Stream性能差?不要人云亦云
目录
一、粉丝的反馈

问:stream比for循环慢5倍,用这个是为了啥? 答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生。作为一个技术开发者,要自己去动手去做,不要人云亦云。
的确,这位粉丝说的这篇文章我也看过,我就不贴地址了,也没必要给他带流量。怎么说呢?就是一个不懂得测试的、不入流开发工程师做的性能测试,给出了一个危言耸听的结论。
二、所有性能测试结论都是片面的
性能测试是必要的,但针对性能测试的结果,永远要持怀疑态度。为什么这么说?
性能测试脱离业务场景就是片面的性能测试。你能覆盖所有的业务场景么?性能测试脱离硬件环境就是片面的性能测试。你能覆盖所有的硬件环境么?性能测试脱离开发人员的知识面就是片面的性能测试。你能覆盖各种开发人员奇奇怪怪的代码么?
所以,我从来不相信网上的任何性能测试的文章。凡是我自己的从事的业务场景,我都要在接近生产环境的机器上自己测试一遍。 所有性能测试结论都是片面的,只有你生产环境下的运行结果才是真的。
三、动手测试Stream的性能
3.1.环境
windows10 、16G内存、i7-7700HQ 2.8HZ 、64位操作系统、JDK 1.8.0_171
3.2.测试用例与测试结论
我们在上一节,已经讲过:
windows10 、16G内存、i7-7700HQ 2.8HZ 、64位操作系统、JDK 1.8.0_171
3.2.测试用例与测试结论
我们在上一节,已经讲过:
针对不同的数据结构,Stream流的执行效率是不一样的针对不同的数据源,Stream流的执行效率也是不一样的
所以记住笔者的话:所有性能测试结论都是片面的,你要自己动手做,相信你自己的代码和你的环境下的测试!我的测试结果仅仅代表我自己的测试用例和测试数据结构!
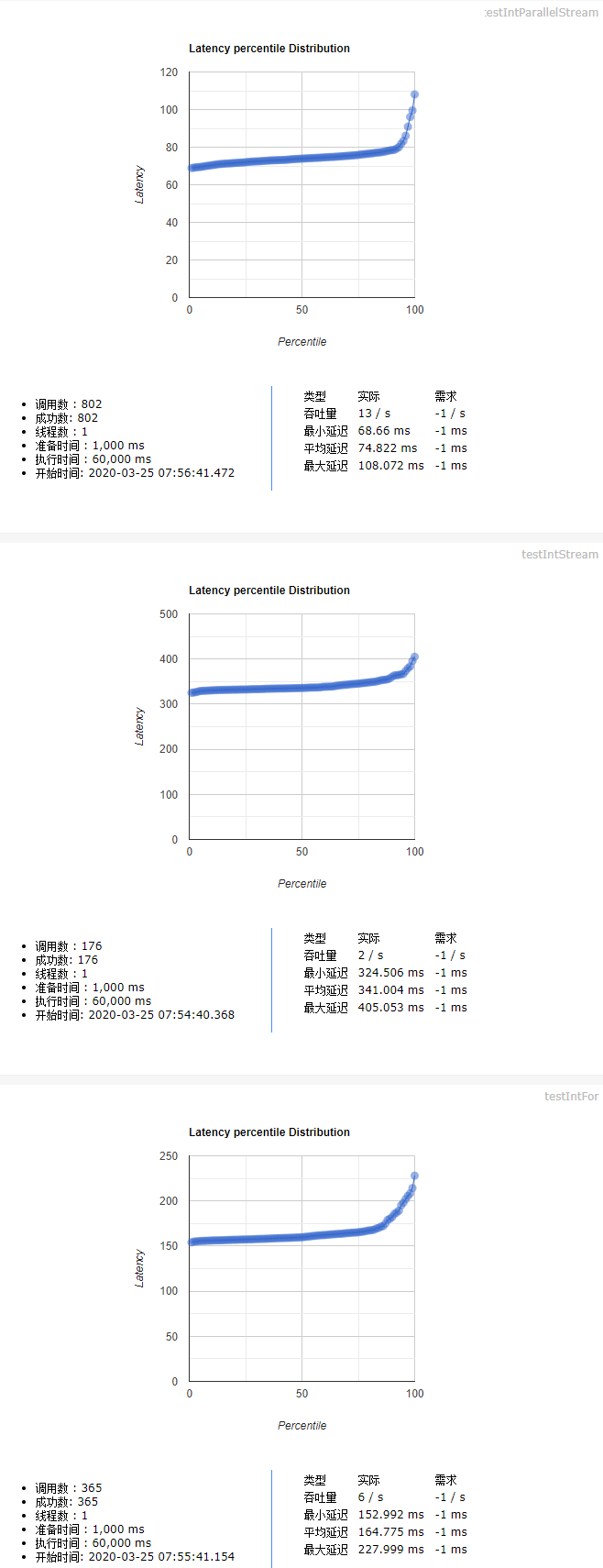
3.2.1.测试用例一
测试用例:5亿个int随机数,求最小值 测试结论(测试代码见后文):
使用普通for循环,执行效率是Stream串行流的2倍。也就是说普通for循环性能更好。Stream并行流计算是普通for循环执行效率的4-5倍。Stream并行流计算 > 普通for循环 > Stream串行流计算
3.2.测试用例二
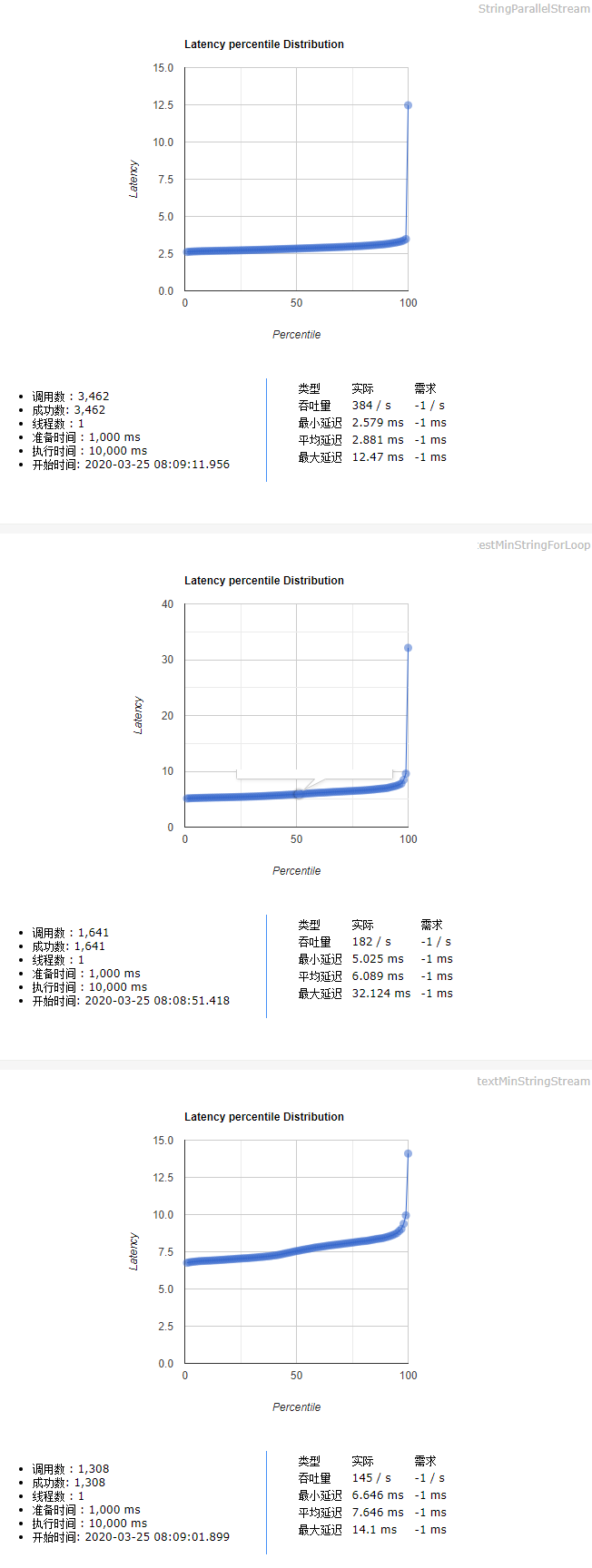
测试用例:长度为10的1000000随机字符串,求最小值 测试结论(测试代码见后文):
普通for循环执行效率与Stream串行流不相上下Stream并行流的执行效率远高于普通for循环Stream并行流计算 > 普通for循环 = Stream串行流计算
3.3.测试用例三
测试用例:10个用户,每人200个订单。按用户统计订单的总价。 测试结论(测试代码见后文):
Stream并行流的执行效率远高于普通for循环Stream串行流的执行效率大于等于普通for循环Stream并行流计算 > Stream串行流计算 >= 普通for循环 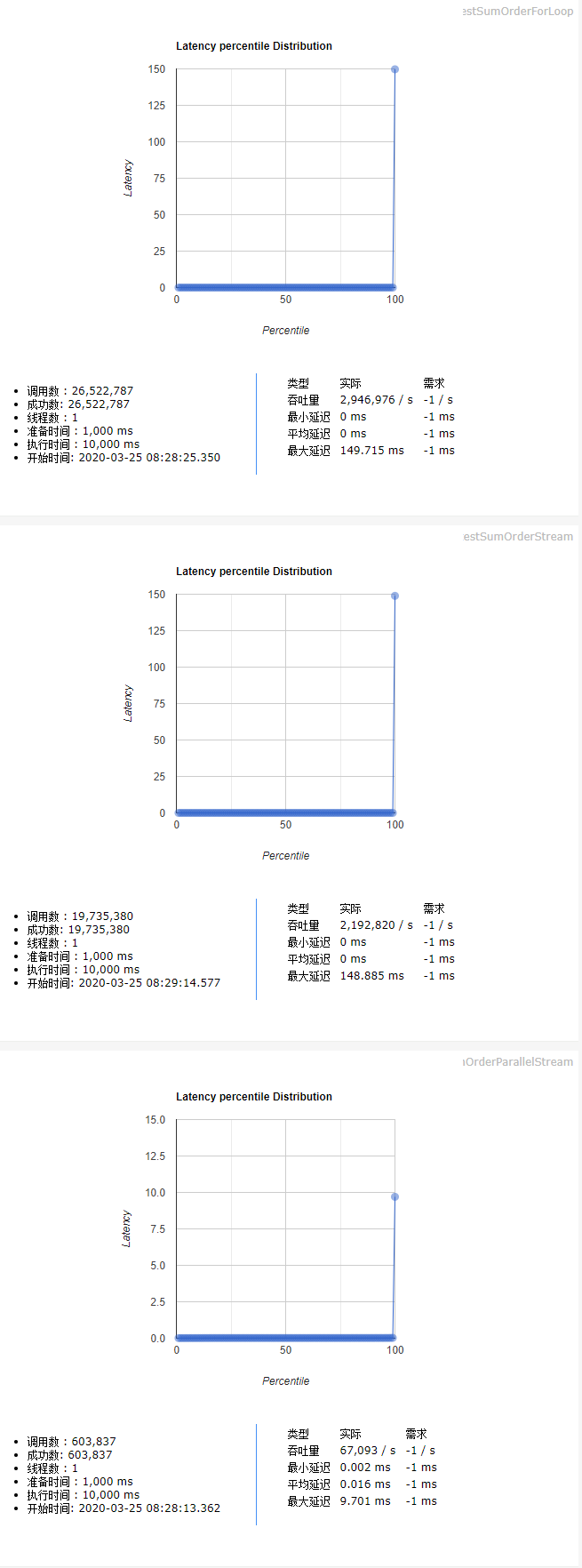
四、最终测试结论 对于简单的数字(list-Int)遍历,普通for循环效率的确比Stream串行流执行效率高(1.5-2.5倍)。但是Stream流可以利用并行执行的方式发挥CPU的多核优势,因此并行流计算执行效率高于for循环。对于list-Object类型的数据遍历,普通for循环和Stream串行流比也没有任何优势可言,更不用提Stream并行流计算。
虽然在不同的场景、不同的数据结构、不同的硬件环境下。Stream流与for循环性能测试结果差异较大,甚至发生逆转。但是总体上而言:
Stream并行流计算 >> 普通for循环 ~= Stream串行流计算 (之所以用两个大于号,你细品)数据容量越大,Stream流的执行效率越高。Stream并行流计算通常能够比较好的利用CPU的多核优势。CPU核心越多,Stream并行流计算效率越高。
stream比for循环慢5倍?也许吧,单核CPU、串行Stream的int类型数据遍历?我没试过这种场景,但是我知道这不是应用系统的核心场景。看了十几篇测试博文,和我的测试结果。我的结论是: 在大多数的核心业务场景下及常用数据结构下,Stream的执行效率比for循环更高。 毕竟我们的业务中通常是实实在在的实体对象,没事谁总对List<Int>类型进行遍历?谁的生产服务器是单核?。
五、测试代码
<dependency> <groupId>com.github.houbb</groupId> <artifactId>junitperf</artifactId> <version>2.0.0</version></dependency>
<dependency> <groupId>com.github.houbb</groupId> <artifactId>junitperf</artifactId> <version>2.0.0</version></dependency>测试用例一:
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;import com.github.houbb.junitperf.core.report.impl.HtmlReporter;import org.junit.jupiter.api.BeforeAll;import java.util.Arrays;import java.util.Random;public class StreamIntTest { public static int[] arr; @BeforeAll public static void init() { arr = new int[500000000]; //5亿个随机Int randomInt(arr); } @JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class}) public void testIntFor() { minIntFor(arr); } @JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class}) public void testIntParallelStream() { minIntParallelStream(arr); } @JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class}) public void testIntStream() { minIntStream(arr); } private int minIntStream(int[] arr) { return Arrays.stream(arr).min().getAsInt(); } private int minIntParallelStream(int[] arr) { return Arrays.stream(arr).parallel().min().getAsInt(); } private int minIntFor(int[] arr) { int min = Integer.MAX_VALUE; for (int anArr : arr) { if (anArr < min) { min = anArr; } } return min; } private static void randomInt(int[] arr) { Random r = new Random(); for (int i = 0; i < arr.length; i++) { arr[i] = r.nextInt(); } }}测试用例二:
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;import com.github.houbb.junitperf.core.report.impl.HtmlReporter;import org.junit.jupiter.api.BeforeAll;import java.util.ArrayList;import java.util.Random;public class StreamStringTest { public static ArrayList<String> list; @BeforeAll public static void init() { list = randomStringList(1000000); } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void testMinStringForLoop(){ String minStr = null; boolean first = true; for(String str : list){ if(first){ first = false; minStr = str; } if(minStr.compareTo(str)>0){ minStr = str; } } } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void textMinStringStream(){ list.stream().min(String::compareTo).get(); } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void testMinStringParallelStream(){ list.stream().parallel().min(String::compareTo).get(); } private static ArrayList<String> randomStringList(int listLength){ ArrayList<String> list = new ArrayList<>(listLength); Random rand = new Random(); int strLength = 10; StringBuilder buf = new StringBuilder(strLength); for(int i=0; i<listLength; i++){ buf.delete(0, buf.length()); for(int j=0; j<strLength; j++){ buf.append((char)('a'+ rand.nextInt(26))); } list.add(buf.toString()); } return list; }}测试用例三:
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;import com.github.houbb.junitperf.core.report.impl.HtmlReporter;import org.junit.jupiter.api.BeforeAll;import java.util.*;import java.util.stream.Collectors;public class StreamObjectTest { public static List<Order> orders; @BeforeAll public static void init() { orders = Order.genOrders(10); } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void testSumOrderForLoop(){ Map<String, Double> map = new HashMap<>(); for(Order od : orders){ String userName = od.getUserName(); Double v; if((v=map.get(userName)) != null){ map.put(userName, v+od.getPrice()); }else{ map.put(userName, od.getPrice()); } } } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void testSumOrderStream(){ orders.stream().collect( Collectors.groupingBy(Order::getUserName, Collectors.summingDouble(Order::getPrice))); } @JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class}) public void testSumOrderParallelStream(){ orders.parallelStream().collect( Collectors.groupingBy(Order::getUserName, Collectors.summingDouble(Order::getPrice))); }}class Order{ private String userName; private double price; private long timestamp; public Order(String userName, double price, long timestamp) { this.userName = userName; this.price = price; this.timestamp = timestamp; } public String getUserName() { return userName; } public double getPrice() { return price; } public long getTimestamp() { return timestamp; } public static List<Order> genOrders(int listLength){ ArrayList<Order> list = new ArrayList<>(listLength); Random rand = new Random(); int users = listLength/200;// 200 orders per user users = users==0 ? listLength : users; ArrayList<String> userNames = new ArrayList<>(users); for(int i=0; i<users; i++){ userNames.add(UUID.randomUUID().toString()); } for(int i=0; i<listLength; i++){ double price = rand.nextInt(1000); String userName = userNames.get(rand.nextInt(users)); list.add(new Order(userName, price, System.nanoTime())); } return list; } @Override public String toString(){ return userName + "::" + price; }}欢迎关注我的博客,里面有很多精品合集 本文转载注明出处(必须带连接,不能只转文字):字母哥博客。
觉得对您有帮助的话,帮我点赞、分享!您的支持是我不竭的创作动力! 。另外,笔者最近一段时间输出了如下的精品内容,期待您的关注。
《手摸手教你学Spring Boot2.0》《Spring Security-JWT-OAuth2一本通》《实战前后端分离RBAC权限管理系统》《实战SpringCloud微服务从青铜到王者》《VUE深入浅出系列》
相关推荐
-
Java8新特性Stream的完全使用指南
什么是Stream Stream是Java 1.8版本开始提供的一个接口,主要提供对数据集合使用流的方式进行操作,流中的元素不可变且只会被消费一次,所有方法都设计成支持链式调用.使用Stream API可以极大生产力,写出高效率.干净.简洁的代码. 如何获得Stream实例 Stream提供了静态构建方法,可以基于不同的参数创建返回Stream实例 使用Collection的子类实例调用stream()或者parallelStream()方法也可以得到Stream实例,两个方法的区别在于后续执行
-
Java8中流的性能及流的几个特性
摘要:本文介绍了Java8中流的几个特性,以告诫开发者流并不是高性能的代名词,需谨慎使用流.以下是译文. 流(Stream)是Java8为了实现最佳性能而引入的一个全新的概念.在过去的几年中,随着硬件的持续发展,编程方式已经发生了巨大的改变,程序的性能也随着并行处理.实时.云和其他一些编程方法的出现而得到了不断提高. Java8中,流性能的提升是通过并行化(parallelism).惰性(Laziness)和短路操作(short-circuit operations)来实现的.但它也有一个缺点,
-
Java 8 Stream流强大的原理
目录 1.Stream的组成与特点 2.BaseStream接口 3.Stream接口 4.关闭流操作 5.并行流和串行流 6.ParallelStream背后的男人:ForkJoinPool 7.用ForkJoinPool的眼光来看ParallelStream 8.并行流的性能 9.NQ模型 10.遇到顺序 前言: Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象. Stream API可以极大提高Java程序员的生产力,让程
-
java8新特性之stream的collect实战教程
1.list转换成list 不带return方式 List<Long> ids=wrongTmpList.stream().map(c->c.getId()).collect(Collectors.toList()); 带return方式 // spu集合转化成spubo集合//java8的新特性 List<SpuBo> spuBos=spuList.stream().map(spu -> { SpuBo spuBo = new SpuBo(); BeanUtils.c
-
java8中parallelStream性能测试及结果分析
测试1 @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @Warmup(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS) @Measurement(iterations = 20, time = 3, timeUnit = TimeUnit.SECONDS) @Fork(1) @State(Scope.Benchmark) public cla
-

Stream性能差?不要人云亦云
目录 一.粉丝的反馈 问:stream比for循环慢5倍,用这个是为了啥? 答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生.作为一个技术开发者,要自己去动手去做,不要人云亦云. 的确,这位粉丝说的这篇文章我也看过,我就不贴地址了,也没必要给他带流量.怎么说呢?就是一个不懂得测试的.不入流开发工程师做的性能测试,给出了一个危言耸听的结论. 二.所有性能测试结论都是片面的 性能测试是必要的,但针对性能测试的结果,永远要持怀疑态度.为什么这么说? 性能测试脱离业务场景就是片面的性能测
-
java理论基础Stream性能论证测试示例
目录 一.粉丝的反馈 二.所有性能测试结论都是片面的 三.动手测试Stream的性能 3.1.环境 3.2.测试用例与测试结论 3.2.1.测试用例一 3.2.2测试用例二 3.2.3测试用例三 四.最终测试结论 五.测试代码 测试用例一: 测试用例二: 测试用例三: 一.粉丝的反馈 问:stream比for循环慢5倍,用这个是为了啥? 答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生.作为一个技术开发者,要自己去动手去做,不要人云亦云. 的确,这位粉丝说的这篇文章我也看过,我就
-
MySQL 查询速度慢与性能差的原因与解决方法
一.什么影响了数据库查询速度 1.1 影响数据库查询速度的四个因素 1.2 风险分析 QPS: QueriesPerSecond意思是"每秒查询率",是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准. TPS: 是 TransactionsPerSecond的缩写,也就是事务数/秒.它是软件测试结果的测量单位.客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数. Tips: 最好不要在主库上数据库备
-
SQLServer 2000 升级到 SQLServer 2008 性能之需要注意的地方之一
测试sql: 复制代码 代码如下: SET STATISTICS IO ON SET STATISTICS TIME ON SELECT COUNT(1) FROM dbo.tbtext a INNER LOOP JOIN dbo.tbtext b ON a.id = b.id option (maxdop 1) SET STATISTICS IO Off SET STATISTICS TIME Off 表结构: 复制代码 代码如下: CREATE TABLE [dbo].[tbtext]( [
-
Java 并行数据处理和性能分析
并行流 并行流是一个把元素分成多个块的流,每个块用不同的线程处理.可以自动分区,让所有的处理器都忙起来. 假设要写一个方法,接受一个数量n做参数,计算1-n的和.可以这样实现: public long sequentialSum(long n) { return Stream.iterate(1L, i -> i + 1) .limit(n) .reduce(0L, Long::sum); } 也许可以使用parallel方法,简单地使用并行计算,提高程序性能: public long sequ
-
Java中关于size()>0 和isEmpt()的性能考量
目录 size()>0和isEmpt()性能考量 以下内容是社区里的结论 list.size()>0&&list!=null和list!=null&&list.size()>0区别 使用场合 区别 size()>0 和isEmpt()性能考量 为何要写这篇呢?主要是要纠正一个长期以来的误区:size()>0 一定比isEmpt()性能差. 以下内容是社区里的结论 方法一(数据量大,效率低):if(list!=null && li
-
Java8中Stream的使用方式
目录 前言: 1. 为什么有经验的老手更倾向于使用Stream 2. Stream 的使用方式 3. Stream 的创建 4. Stream 中间操作 5. Stream 终止操作 6. Stream 特性 前言: 相信有很多刚刚入坑程序员的小伙伴被一些代码搞的很头疼,这些代码让我们既感觉到很熟悉,又很陌生的感觉.我们很多刚入行的朋友更习惯于使用for循环或是迭代器去解决一些遍历的问题,但公司里很多老油子喜欢使用Java8新特性Stream流去做,这样可以用更短的代码实现需求,但是对于不熟悉的
-
浅析SQL Server的分页方式 ISNULL与COALESCE性能比较
前言 上一节我们讲解了数据类型以及字符串中几个需要注意的地方,这节我们继续讲讲字符串行数同时也讲其他内容和穿插的内容,简短的内容,深入的讲解.(可参看文章<详解SQL Server中的数据类型>) 分页方式 在SQL 2005或者SQL 2008中我们是利用ROW_NUMBER开窗函数来进行分页的,关于开窗函数,我们在SQL进阶中会详细讲讲.如下: USE TSQL2012 GO DECLARE @StartRow INT DECLARE @EndRow INT SET @StartRow =
-
MySQL 性能优化的最佳20多条经验分享
当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能.这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库.希望下面的这些优化技巧对你有用. 1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了. 这里最主要