详解Appium+Python之生成html测试报告
思考:测试用例执行后,如何生成一个直观漂亮的测试报告呢?
分析:
1.unittest单元测试框架本身带有一个textTestRunner类,可以生成txt文本格式的测试报告,但是页面不够直观
2.我们可以导入第三方库,比如常用的HTMLTestRunner类,可以生成html格式测试报告
3.首先去下载HTMLTestRunner_PY3.py脚本(我这里采用Python3.7),然后放置在Python3.7路径下的Lib目录下,使用时需要导入(即import HTMLTestRunner_PY3)
代码示例如下:
if __name__ == "__main__":
#实例化测试套件
suite = unittest.TestSuite()
#加载测试用例
suite.addTest(TestCase("test_login"))
#生成测试报告
# 选择指定时间格式
timestr = time.strftime('%Y-%m-%d%H%M%S', time.localtime(time.time()))
# 定义测试报告存放路径和报告名称
Report = os.path.join(
PATH('E://testing_code/code/SmartSiteTestScript/report/test_report_') +
timestr +
'.html')
with open(Report, 'wb') as f:
runner = HTMLTestRunner_PY3.HTMLTestRunner(stream=f,
verbosity=2,
title='XXXX自动化测试报告',
description='执行人:丹姐')
runner.run(suite)
# 关闭测试报告
f.close()
解析:
1.在测试报告名中显示时间:(引入time包) timestr=time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
time.time():获取当前时间戳
time.ctime():获取当前时间的字符串
time.localtime():当前时间的struct_time形式
time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime()):获取特定格式的时间,通常用这个
2.TestSuite是个容器,往里面用addTest()添加测试用例
3.Report定义报告保存的路径以及文件名
open() 函数用于打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写
语法:open(name[, mode[, buffering]])
- name : 一个包含了你要访问的文件名称的字符串值
- mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)
- buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认
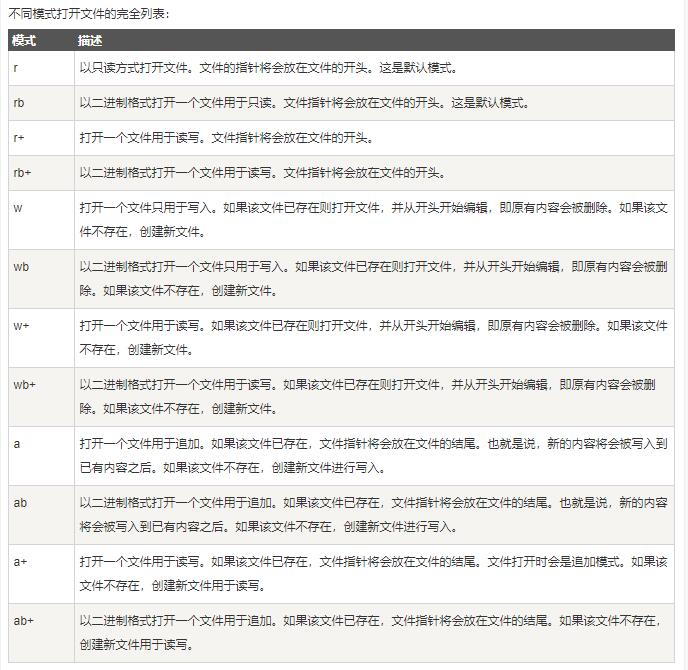
这里常用的为 open(Report,'wb'):以二进制形式打开文件Report
4.runner定义测试报告格式,stream定义报告写入的二进制文件,title为报告的标题,description为报告的说明,runner.run()用来运行测试case,注意最后用f.close()将文件关闭!
verbosity表示测试结果的信息复杂度,有三个值
- 0 (静默模式): 你只能获得总的测试用例数和总的结果 比如 总共100个 失败20 成功80
- 1 (默认模式): 非常类似静默模式 只是在每个成功的用例前面有个“.” 每个失败的用例前面有个 “F”
- 2 (详细模式):测试结果会显示每个测试用例的所有相关的信息
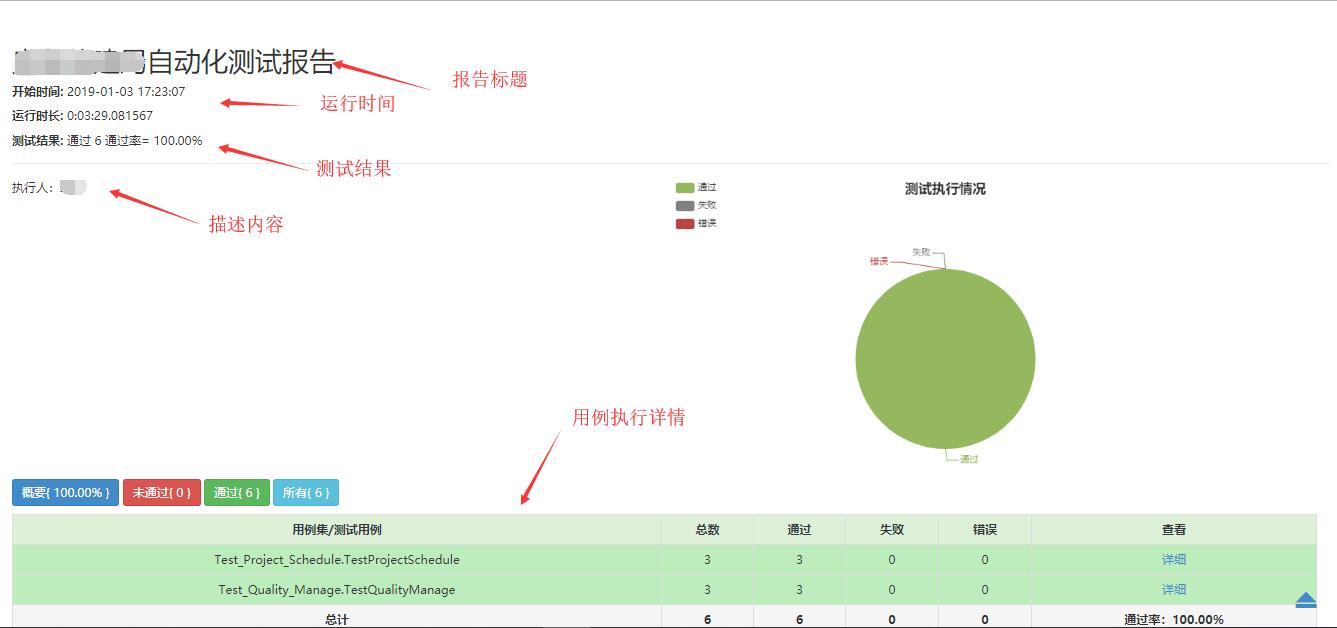
测试报告效果图如下所示:
相关推荐
-
解决python3 HTMLTestRunner测试报告中文乱码的问题
使用HTMLTestRunner输出的测试报告中,标题和错误说明的中文乱码. 环境: python v3.6 HTMLTestRunner v0.8.2 定位问题 刚开始以为是python3对HTMLTestRunner文件兼容的问题.网上搜了一些解决办法基本都是说python2的,对比看了一下,我这边兼容性是可以的. 接下来,查看HTMLTestRunner文件输出,倒着去找,最后问题定位到: self.stream.write(output) 这一行,print(output)是正常输出中文
-

Python发送邮件测试报告操作实例详解
本文实例讲述了Python发送邮件测试报告操作.分享给大家供大家参考,具体如下: 发邮件需要用到python两个模块,smtplib和email,这俩模块是python自带的,只需import即可使用.smtplib模块主要负责发送邮件,email模块主要负责构造邮件.其中MIMEText()定义邮件正文,Header()定义邮件标题.MIMEMulipart模块构造带附件 发送HTML格式的邮件: send_email_html.py import smtplib from email.mim
-
python 字典(dict)遍历的四种方法性能测试报告
python中,遍历dict的方法有四种.但这四种遍历的性能如何呢?我做了如下的测试 l = [(x,x) for x in xrange(10000)] d = dict(l) from time import clock t0=clock() for i in d: t = i + d[i] t1=clock() for k,v in d.items(): t = k + v t2=clock() for k,v in d.iteritems(): t = k + v t3=clock()
-
python使用 HTMLTestRunner.py生成测试报告
本文介绍了python使用 HTMLTestRunner.py生成测试报告 ,分享给大家,具体如下: HTMLTestRunner.py python 2版本 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 使用时,先建立一个"PyDev Package",将下载下来的HTMLTestRunner.py文件拷贝在该目录下. 例子:testcase5_dynamic.py import unittest from dev.
-
详解Appium+Python之生成html测试报告
思考:测试用例执行后,如何生成一个直观漂亮的测试报告呢? 分析: 1.unittest单元测试框架本身带有一个textTestRunner类,可以生成txt文本格式的测试报告,但是页面不够直观 2.我们可以导入第三方库,比如常用的HTMLTestRunner类,可以生成html格式测试报告 3.首先去下载HTMLTestRunner_PY3.py脚本(我这里采用Python3.7),然后放置在Python3.7路径下的Lib目录下,使用时需要导入(即import HTMLTestRunner_P
-
详解appium+python 启动一个app步骤
询问度娘搭好appium和python环境,开启移动app自动化的探索(基于Android),首先来记录下如何启动待测的app吧! 如何启动APP?1.获取包名:2.获取launcherActivity.获取这两个关键东西的方法很多,推荐使用sdk自带的aapt:aapt即Android Asset Packaging Tool,在SDK的build-tools目录下.该工具可以查看apk包名和launcherActivity,当然还有更多的功能,有兴趣的可以查看相关资料. 一.下载aapt:
-
详解用Pytest+Allure生成漂亮的HTML图形化测试报告
对于软件测试工作来说,测试报告是非常重要的工作产出.一个漂亮.清晰.格式规范.内容完整的测试报告,既能最大化我们的测试工作产出,又能够减少开发人员和测试人员的沟通成本. 本篇文章将介绍如何使用开源的测试报告生成框架Allure生成规范.格式统一.美观的测试报告. 通过这篇文章的介绍,你将能够: 将Allure与Pytest测试框架相结合: 如何定制化测试报告内容 执行测试之后,生成Allure格式的测试报告. 如何与Jenkins集成. 将测试环境信息展示到测试报告中. 1.Allure测试报告
-
详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或
-
详解运行Python的神器Jupyter Notebook
Jupyter Notebook Jupyter项目是从Ipython项目中分出去的,在Ipython3.x之前,他们两个是在一起发布的.在Ipython4.x之后,Jupyter作为一个单独的项目进行开发和管理.因为Jupyter不仅仅可以运行Python程序,它还可以执行其他流程编程语言的运行. Jupyter Notebook包括三个部分,第一个部分是一个web应用程序,提供交互式界面,可以在交互式界面中运行相应的代码. 上图是NoteBook的交互界面,我们可以对文档进行编辑,运行等操作
-
详解让Python性能起飞的15个技巧
目录 前言 如何测量程序的执行时间 1.使用map()进行函数映射 2.使用set()求交集 3.使用sort()或sorted()排序 4.使用collections.Counter()计数 5.使用列表推导 6.使用join()连接字符串 7.使用x,y=y,x交换变量 8.使用while1取代whileTrue 9.使用装饰器缓存 10.减少点运算符(.)的使用 11.使用for循环取代while循环 12.使用Numba.jit加速计算 13.使用Numpy矢量化数组 14.使用in检查