加速 PyTorch 模型训练的 9 个技巧(收藏)
目录
- Pytorch-Lightning
- 1.DataLoaders
- 2.DataLoaders中的workers的数量
- 3.Batchsize
- 4.梯度累加
- 5.保留的计算图
- 6.单个GPU训练
- 7.16-bit精度
- 8.移动到多个GPUs中
- 9.多节点GPU训练
- 10.福利!在单个节点上多GPU更快的训练
- 对模型加速的思考

让我们面对现实吧,你的模型可能还停留在石器时代。我敢打赌你仍然使用32位精度或GASP甚至只在一个GPU上训练。
我明白,网上都是各种神经网络加速指南,但是一个checklist都没有(现在有了),使用这个清单,一步一步确保你能榨干你模型的所有性能。
本指南从最简单的结构到最复杂的改动都有,可以使你的网络得到最大的好处。我会给你展示示例Pytorch代码以及可以在Pytorch- lightning Trainer中使用的相关flags,这样你可以不用自己编写这些代码!
**这本指南是为谁准备的?**任何使用Pytorch进行深度学习模型研究的人,如研究人员、博士生、学者等,我们在这里谈论的模型可能需要你花费几天的训练,甚至是几周或几个月。
我们会讲到:
使用DataLoaders
DataLoader中的workers数量
Batch size
梯度累计
保留的计算图
移动到单个
16-bit 混合精度训练
移动到多个GPUs中(模型复制)
移动到多个GPU-nodes中 (8+GPUs)
思考模型加速的技巧
Pytorch-Lightning

你可以在Pytorch的库Pytorch- lightning中找到我在这里讨论的每一个优化。Lightning是在Pytorch之上的一个封装,它可以自动训练,同时让研究人员完全控制关键的模型组件。Lightning 使用最新的最佳实践,并将你可能出错的地方最小化。
我们为MNIST定义LightningModel并使用Trainer来训练模型。
from pytorch_lightning import Trainer model = LightningModule(…) trainer = Trainer() trainer.fit(model)
1. DataLoaders

这可能是最容易获得速度增益的地方。保存h5py或numpy文件以加速数据加载的时代已经一去不复返了,使用Pytorch dataloader加载图像数据很简单(对于NLP数据,请查看TorchText)。
在lightning中,你不需要指定训练循环,只需要定义dataLoaders和Trainer就会在需要的时候调用它们。
dataset = MNIST(root=self.hparams.data_root, train=train, download=True) loader = DataLoader(dataset, batch_size=32, shuffle=True) for batch in loader: x, y = batch model.training_step(x, y) ...
2. DataLoaders 中的 workers 的数量

另一个加速的神奇之处是允许批量并行加载。因此,您可以一次装载nb_workers个batch,而不是一次装载一个batch。
# slow loader = DataLoader(dataset, batch_size=32, shuffle=True) # fast (use 10 workers) loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=10)
3. Batch size

在开始下一个优化步骤之前,将batch size增大到CPU-RAM或GPU-RAM所允许的最大范围。
下一节将重点介绍如何帮助减少内存占用,以便你可以继续增加batch size。
记住,你可能需要再次更新你的学习率。一个好的经验法则是,如果batch size加倍,那么学习率就加倍。
4. 梯度累加

在你已经达到计算资源上限的情况下,你的batch size仍然太小(比如8),然后我们需要模拟一个更大的batch size来进行梯度下降,以提供一个良好的估计。
假设我们想要达到128的batch size大小。我们需要以batch size为8执行16个前向传播和向后传播,然后再执行一次优化步骤。
# clear last step
optimizer.zero_grad()
# 16 accumulated gradient steps
scaled_loss = 0
for accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16
optimizer.step()
# loss is now scaled up by the number of accumulated batches
actual_loss = scaled_loss / 16
在lightning中,全部都给你做好了,只需要设置accumulate_grad_batches=16:
trainer = Trainer(accumulate_grad_batches=16) trainer.fit(model)
5. 保留的计算图

一个最简单撑爆你的内存的方法是为了记录日志存储你的loss。
losses = []
...
losses.append(loss)
print(f'current loss: {torch.mean(losses)'})
上面的问题是,loss仍然包含有整个图的副本。在这种情况下,调用.item()来释放它。
# bad losses.append(loss) # good losses.append(loss.item())
Lightning会非常小心,确保不会保留计算图的副本。
6. 单个GPU训练

一旦你已经完成了前面的步骤,是时候进入GPU训练了。在GPU上的训练将使多个GPU cores之间的数学计算并行化。你得到的加速取决于你所使用的GPU类型。我推荐个人用2080Ti,公司用V100。
乍一看,这可能会让你不知所措,但你真的只需要做两件事:1)移动你的模型到GPU, 2)每当你运行数据通过它,把数据放到GPU上。
# put model on GPU model.cuda(0) # put data on gpu (cuda on a variable returns a cuda copy) x = x.cuda(0) # runs on GPU now model(x)
如果你使用Lightning,你什么都不用做,只需要设置Trainer(gpus=1)。
# ask lightning to use gpu 0 for training trainer = Trainer(gpus=[0]) trainer.fit(model)
在GPU上进行训练时,要注意的主要事情是限制CPU和GPU之间的传输次数。
# expensive x = x.cuda(0)# very expensive x = x.cpu() x = x.cuda(0)
如果内存耗尽,不要将数据移回CPU以节省内存。在求助于GPU之前,尝试以其他方式优化你的代码或GPU之间的内存分布。
另一件需要注意的事情是调用强制GPU同步的操作。清除内存缓存就是一个例子。
# really bad idea. Stops all the GPUs until they all catch up torch.cuda.empty_cache()
但是,如果使用Lightning,惟一可能出现问题的地方是在定义Lightning Module时。Lightning会特别注意不去犯这类错误。
7. 16-bit 精度
16bit精度是将内存占用减半的惊人技术。大多数模型使用32bit精度数字进行训练。然而,最近的研究发现,16bit模型也可以工作得很好。混合精度意味着对某些内容使用16bit,但将权重等内容保持在32bit。
要在Pytorch中使用16bit精度,请安装NVIDIA的apex库,并对你的模型进行这些更改。
# enable 16-bit on the model and the optimizer
model, optimizers = amp.initialize(model, optimizers, opt_level='O2')
# when doing .backward, let amp do it so it can scale the loss
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
amp包会处理好大部分事情。如果梯度爆炸或趋向于0,它甚至会缩放loss。
在lightning中,启用16bit并不需要修改模型中的任何内容,也不需要执行我上面所写的操作。设置Trainer(precision=16)就可以了。
trainer = Trainer(amp_level='O2', use_amp=False) trainer.fit(model)
8. 移动到多个GPUs中
现在,事情变得非常有趣了。有3种(也许更多?)方法来进行多GPU训练。
分batch训练

A) 拷贝模型到每个GPU中,B) 给每个GPU一部分batch
第一种方法被称为“分batch训练”。该策略将模型复制到每个GPU上,每个GPU获得batch的一部分。
# copy model on each GPU and give a fourth of the batch to each model = DataParallel(model, devices=[0, 1, 2 ,3]) # out has 4 outputs (one for each gpu) out = model(x.cuda(0))
在lightning中,你只需要增加GPUs的数量,然后告诉trainer,其他什么都不用做。
# ask lightning to use 4 GPUs for training trainer = Trainer(gpus=[0, 1, 2, 3]) trainer.fit(model)
模型分布训练
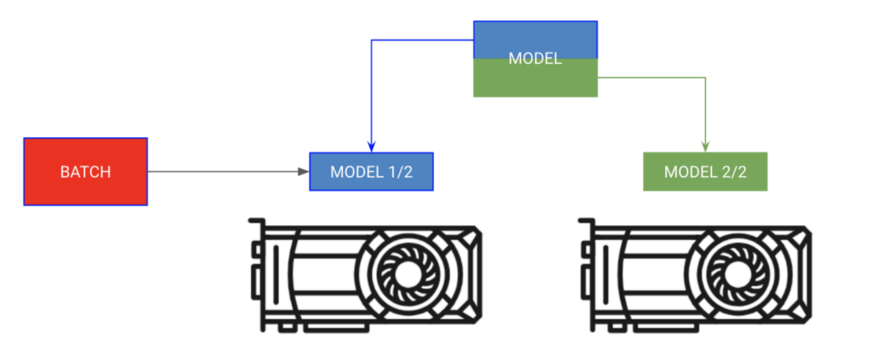
将模型的不同部分放在不同的GPU上,batch按顺序移动
有时你的模型可能太大不能完全放到内存中。例如,带有编码器和解码器的序列到序列模型在生成输出时可能会占用20GB RAM。在本例中,我们希望将编码器和解码器放在独立的GPU上。
# each model is sooo big we can't fit both in memory encoder_rnn.cuda(0) decoder_rnn.cuda(1) # run input through encoder on GPU 0 encoder_out = encoder_rnn(x.cuda(0)) # run output through decoder on the next GPU out = decoder_rnn(encoder_out.cuda(1)) # normally we want to bring all outputs back to GPU 0 out = out.cuda(0)
对于这种类型的训练,在Lightning中不需要指定任何GPU,你应该把LightningModule中的模块放到正确的GPU上。
class MyModule(LightningModule):
def __init__():
self.encoder = RNN(...)
self.decoder = RNN(...)
def forward(x):
# models won't be moved after the first forward because
# they are already on the correct GPUs
self.encoder.cuda(0)
self.decoder.cuda(1)
out = self.encoder(x)
out = self.decoder(out.cuda(1))
# don't pass GPUs to trainer
model = MyModule()
trainer = Trainer()
trainer.fit(model)
两者混合
在上面的情况下,编码器和解码器仍然可以从并行化操作中获益。
# change these lines self.encoder = RNN(...) self.decoder = RNN(...) # to these # now each RNN is based on a different gpu set self.encoder = DataParallel(self.encoder, devices=[0, 1, 2, 3]) self.decoder = DataParallel(self.encoder, devices=[4, 5, 6, 7]) # in forward... out = self.encoder(x.cuda(0)) # notice inputs on first gpu in device sout = self.decoder(out.cuda(4)) # <--- the 4 here
使用多个GPU时要考虑的注意事项:
- 如果模型已经在GPU上了,model.cuda()不会做任何事情。
- 总是把输入放在设备列表中的第一个设备上。
- 在设备之间传输数据是昂贵的,把它作为最后的手段。
- 优化器和梯度会被保存在GPU 0上,因此,GPU 0上使用的内存可能会比其他GPU大得多。
9. 多节点GPU训练
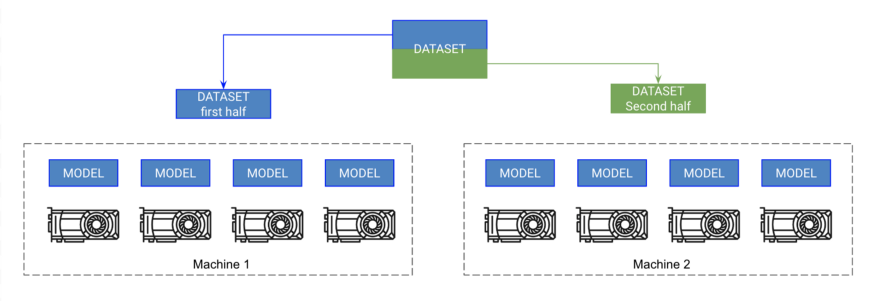
每台机器上的每个GPU都有一个模型的副本。每台机器获得数据的一部分,并且只在那部分上训练。每台机器都能同步梯度。
如果你已经做到了这一步,那么你现在可以在几分钟内训练Imagenet了!这并没有你想象的那么难,但是它可能需要你对计算集群的更多知识。这些说明假设你正在集群上使用SLURM。
Pytorch允许多节点训练,通过在每个节点上复制每个GPU上的模型并同步梯度。所以,每个模型都是在每个GPU上独立初始化的,本质上独立地在数据的一个分区上训练,除了它们都从所有模型接收梯度更新。
在高层次上:
- 在每个GPU上初始化一个模型的副本(确保设置种子,让每个模型初始化到相同的权重,否则它会失败)。
- 将数据集分割成子集(使用DistributedSampler)。每个GPU只在它自己的小子集上训练。
- 在.backward()上,所有副本都接收到所有模型的梯度副本。这是模型之间唯一一次的通信。
Pytorch有一个很好的抽象,叫做DistributedDataParallel,它可以帮你实现这个功能。要使用DDP,你需要做4的事情:
def tng_dataloader():
d = MNIST()
# 4: Add distributed sampler
# sampler sends a portion of tng data to each machine
dist_sampler = DistributedSampler(dataset)
dataloader = DataLoader(d, shuffle=False, sampler=dist_sampler)
def main_process_entrypoint(gpu_nb):
# 2: set up connections between all gpus across all machines
# all gpus connect to a single GPU "root"
# the default uses env://
world = nb_gpus * nb_nodes
dist.init_process_group("nccl", rank=gpu_nb, world_size=world)
# 3: wrap model in DPP
torch.cuda.set_device(gpu_nb)
model.cuda(gpu_nb)
model = DistributedDataParallel(model, device_ids=[gpu_nb])
# train your model now...
if __name__ == '__main__':
# 1: spawn number of processes
# your cluster will call main for each machine
mp.spawn(main_process_entrypoint, nprocs=8)
然而,在Lightning中,只需设置节点数量,它就会为你处理其余的事情。
# train on 1024 gpus across 128 nodes trainer = Trainer(nb_gpu_nodes=128, gpus=[0, 1, 2, 3, 4, 5, 6, 7])
Lightning还附带了一个SlurmCluster管理器,可以方便地帮助你提交SLURM作业的正确详细信息。
10. 福利!在单个节点上多GPU更快的训练
事实证明,distributedDataParallel比DataParallel快得多,因为它只执行梯度同步的通信。所以,一个好的hack是使用distributedDataParallel替换DataParallel,即使是在单机上进行训练。
在Lightning中,这很容易通过将distributed_backend设置为ddp和设置GPUs的数量来实现。
# train on 4 gpus on the same machine MUCH faster than DataParallel trainer = Trainer(distributed_backend='ddp', gpus=[0, 1, 2, 3])
对模型加速的思考
尽管本指南将为你提供了一系列提高网络速度的技巧,但我还是要给你解释一下如何通过查找瓶颈来思考问题。
我将模型分成几个部分:
首先,我要确保在数据加载中没有瓶颈。为此,我使用了我所描述的现有数据加载解决方案,但是如果没有一种解决方案满足你的需要,请考虑离线处理和缓存到高性能数据存储中,比如h5py。
接下来看看你在训练步骤中要做什么。确保你的前向传播速度快,避免过多的计算以及最小化CPU和GPU之间的数据传输。最后,避免做一些会降低GPU速度的事情(本指南中有介绍)。
接下来,我试图最大化我的batch size,这通常是受GPU内存大小的限制。现在,需要关注在使用大的batch size的时候如何在多个GPUs上分布并最小化延迟(比如,我可能会尝试着在多个gpu上使用8000 +的有效batch size)。
然而,你需要小心大的batch size。针对你的具体问题,请查阅相关文献,看看人们都忽略了什么!
到此这篇关于加速 PyTorch 模型训练的 9 个技巧的文章就介绍到这了,更多相关PyTorch 模型训练内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pytorch fine-tune 预训练的模型操作
之一: torchvision 中包含了很多预训练好的模型,这样就使得 fine-tune 非常容易.本文主要介绍如何 fine-tune torchvision 中预训练好的模型. 安装 pip install torchvision 如何 fine-tune 以 resnet18 为例: from torchvision import models from torch import nn from torch import optim resnet_model = models.resne
-
pytorch 预训练模型读取修改相关参数的填坑问题
pytorch 预训练模型读取修改相关参数的填坑 修改部分层,仍然调用之前的模型参数. resnet = resnet50(pretrained=False) resnet.load_state_dict(torch.load(args.predir)) res_conv31 = Bottleneck_dilated(1024, 256,dilated_rate = 2) print("---------------------",res_conv31) print("---
-
PyTorch预训练Bert模型的示例
本文介绍以下内容: 1. 使用transformers框架做预训练的bert-base模型: 2. 开发平台使用Google的Colab平台,白嫖GPU加速: 3. 使用datasets模块下载IMDB影评数据作为训练数据. transformers模块简介 transformers框架为Huggingface开源的深度学习框架,支持几乎所有的Transformer架构的预训练模型.使用非常的方便,本文基于此框架,尝试一下预训练模型的使用,简单易用. 本来打算预训练bert-large模型,发现
-
解决Pytorch修改预训练模型时遇到key不匹配的情况
一.Pytorch修改预训练模型时遇到key不匹配 最近想着修改网络的预训练模型vgg.pth,但是发现当我加载预训练模型权重到新建的模型并保存之后. 在我使用新赋值的网络模型时出现了key不匹配的问题 #加载后保存(未修改网络) base_weights = torch.load(args.save_folder + args.basenet) ssd_net.vgg.load_state_dict(base_weights) torch.save(ssd_net.state_dict(),
-
Pytorch训练模型得到输出后计算F1-Score 和AUC的操作
1.计算F1-Score 对于二分类来说,假设batch size 大小为64的话,那么模型一个batch的输出应该是torch.size([64,2]),所以首先做的是得到这个二维矩阵的每一行的最大索引值,然后添加到一个列表中,同时把标签也添加到一个列表中,最后使用sklearn中计算F1的工具包进行计算,代码如下 import numpy as np import sklearn.metrics import f1_score prob_all = [] lable_all = [] for
-
pytorch加载预训练模型与自己模型不匹配的解决方案
pytorch中如果自己搭建网络并且加载别人的与训练模型的话,如果模型和参数不严格匹配,就可能会出问题,接下来记录一下我的解决方法. 两个有序字典找不同 模型的参数和pth文件的参数都是有序字典(OrderedDict),把字典中的键转为列表就可以在for循环里迭代找不同了. model = ResNet18(1) model_dict1 = torch.load('resnet18.pth') model_dict2 = model.state_dict() model_list1 = lis
-
PyTorch 迁移学习实践(几分钟即可训练好自己的模型)
前言 如果你认为深度学习非常的吃GPU,或者说非常的耗时间,训练一个模型要非常久,但是你如果了解了迁移学习那你的模型可能只需要几分钟,而且准确率不比你自己训练的模型准确率低,本节我们将会介绍两种方法来实现迁移学习 迁移学习方法介绍 微调网络的方法实现迁移学习,更改最后一层全连接,并且微调训练网络 将模型看成特征提取器,如果一个模型的预训练模型非常的好,那完全就把前面的层看成特征提取器,冻结所有层并且更改最后一层,只训练最后一层,这样我们只训练了最后一层,训练会非常的快速 迁移基本步骤 数据的准备
-
加速 PyTorch 模型训练的 9 个技巧(收藏)
目录 Pytorch-Lightning 1.DataLoaders 2.DataLoaders中的workers的数量 3.Batchsize 4.梯度累加 5.保留的计算图 6.单个GPU训练 7.16-bit精度 8.移动到多个GPUs中 9.多节点GPU训练 10.福利!在单个节点上多GPU更快的训练 对模型加速的思考 让我们面对现实吧,你的模型可能还停留在石器时代.我敢打赌你仍然使用32位精度或GASP甚至只在一个GPU上训练. 我明白,网上都是各种神经网络加速指南,但是一个check
-
解决pytorch 模型复制的一些问题
直接使用 model2=model1 会出现当更新model2时,model1的权重也会更新,这和自己的初始目的不同. 经评论指出可以使用: model2=copy.deepcopy(model1) 来实现深拷贝,手上没有pytorch环境,具体还没测试过,谁测试过可以和我说下有没有用. 原方法: 所有要使用模型复制可以使用如下方法. torch.save(model, "net_params.pkl") model5=Cnn(3,10) model5=torch.load('net_
-
AMP Tensor Cores节省内存PyTorch模型详解
目录 导读 什么是Tensor Cores? 那么,我们如何使用Tensor Cores? 使用PyTorch进行混合精度训练: 基准测试 导读 只需要添加几行代码,就可以得到更快速,更省显存的PyTorch模型. 你知道吗,在1986年Geoffrey Hinton就在Nature论文中给出了反向传播算法? 此外,卷积网络最早是由Yann le cun在1998年提出的,用于数字分类,他使用了一个卷积层.但是直到2012年晚些时候,Alexnet才通过使用多个卷积层来实现最先进的imagene
-
将Pytorch模型从CPU转换成GPU的实现方法
最近将Pytorch程序迁移到GPU上去的一些工作和思考 环境:Ubuntu 16.04.3 Python版本:3.5.2 Pytorch版本:0.4.0 0. 序言 大家知道,在深度学习中使用GPU来对模型进行训练是可以通过并行化其计算来提高运行效率,这里就不多谈了. 最近申请到了实验室的服务器来跑程序,成功将我简陋的程序改成了"高大上"GPU版本. 看到网上总体来说少了很多介绍,这里决定将我的一些思考和工作记录下来. 1. 如何进行迁移 由于我使用的是Pytorch写的模型,网上给
-
把vgg-face.mat权重迁移到pytorch模型示例
最近使用pytorch时,需要用到一个预训练好的人脸识别模型提取人脸ID特征,想到很多人都在用用vgg-face,但是vgg-face没有pytorch的模型,于是写个vgg-face.mat转到pytorch模型的代码 #!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Thu May 10 10:41:40 2018 @author: hy """ import torc
-
基于pytorch 预训练的词向量用法详解
如何在pytorch中使用word2vec训练好的词向量 torch.nn.Embedding() 这个方法是在pytorch中将词向量和词对应起来的一个方法. 一般情况下,如果我们直接使用下面的这种: self.embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=embeding_dim) num_embeddings=vocab_size 表示词汇量的大小 embedding_dim=embeding
-
pytorch 模型的train模式与eval模式实例
原因 对于一些含有batch normalization或者是Dropout层的模型来说,训练时的froward和验证时的forward有计算上是不同的,因此在前向传递过程中需要指定模型是在训练还是在验证. 源代码 [docs] def train(self, mode=True): r"""Sets the module in training mode. This has any effect only on certain modules. See documentat
-
记录模型训练时loss值的变化情况
记录训练过程中的每一步的loss变化 if verbose and step % verbose == 0: sys.stdout.write('\r{} / {} : loss = {}'.format( step, total_steps, np.mean(total_loss))) sys.stdout.flush() if verbose: sys.stdout.write('\r') sys.stdout.flush() 一般我们在训练神经网络模型的时候,都是每隔多少步,输出打印一下l
-
可视化pytorch 模型中不同BN层的running mean曲线实例
加载模型字典 逐一判断每一层,如果该层是bn 的 running mean,就取出参数并取平均作为该层的代表 对保存的每个BN层的数值进行曲线可视化 from functools import partial import pickle import torch import matplotlib.pyplot as plt pth_path = 'checkpoint.pth' pickle.load = partial(pickle.load, encoding="latin1")