详解10个可以快速用Python进行数据分析的小技巧
一些小提示和小技巧可能是非常有用的,特别是在编程领域。有时候使用一点点黑客技术,既可以节省时间,还可能挽救“生命”。
一个小小的快捷方式或附加组件有时真是天赐之物,并且可以成为真正的生产力助推器。所以,这里有一些小提示和小技巧,有些可能是新的,但我相信在下一个数据分析项目中会让你非常方便。
Pandas中数据框数据的Profiling过程
Profiling(分析器)是一个帮助我们理解数据的过程,而Pandas Profiling是一个Python包,它可以简单快速地对Pandas 的数据框数据进行探索性数据分析。
Pandas中df.describe()和df.info()函数可以实现EDA过程第一步。但是,它们只提供了对数据非常基本的概述,对于大型数据集没有太大帮助。 而Pandas中的Profiling功能简单通过一行代码就能显示大量信息,且在交互式HTML报告中也是如此。
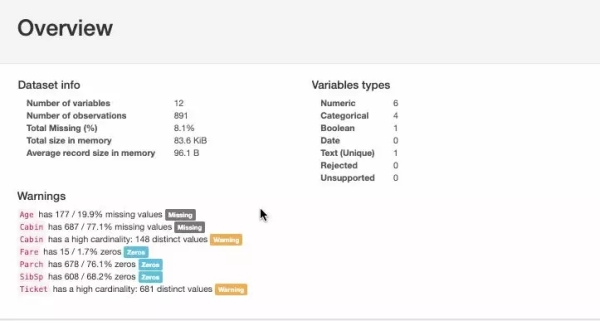
对于给定的数据集,Pandas中的profiling包计算了以下统计信息:

由Pandas Profiling包计算出的统计信息包括直方图、众数、相关系数、分位数、描述统计量、其他信息——类型、单一变量值、缺失值等。
1. 安装
用pip安装或者用conda安装
pip install pandas-profiling conda install -c anaconda pandas-profiling
2. 用法
下面代码是用很久以前的泰坦尼克数据集来演示多功能Python分析器的结果。
#importing the necessary packages
import pandas as pd
import pandas_profiling
df = pd.read_csv('titanic/train.csv')
pandas_profiling.ProfileReport(df)
一行代码就能实现在Jupyter Notebook中显示完整的数据分析报告,该报告非常详细,且包含了必要的图表信息。

还可以使用以下代码将报告导出到交互式HTML文件中。
profile = pandas_profiling.ProfileReport(df) profile.to_file(outputfile="Titanic data profiling.html")
Pandas实现交互式作图
Pandas有一个内置的.plot()函数作为DataFrame类的一部分。但是,使用此功能呈现的可视化不是交互式的,这使得它没那么吸引人。同样,使用pandas.DataFrame.plot()函数绘制图表也不能实现交互。 如果我们需要在不对代码进行重大修改的情况下用Pandas绘制交互式图表怎么办呢?这个时候就可以用Cufflinks库来实现。
Cufflinks库可以将有强大功能的plotly和拥有灵活性的pandas结合在一起,非常便于绘图。下面就来看在pandas中如何安装和使用Cufflinks库。
1. 安装
pip install plotly # Plotly is a pre-requisite before installing cufflinks pip install cufflinks
2. 用法
#importing Pandas import pandas as pd #importing plotly and cufflinks in offline mode import cufflinks as cf import plotly.offline cf.go_offline() cf.set_config_file(offline=False, world_readable=True)
是时候展示泰坦尼克号数据集的魔力了。
df.iplot()
df.iplot() vs df.plot()
右侧的可视化显示了静态图表,而左侧图表是交互式的,更详细,并且所有这些在语法上都没有任何重大更改。
Magic命令
Magic命令是Jupyter notebook中的一组便捷功能,旨在解决标准数据分析中的一些常见问题。使用命令%lsmagic可以看到所有的可用命令。
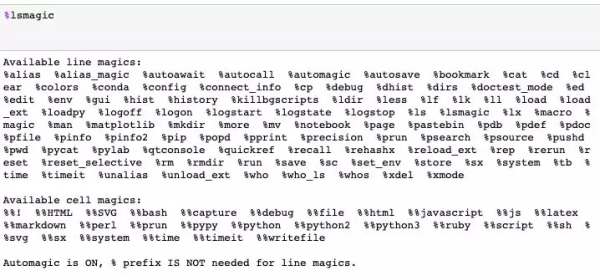
所有可用的Magic命令列表
Magic命令有两种:行magic命令(line magics),以单个%字符为前缀,在单行输入操作;单元magic命令(cell magics),以双%%字符为前缀,可以在多行输入操作。如果设置为1,则不用键入%即可调用Magic函数。
接下来看一些在常见数据分析任务中可能用到的命令:
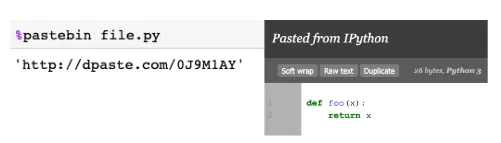
1. % pastebin
%pastebin将代码上传到Pastebin并返回url。Pastebin是一个在线内容托管服务,可以存储纯文本,如源代码片段,然后通过url可以与其他人共享。事实上,Github gist也类似于pastebin,只是有版本控制。
在file.py文件中写一个包含以下内容的python脚本,并试着运行看看结果。
#file.py def foo(x): return x
在Jupyter Notebook中使用%pastebin生成一个pastebin url。
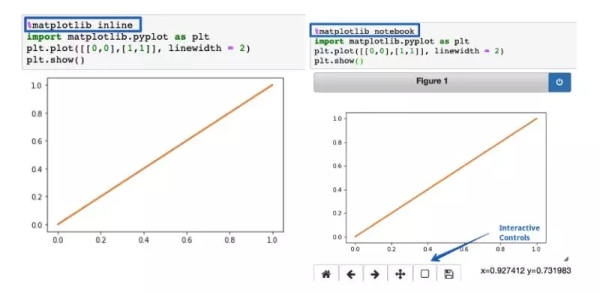
2. %matplotlib notebook
函数用于在Jupyter notebook中呈现静态matplotlib图。用notebook替换inline,可以轻松获得可缩放和可调整大小的绘图。但记得这个函数要在导入matplotlib库之前调用。
3. %run
用%run函数在notebook中运行一个python脚本试试。
%run file.py %%writefile
%% writefile是将单元格内容写入文件中。以下代码将脚本写入名为foo.py的文件并保存在当前目录中。

4. %%latex
%%latex函数将单元格内容以LaTeX形式呈现。此函数对于在单元格中编写数学公式和方程很有用。

查找并解决错误
交互式调试器也是一个神奇的功能,我把它单独定义了一类。如果在运行代码单元时出现异常,请在新行中键入%debug并运行它。 这将打开一个交互式调试环境,它能直接定位到发生异常的位置。还可以检查程序中分配的变量值,并在此处执行操作。退出调试器单击q即可。

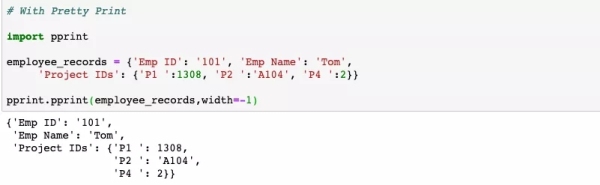
Printing也有小技巧
如果您想生成美观的数据结构,pprint是首选。它在打印字典数据或JSON数据时特别有用。接下来看一个使用print和pprint来显示输出的示例。

让你的笔记脱颖而出
我们可以在您的Jupyter notebook中使用警示框/注释框来突出显示重要内容或其他需要突出的内容。注释的颜色取决于指定的警报类型。只需在需要突出显示的单元格中添加以下任一代码或所有代码即可。
1. 蓝色警示框:信息提示
<div class="alert alert-block alert-info"> <b>Tip:</b> Use blue boxes (alert-info) for tips and notes. If it's a note, you don't have to include the word “Note”. </div>

2. 黄色警示框:警告
<div class="alert alert-block alert-warning"> <b>Example:</b> Yellow Boxes are generally used to include additional examples or mathematical formulas. </div>

3. 绿色警示框:成功
<div class="alert alert-block alert-success"> Use green box only when necessary like to display links to related content. </div>

4. 红色警示框:高危
<div class="alert alert-block alert-danger"> It is good to avoid red boxes but can be used to alert users to not delete some important part of code etc. </div>

打印单元格所有代码的输出结果
假如有一个Jupyter Notebook的单元格,其中包含以下代码行:
In [1]: 10+5
11+6
Out [1]: 17
单元格的正常属性是只打印最后一个输出,而对于其他输出,我们需要添加print()函数。然而通过在notebook顶部添加以下代码段可以一次打印所有输出。
添加代码后所有的输出结果就会一个接一个地打印出来。
In [1]: 10+5
11+6
12+7
Out [1]: 15
Out [1]: 17
Out [1]: 19
恢复原始设置:
InteractiveShell.ast_node_interactivity = "last_expr"
使用'i'选项运行python脚本
从命令行运行python脚本的典型方法是:python hello.py。但是,如果在运行相同的脚本时添加-i,例如python -i hello.py,就能提供更多优势。接下来看看结果如何。
首先,即使程序结束,python也不会退出解释器。因此,我们可以检查变量的值和程序中定义的函数的正确性。

其次,我们可以轻松地调用python调试器,因为我们仍然在解释器中:
import pdb pdb.pm()
这能定位异常发生的位置,然后我们可以处理异常代码。
自动评论代码
Ctrl / Cmd + /自动注释单元格中的选定行,再次命中组合将取消注释相同的代码行。
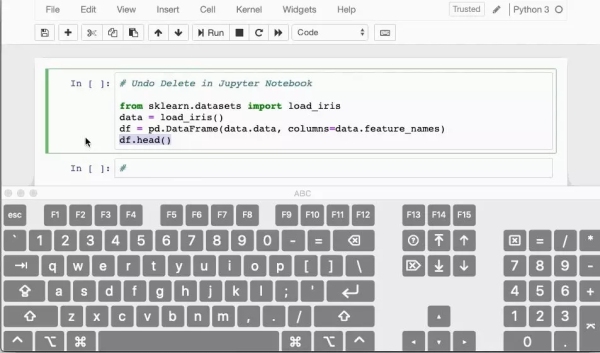
删除容易恢复难
你有没有意外删除过Jupyter notebook中的单元格?如果答案是肯定的,那么可以掌握这个撤消删除操作的快捷方式。
如果您删除了单元格的内容,可以通过按CTRL / CMD + Z轻松恢复它。
如果需要恢复整个已删除的单元格,请按ESC + Z或EDIT>撤消删除单元格。
结论
在本文中,我列出了使用Python和Jupyter notebook时收集的一些小提示。我相信它们会对你有用,能让你有所收获,从而实现轻松编码!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python实现连接postgresql数据库的方法分析
本文实例讲述了Python实现连接postgresql数据库的方法.分享给大家供大家参考,具体如下: python可以通过第三方模块连接postgresql. 比较有名的有psycopg2和python3-postgresql (一)psycopg2 ubuntu下安装 sudo apt-get install python3-psycopg2 创建一个test.py文件 import psycopg2 # 数据库连接参数 conn = psycopg2.connect(database="te
-
分享一下Python数据分析常用的8款工具
Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性.Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力. Python数据分析需要安装的第三方扩展库有:Numpy.Pandas.SciPy.Matplotlib.Scikit-Learn.Keras.Gensim.Scrapy等,以下是千锋武汉Python培训老师对该第三方扩展库的
-
利用python实现数据分析
1:文件内容格式为json的数据如何解析 import json,os,sys current_dir=os.path.abspath(".") filename=[file for file in os.listdir(current_dir) if ".txt" in file]#得到当前目录中,后缀为.txt的数据文件 fn=filename[0] if len(filename)==1 else "" #从list中取出第一个文件名 if
-
在MAC上搭建python数据分析开发环境
最近工作转型到数据开发领域,想在本地搭建一个数据开发环境.自己有三年python开发经验,马上想到使用numpy.scipy.sklearn.pandas搭建一套数据开发环境. ubuntu的环境,百度中文章比较多,搭建起来非常顺利.MAC环境的资料比较少,百度出来的,已经不对了,那我就来补充一篇吧. MAC自带python,python的安装我就不多说了. 安装pip 我喜欢用pip安装python库,非常方便,pip的安装只能用源码了. #下载源代码 https://pypi.python.
-

Python运用于数据分析的简单教程
最近,Analysis with Programming加入了Planet Python.作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析.具体内容如下: 数据导入 导入本地的或者web端的CSV文件: 数据变换: 数据统计描述: 假设检验 单样本t检验: 可视化: 创建自定义函数. 数据导入 这是很关键的一步,为了后续的分析我们首先需要导入数据.通常来说,数据是CSV格式,就算不是,至少也可以转
-
python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0,1]区间.方便数据的处理.消除单位影响及变异大小因素影响. 基本公式为: x'=(x-min)/(max-min) 代码: #!/user/bin/env python #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplo
-
Python数据可视化正态分布简单分析及实现代码
Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候... 正态分布(Normaldistribution),也称"常态分布",又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公式中得到.C.F.高斯在研究测量误差时从另一个角度导出了它.P.S.拉普拉斯和高斯研究了它的性质.是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力. 正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人
-
python连接MySQL数据库实例分析
本文实例讲述了python连接MySQL数据库的方法.分享给大家供大家参考.具体实现方法如下: import MySQLdb conn = MySQLdb.connect(host="localhost", user="root", passwd="123456", db="test") cursor = conn.cursor() cursor.execute("select * from hard")
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
详解10个可以快速用Python进行数据分析的小技巧
一些小提示和小技巧可能是非常有用的,特别是在编程领域.有时候使用一点点黑客技术,既可以节省时间,还可能挽救"生命". 一个小小的快捷方式或附加组件有时真是天赐之物,并且可以成为真正的生产力助推器.所以,这里有一些小提示和小技巧,有些可能是新的,但我相信在下一个数据分析项目中会让你非常方便. Pandas中数据框数据的Profiling过程 Profiling(分析器)是一个帮助我们理解数据的过程,而Pandas Profiling是一个Python包,它可以简单快速地对Pandas 的
-
详解JavaScript中if语句优化和部分语法糖小技巧推荐
目录 前言 if else 基本使用 简化if判断和优化代码 单行if else 使用&& || 优化 使用三目运算符优化 合并if 使用includes 或者indexof 使用switch流程 优化 多个if else 使用对象 key-value 优化多条if语句 使用map 推荐一些常用的JavaScript语法糖 箭头函数 三目运算符处理函数 函数默认参数处理 数据类型转换 Null.Undefined 布尔值等特殊值处理,使用||结合! 链判断运算符 链判断运算符 空值合并操作
-
详解小白之KMP算法及python实现
在看子串匹配问题的时候,书上的关于KMP的算法的介绍总是理解不了.看了一遍代码总是很快的忘掉,后来决定好好分解一下KMP算法,算是给自己加深印象. 在将KMP字串匹配问题的时候,我们先来回顾一下字串匹配的暴力解法: 假设字符串str为: "abcgbabcdh", 字串substr为: "abcd" 从第一个字符开始比较,显然两个字符串的第一个字符相等('a'=='a'),然后比较第二个字符也相等('b'=='b'),继续下去,我们发现第4个字符不相等了('g'!
-
详解基于Facecognition+Opencv快速搭建人脸识别及跟踪应用
人脸识别技术已经相当成熟,面对满大街的人脸识别应用,像单位门禁.刷脸打卡.App解锁.刷脸支付.口罩检测........ 作为一个图像处理的爱好者,怎能放过人脸识别这一环呢!调研开搞,发现了超实用的Facecognition!现在和大家分享下~~ Facecognition人脸识别原理大体可分为: 1.通过hog算子定位人脸,也可以用cnn模型,但本文没试过: 2.Dlib有专门的函数和模型,实现人脸68个特征点的定位.通过图像的几何变换(仿射.旋转.缩放),使各个特征点对齐(将眼睛.嘴等部位移
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策
-
Java版超大整数阶乘算法代码详解-10,0000级
当计算超过20以上的阶乘时,阶乘的结果值往往会很大.一个很小的数字的阶乘结果就可能超过目前个人计算机的整数范围.如果需求很大的阶乘,比如1000以上完全无法用简单的递归方式去解决.在网上我看到很多用C.C++和C#写的一些关于大整数阶乘的算法,其中不乏经典但也有很多粗糙的文章.数组越界,一眼就可以看出程序本身无法运行.转载他人文章的时候,代码倒是仔细看看啊.唉,粗糙.过年了,在家闲来蛋疼,仔细分析分析,用Java实现了一个程序计算超大整数阶乘.思想取自网上,由我个人优化和改进. 这个方法采用"数
-
详解如何在Java中调用Python程序
Java中调用Python程序 1.新建一个Maven工程,导入如下依赖 <dependency> <groupId>org.python</groupId> <artifactId>jython-standalone</artifactId> <version>2.7.0</version> </dependency> 2.在java中直接执行python代码片段 import org.python.util
-
详解非极大值抑制算法之Python实现
一.概述 这里不讨论通用的NMS算法(参考论文<Efficient Non-Maximum Suppression>对1维和2维数据的NMS实现),而是用于目标检测中提取分数最高的窗口的.例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数.但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况.这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口. NMS在计算机视觉领域有着非常重要的应用,如视频目标跟踪.数据挖掘
-
详解利用上下文管理器扩展Python计时器
目录 一个 Python 定时器上下文管理器 了解 Python 中的上下文管理器 理解并使用 contextlib 创建 Python 计时器上下文管理器 使用 Python 定时器上下文管理器 写在最后 上文中,我们一起学习了手把手教你实现一个 Python 计时器.本文中,云朵君将和大家一起了解什么是上下文管理器 和 Python 的 with 语句,以及如何完成自定义.然后扩展 Timer 以便它也可以用作上下文管理器.最后,使用 Timer 作为上下文管理器如何简化我们自己的代码. 上
-
图文详解梯度下降算法的原理及Python实现
目录 1.引例 2.数值解法 3.梯度下降算法 4.代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何通过计算机算法编程求f(x)min? 2.数值解法 传统方法是数值解法,如图所示 按照以下步骤迭代循环直至最优: ① 任意给定一个初值x0: ② 随机生成增量方向,结合步长生成Δx: ③ 计算比较f(x0)与f(x0+Δx)的大小,若f(x0+Δx)<f(x0)则更新位置,否则重新生成Δx: ④ 重复②③直至收敛到最优f(x)min. 数值解法最大的优点是编程简明,但缺陷也很