自增长键列统计信息的处理方法
这篇文章通过文字代码的形式讲解了如何处理用自增长键列的统计信息。我们都知道,在SQL Server里每个统计信息对象都有关联的直方图。直方图用多个步长描述指定列数据分布情况。在一个直方图里,SQL Server最大支持200的步长,但当你查询的数据范围在直方图最后步长后,这是个问题。我们来看下面的代码,重现这个情形:
-- Create a simple orders table
CREATE TABLE Orders
(
OrderDate DATE NOT NULL,
Col2 INT NOT NULL,
Col3 INT NOT NULL
)
GO
-- Create a Non-Unique Clustered Index on the table
CREATE CLUSTERED INDEX idx_CI ON Orders(OrderDate)
GO
-- Insert 31465 rows from the AdventureWorks2008r2 database
INSERT INTO Orders (OrderDate, Col2, Col3) SELECT OrderDate, CustomerID, TerritoryID FROM AdventureWorks2008R2.Sales.SalesOrderHeader
GO
-- Rebuild the Clustered Index, so that we get fresh statistics.
-- The last value in the Histogram is 2008-07-31.
ALTER INDEX idx_CI ON Orders REBUILD
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100101', 1, 1)
GO 200
在索引重建后,我们再看下直方图,我们发现最后步进的值是2008-07-31。
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI') WITH HISTOGRAM
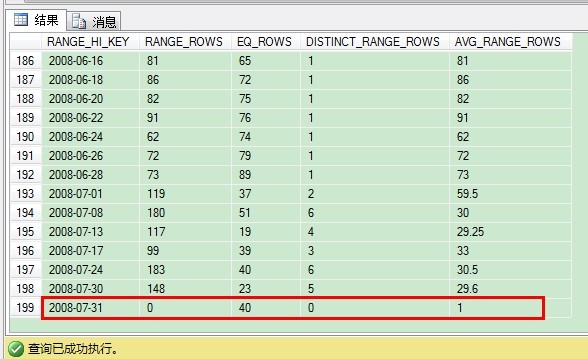
你已经看到,在最后步进到表里后,我们插入了200条额外记录。这样的话,直方图并没有真实反馈实际的数据分布情况,但SQL Server还是要进行基数计算。我们现在来看看在不同版本里SQL Server是如何处理这个问题的。
SQL Server 2005 SP1- SQL Server 2012
在SQL Server 2014之前,基数计算对此问题的处理非常简单:SQL Server估计行数为1,你可以从下面的图片里看到。
点击工具栏的显示包含实际的执行计划,并执行如下查询:
SELECT * FROM dbo.Orders WHERE OrderDate='2010-01-01'

自SQL Server 2005 SP1起,查询优化器可以标记1列为自增长(Ascending)来克服刚才介绍的限制。如果你用自增长列值更新了统计信息对象3次,那列就会被标记为自增长列。为了看有没有列标记为自增长,你可以使用跟踪标记2388。当你启用这个跟踪标记,DBCC SHOW_STATISTICS的输出就改变了,有额外列返回。
DBCC TRACEON(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在下面的代码更新统计信息3次,每次用自增长键列值在我们聚集索引末尾插入行。
-- => 1st update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100201', 1, 1)
GO 200
-- => 2nd update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100301', 1, 1)
GO 200
-- => 3rd update the Statistics on the table with a FULLSCAN
UPDATE STATISTICS Orders WITH FULLSCAN
GO
然后,当我们执行DBCC SHOW_STATISTICS命令,你会看到SQL Server已讲那列标记为Ascending。
DBCC TRACEON(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在当你再次执行查询不是直方图范围的数据时,没有任何改变。为了使用标记为自增长键列,你要启用另外一个跟踪标记-2389。如果你启用这个跟踪标记,查询优化器就是密度向量(Density Vector)来进行基数计算。
-- Now we query the newly inserted range which is currently not present in the Histogram. -- With Trace Flag 2389, the Query Optimizer uses the Density Vector to make the Cardinality Estimation. SELECT * FROM Orders WHERE OrderDate = '20100401' OPTION (RECOMPILE, QUERYTRACEON 2389) GO
来看下现在的表密度:
DBCC TRACEOFF(2388)
DBCC SHOW_STATISTICS('dbo.Orders', 'idx_CI')

现在的表密度是0.0008873115,因此查询优化器的估计行数是28.4516:0.0008873115*(32265-200)。

这虽然不是最好的结果,但比估计行数1好很多!
(这里有问题,我本地是SQL Server 2008r2,测试估计行数还是1,不知原因,望知道的朋友解释下,多谢!)

SQL Server 2014
在SQL Server 2014引入的一个新功能是新基数计算。新基数计算对于自增长键问题的处理非常简单:默认不使用任何跟踪标记,来使用统计信息对象的密度向量来进行基数计算。下面查询启用2312跟踪标记的基数计算来运行同个查询。
1 -- With the new Cardinality Estimator SQL Server estimates 28.4516 rows at the Clustered Index Seek operator. 2 SELECT * FROM Orders 3 WHERE OrderDate = '20100401' 4 OPTION (RECOMPILE, QUERYTRACEON 2312) 5 GO
我们来看这里的基数计算,你会看到查询优化器再次估计行数是28.4516,但这一次没表上自增长。这是SQL Server 2014的自带功能。
(SQL Server 2014测试失败,估计行数也是1……)
在这篇文章,我向你展示了SQL Server的查询优化器如何处理自增长键问题。在SQL Server 2014之前,你需要启用2389跟踪标记来获得更好的基数计算——这样的话那列会标记为自增长(ascending)。SQL Server 2014,查询优化器默认就使用密度向量来进行基数计算,这样就方便很多。我希望你对此有所收获,在SQL Server里如何处理自增长键列问题你会有更好的想法。
希望对大家有所启迪,谢谢。
相关推荐
-
实现oracle数据库字段自增长(两种方式)
程序猿都知道mysql等其他的数据库都有随着记录的插入而表ID会自动增长的功能,反而oracle却没有这一功能,下面通过两种方式来解决字段增长的功能,具体内容情况下文. 因为两种方式都需要通过创建序列来实现,这里先给出序列的创建方式. 复制代码 代码如下: CREATE SEQUENCE 序列名 [INCREMENT BY n] [START WITH n] [{MAXVALUE/ MINVALUE n|NOMAXVALUE}] [{CYCLE|NOCYCLE}] [{CACHE n|NOCAC
-
oracle中的ID号实现自增长的方法
利用序列产生主键值. 序列(Sequence)是一种可以被多个用户使用的用于产生一系列唯一数字的数据库对象.序列定义存储在数据字典中,通过提供唯一数值的顺序表来简化程序设计工作,可以使用序列自动产生主键的键值.当一个序列第一次被查询调用时,它将返回一个预定值.在随后的每次查询中,序列将产生一个按指定的增量增长的值.序列可以循环,或者是连续增加的,直到指定的最大值为止. 复制代码 代码如下: --创建sequence create sequence seq_on_test increment by
-
SQL Server设置主键自增长列(使用sql语句实现)
1.新建一数据表,里面有字段id,将id设为为主键 复制代码 代码如下: create table tb(id int,constraint pkid primary key (id)) create table tb(id int primary key ) 2.新建一数据表,里面有字段id,将id设为主键且自动编号 复制代码 代码如下: create table tb(id int identity(1,1),constraint pkid primary key (id)) create
-
对有自增长字段的表导入数据注意事项
对有自增长字段的表导入数据注意事项: 1.把自增长字段暂时设置成非自增长的:导入数据成功后,再设置成自增长字段. 2.导出.导入数据时,注意选择文本格式,防止出现乱码.数据转换不成功等情况. 3.对于表中的原有数据,不会覆盖原有数据,只会增加.
-
mysql修改自增长主键int类型为char类型示例
原来有一个表中的主键是int自增长类型, 因为业务变化需要把int改成char类型的主键.同时因为原来的表中已经存在了数据,不能删除表重建,只能修改表结构. 首先去掉自增长属性: alter table table_name change indexid indexid int; 然后去掉主键: ALTER TABLE table_name DROP primary key; 修改表结构为char类型: alter table table_name change indexid ind
-

自增长键列统计信息的处理方法
这篇文章通过文字代码的形式讲解了如何处理用自增长键列的统计信息.我们都知道,在SQL Server里每个统计信息对象都有关联的直方图.直方图用多个步长描述指定列数据分布情况.在一个直方图里,SQL Server最大支持200的步长,但当你查询的数据范围在直方图最后步长后,这是个问题.我们来看下面的代码,重现这个情形: -- Create a simple orders table CREATE TABLE Orders ( OrderDate DATE NOT NULL, Col2 INT NO
-
Oracle 12c新特性之如何检测有用的多列统计信息详解
前言 之前和大家分享过Oracle 11g下的一个新特性--收集多列统计信息(http://www.jb51.net/article/109514.htm),今天和大家分享Oracle 12c的一个新特性--自动检测有用列组信息.二者相得益彰,大家可以具体情况酌情使用. 言归正传,我们可以针对一个表,基于特定的工作负荷,通过使用DBMS_STATS.SEED_COL_USAGE和REPORT_COL_USAGE来确定我们需要哪些列组.当你不清除需要创建哪个扩展统计信息时,这个技术是非常有用的.需
-
Oracle 11g收集多列统计信息详解
前言 通常,当我们将SQL语句提交给Oracle数据库时,Oracle会选择一种最优方式来执行,这是通过查询优化器Query Optimizer来实现的.CBO(Cost-Based Optimizer)是Oracle默认使用的查询优化器模式.在CBO中,SQL执行计划的生成,是以一种寻找成本(Cost)最优为目标导向的执行计划探索过程.所谓成本(Cost)就是将CPU和IO消耗整合起来的量化指标,每一个执行计划的成本就是经过优化器内部公式估算出的数字值. 我们在写SQL语句的时候,经常会碰到w
-
概述MySQL统计信息
MySQL执行SQL会经过SQL解析和查询优化的过程,解析器将SQL分解成数据结构并传递到后续步骤,查询优化器发现执行SQL查询的最佳方案.生成执行计划.查询优化器决定SQL如何执行,依赖于数据库的统计信息,下面我们介绍MySQL 5.7中innodb统计信息的相关内容. MySQL统计信息的存储分为两种,非持久化和持久化统计信息. 一.非持久化统计信息 非持久化统计信息存储在内存里,如果数据库重启,统计信息将丢失.有两种方式可以设置为非持久化统计信息: 1 全局变量, INNODB_STATS
-
详解mysql持久化统计信息
一.持久化统计信息的意义: 统计信息用于指导mysql生成执行计划,执行计划的准确与否直接影响到SQL的执行效率:如果mysql一重启 之前的统计信息就没有了,那么当SQL语句来临时,那么mysql就要收集统计信息然后再生成SQL语句的执行 计划.如果能在关闭mysql的时候就把统计信息保存起来,那么在启动时就不要再收集一次了,这种处理方式 有助于效率的提升. 二.统计信息准确与否也同样重要: 第一目中我们说明了"持久化统计信息的意义",我们的假设统计信息是有用的,是准确的:如果统计信
-
SQLSERVER收集语句运行的统计信息并进行分析
对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间.执行时间.做了多少次磁盘读等. 如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息. 这些信息对分析问题很有价值. 复制代码 代码如下: SET STATISTICS TIME ON SET STATISTICS IO ON SET STATISTICS PROFILE ON SET STATISTICS TIME ON ----------------------------
-
SQL Server统计信息更新时采样百分比对数据预估准确性的影响详解
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,"一招鲜吃遍天"的做法已经行不通了(题外话:整个时代不都是这样子吗) 当然,还是那句话,既然写了就不能太俗套,写点不一样的,本文通过分析一个类似实际案例来解读统计信息的更新的相关问题. 对于实际问题,不但要解决问题,更重要的是要从理论上深入分析,才能更好地驾驭数据库. 何时更新统计信息 (1)查询执行缓慢
-
MySQL 8.0统计信息不准确的原因
前言 不管是Oracle还是MySQL,新版本推出的新特性,一方面给产品带来功能.性能.用户体验等方面的提升,另一方面也可能会带来一些问题,如代码bug.客户使用方法不正确引发问题等等. 案例分享 MySQL 5.7下的场景 (1)首先,创建两张表,并插入数据 mysql> select version(); +------------+ | version() | +------------+ | 5.7.30-log | +------------+ 1 row in set (0.00 s
-
SQL Server自动更新统计信息的基本算法
自动更新统计信息的基本算法是: · 如果表格是在 tempdb 数据库表的基数是小于 6,自动更新到表的每个六个修改. · 如果表的基数是大于 6,但小于或等于 500,更新状态每 500 的修改. · 如果基数大于 500,表为更新统计信息时(500 + 20%的表)发生了更改. · 表变量为基数的更改不会触发自动更新统计信息. 注意:此严格意义上讲,SQL Server 计算基数为表中的行数. 注意:除了基数,该谓语的选择性也会影响 AutoStats 生成.这意味着该统计信息可能无法更新的
-
在ASP.NET 2.0中操作数据之十五:在GridView的页脚中显示统计信息
导言 除了需要了解产品的单价.库存量和订货量,并按等级排序之外,用户可能还对统计信息感兴趣,比如说平均价格.库存总量等等.这些统计信息常常显示在报表最下面的一个统计行中.GridView控件可以含有一个页脚行,我们可以通过编程将统计数据插入到它的单元格里面去.这个任务给了我们以下3个挑战: 1.配置GridView以显示它的页脚行 2.确定统计数据.即我们应该如何计算平均价格还有库存总量? 3.将统计信息插入到页脚行的相应的单元格中 在本节教程中,我们将会看到如何去征服这些挑战.另外呢,我们将创