,它可以非常简单地处理显示窗口.输入设备.事件,以及其他内容.其下载安装过程如下: 1. 进入python官网点击PyPI 2. 输入pygame,点击pygame1.9.6 3 点进去找到下面的 Download files,找到自己相对应要下载的版本,我的是 python37 ,64位的,所以我下
-
python读取json文件并将数据插入到mongodb的方法
本文实例讲述了python读取json文件并将数据插入到mongodb的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 import sunburnt import urllib from pymongo import Connection from bson.objectid import ObjectId import logging from datetime import datetime import json from time import mktime
-
CentoS6.5环境下redis4.0.1(stable)安装和主从复制配置方法
本文实例讲述了CentoS6.5环境下redis4.0.1(stable)安装和主从复制配置方法.分享给大家供大家参考,具体如下: 依赖环境 Centos 6.5 gcc-4.4.7:编译redis原文件 tcl-8.5.7:运行编译检测 1.编译redis #cd /usr/local #tar -zxvf redis-4.0.1.tar.gz #mv redis-4.0.1 redis #cd redis #make 运行编译测试make test需要tcl-8.5及以上 #yum inst
-
python合并已经存在的sheet数据到新sheet的方法
简单的合并,本例是横向合并,纵向合并可以自行调整. import xlrd import xlwt import shutil from xlutils.copy import copy import datetime # 打开要使用的excel,获取要需要写入的行数 bk = xlrd.open_workbook('A.xlsx') #打开A文件 nbk = copy(bk) newsh = nbk.add_sheet('totale') #新建total名字的sheet nsheet = b
-
centos7环境下swoole1.9的安装与HttpServer的使用方法分析
本文实例讲述了centos7环境下swoole1.9的安装与HttpServer的使用方法.分享给大家供大家参考,具体如下: 一.下载swoole源码包 https://github.com/swoole/swoole-src/releases 如:swoole-src-1.9.6.tar.gz 二.编译安装 > yum install gcc gcc-c++ kernel-devel make autoconf > tar xf swoole-src-1.9.6.tar.gz > cd
-
Python使用psutil库对系统数据进行采集监控的方法
大家好,我是辰哥- 今天给大家介绍一个可以获取当前系统信息的库--psutil 利用psutil库可以获取系统的一些信息,如cpu,内存等使用率,从而可以查看当前系统的使用情况,实时采集这些信息可以达到实时监控系统的目的. psutil库 psutil的安装很简单 pip install psutil psutil库可以获取哪些系统信息? psutil有哪些作用 1.内存使用情况 2.磁盘使用情况 3.cpu使用率 4.网络接口发送接收流量 5.获取当前网速 6.系统当前进程 ... 下面通过具