pytorch 把图片数据转化成tensor的操作
摘要:
在图像识别当中,一般步骤是先读取图片,然后把图片数据转化成tensor格式,再输送到网络中去。本文将介绍如何把图片转换成tensor。
一、数据转换
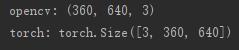
把图片转成成torch的tensor数据,一般采用函数:torchvision.transforms。通过一个例子说明,先用opencv读取一张图片,然后在转换;注意一点是:opencv储存图片的格式和torch的储存方式不一样,opencv储存图片格式是(H,W,C),而torch储存的格式是(C,H,W)。
import torchvision.transforms as transforms
import cv2 as cv
img = cv.imread('image/000001.jpg')
print(img.shape) # numpy数组格式为(H,W,C)
transf = transforms.ToTensor()
img_tensor = transf(img) # tensor数据格式是torch(C,H,W)
print(img_tensor.size())
注意:使用torchvision.transforms时要注意一下,其子函数 ToTensor() 是没有参数输入的,以下用法是会报错的
img_tensor = transforms.ToTensor(img)
必须是先定义和赋值转换函数,再调用并输入参数,正确用法:
img = cv.imread('image/000001.jpg')
transf = transforms.ToTensor()
img_tensor = transf(img)
再转换过程中正则化
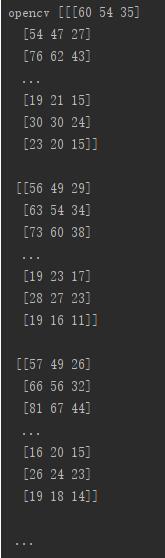
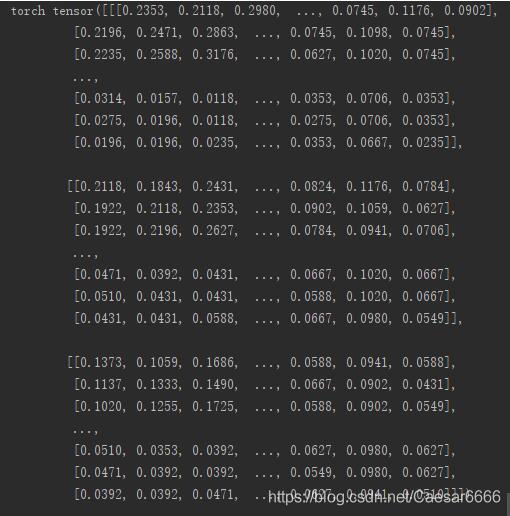
在使用 transforms.ToTensor() 进行图片数据转换过程中会对图像的像素值进行正则化,即一般读取的图片像素值都是8 bit 的二进制,那么它的十进制的范围为 [0, 255],而正则化会对每个像素值除以255,也就是把像素值正则化成 [0.0, 1.0]的范围。通过例子理解一下:
import torchvision.transforms as transforms
import cv2 as cv
img = cv.imread('image/000001.jpg')
transf = transforms.ToTensor()
img_tensor = transf(img)
print('opencv', img)
print('torch', img_tensor)
三、自行修改正则化的范围
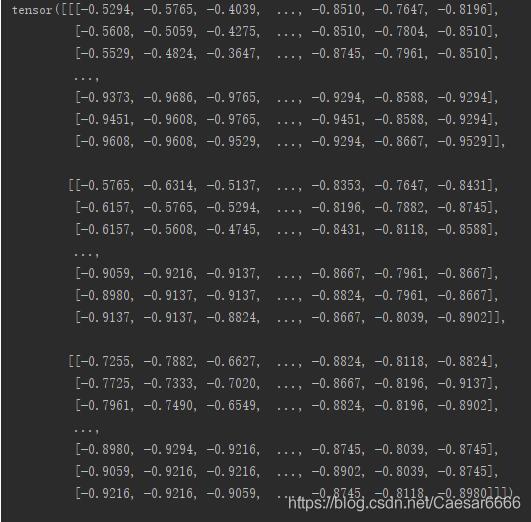
使用transforms.Compose函数可以自行修改正则化的范围,下面举个例子正则化成 [-1.0, 1.0]
transf2 = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
]
)
img_tensor2 = transf2(img)
print(img_tensor2)
计算方式就是:
C=(C-mean)/ std
C为每个通道的所有像素值,彩色图片为三通道图像(BGR),所以mean和std是三个数的数组。
使用transforms.ToTensor()时已经正则化成 [0,0, 0,1]了,那么(0.0 - 0.5)/0.5=-1.0,(1.0 - 0.5)/0.5=1.0,所以正则化成 [-1.0, 1.0]
补充:Python: 记录一个关于图片直接转化为pytorch.tensor和numpy.array的不同之处的问题
img = Image.open(img_path).convert("RGB")
img2 = torchvision.transforms.functional.to_tensor(img)
print(img2)
img1 = np.array(img)
print(img1)
输出是这样的:
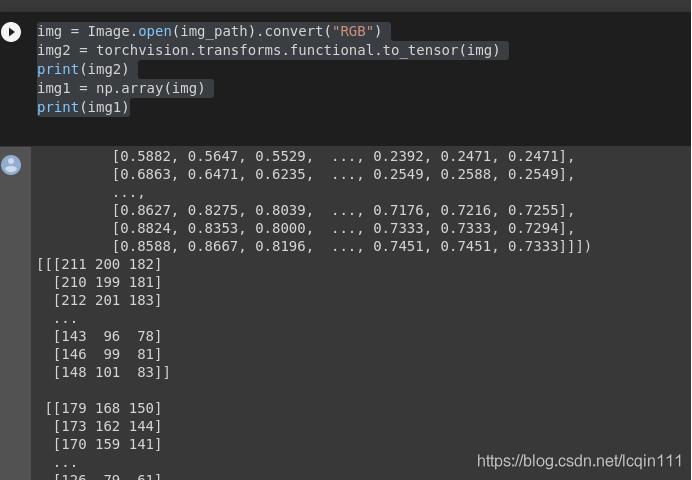
不仅shape不一样,而且值也是不一样的。
解释如下:
tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2, 0, 1).float() / 255 tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # 两种方法是一样的
PIL.Image.open()得到HWC格式,直接使用numpy 去转换得到(h,w,c)格式,而用to_tensor得到(c,h,w)格式且值已经除了255。
byte()相当于to(torch.uint8),tensor.numpy()是把tensor 转化为numpy.array格式。
在这里需要注意的是PIL和OPENCV的图像读取得到的格式都是HWC格式,一般模型训练使用的是CHW格式, H为Y轴是竖直方向,W为X轴水平方向。
且torchvision.transforms.functional.to_tensor()对所有输入都是有变换操作。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Pytorch 扩展Tensor维度、压缩Tensor维度的方法
1. 扩展Tensor维度 相信刚接触Pytorch的宝宝们,会遇到这样一个问题,输入的数据维度和实验需要维度不一致,输入的可能是2维数据或3维数据,实验需要用到3维或4维数据,那么我们需要扩展这个维度.其实特别简单,只要对数据加一个扩展维度方法就可以了. 1.1torch.unsqueeze(self: Tensor, dim: _int) torch.unsqueeze(self: Tensor, dim: _int) 参数说明:self:输入的tensor数据,dim:要对哪个维度扩展就输
-
详解pytorch tensor和ndarray转换相关总结
在使用pytorch的时候,经常会涉及到两种数据格式tensor和ndarray之间的转换,这里总结一下两种格式的转换: 1. tensor cpu 和tensor gpu之间的转化: tensor cpu 转为tensor gpu: tensor_gpu = tensor_cpu.cuda() >>> tensor_cpu = torch.ones((2,2)) tensor([[1., 1.], [1., 1.]]) >>> tensor_gpu = tensor_
-
Pytorch之Tensor和Numpy之间的转换的实现方法
为什么要相互转换: 1. 要对tensor进行操作,需要先启动一个Session,否则,我们无法对一个tensor比如一个tensor常量重新赋值或是做一些判断操作,所以如果将它转化为numpy数组就好处理了.下面一个小程序讲述了将tensor转化为numpy数组,以及又重新还原为tensor: 2. Torch的Tensor和numpy的array会共享他们的存储空间,修改一个会导致另外的一个也被修改. 学习链接:https://github.com/chenyuntc/pytorch-boo
-
Pytorch之扩充tensor的操作
我就废话不多说了,大家还是直接看代码吧~ b = torch.zeros((3, 2, 6, 6)) a = torch.zeros((3, 2, 1, 1)) a.expand_as(b).size() Out[32]: torch.Size([3, 2, 6, 6]) a = torch.zeros((3, 2, 2, 1)) a.expand_as(b).size() Traceback (most recent call last): File "/home/lart/.conda/en
-
PyTorch中Tensor的数据类型和运算的使用
在使用Tensor时,我们首先要掌握如何使用Tensor来定义不同数据类型的变量.Tensor时张量的英文,表示多维矩阵,和numpy对应,PyTorch中的Tensor可以和numpy的ndarray相互转换,唯一不同的是PyTorch可以在GPU上运行,而numpy的ndarray只能在cpu上运行. 常用的不同数据类型的Tensor,有32位的浮点型torch.FloatTensor, 64位浮点型 torch.DoubleTensor, 16位整形torch.ShortTenso
-
Pytorch生成随机数Tensor的方法汇总
在使用PyTorch做实验时经常会用到生成随机数Tensor的方法,比如: torch.rand() torch.randn() torch.normal() torch.linespace() 均匀分布 torch.rand(*sizes, out=None) → Tensor 返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数.张量的形状由参数sizes定义. 参数: sizes (int-) - 整数序列,定义了输出张量的形状 out (Tensor, optinal) -
-

pytorch 把图片数据转化成tensor的操作
摘要: 在图像识别当中,一般步骤是先读取图片,然后把图片数据转化成tensor格式,再输送到网络中去.本文将介绍如何把图片转换成tensor. 一.数据转换 把图片转成成torch的tensor数据,一般采用函数:torchvision.transforms.通过一个例子说明,先用opencv读取一张图片,然后在转换:注意一点是:opencv储存图片的格式和torch的储存方式不一样,opencv储存图片格式是(H,W,C),而torch储存的格式是(C,H,W). import torchvi
-
PyTorch读取Cifar数据集并显示图片的实例讲解
首先了解一下需要的几个类所在的package from torchvision import transforms, datasets as ds from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np #transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等. #DataLoader读入的数据类型是PIL.Image
-
PyTorch 使用torchvision进行图片数据增广
目录 使用torchvision来进行图片的数据增广 1. 读取图片 2. 图片增广 2.1 图片水平翻转 2.2 图片上下翻转 2.3 图片旋转 2.4 中心裁切 2.5 随机裁切 2.6 随机裁切并修改尺寸 2. 7 修改图片颜色 3. 训练数据集加载 使用torchvision来进行图片的数据增广 数据增强就是增强一个已有数据集,使得有更多的多样性.对于图片数据来说,就是改变图片的颜色和形状等等.比如常见的: 左右翻转,对于大多数数据集都可以使用:上下翻转:部分数据集不适合使用:图片切割:
-
pytorch cnn 识别手写的字实现自建图片数据
本文主要介绍了pytorch cnn 识别手写的字实现自建图片数据,分享给大家,具体如下: # library # standard library import os # third-party library import torch import torch.nn as nn from torch.autograd import Variable from torch.utils.data import Dataset, DataLoader import torchvision impo
-
pytorch 准备、训练和测试自己的图片数据的方法
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试.如果我们是自己的图片数据,又该怎么做呢? 一.我的数据 我在学习的时候,使用的是fashion-mnist.这个数据比较小,我的电脑没有GPU,还能吃得消.关于fashion-mnist数据,可以百度,也可以点此 了解一下,数据就像这个样子: 下载地址:https://github.com/zalandoresearch/fashion-mnist 但是下载下来是一种二进制文件,并不是图片,因此我先转换成了图
-
pytorch深度神经网络入门准备自己的图片数据
目录 正文 一.所有图片放在一个文件夹内 二.不同类别的图片放在不同的文件夹内 正文 图片数据一般有两种情况: 1.所有图片放在一个文件夹内,另外有一个txt文件显示标签. 2.不同类别的图片放在不同的文件夹内,文件夹就是图片的类别. 针对这两种不同的情况,数据集的准备也不相同,第一种情况可以自定义一个Dataset,第二种情况直接调用torchvision.datasets.ImageFolder来处理.下面分别进行说明: 一.所有图片放在一个文件夹内 这里以mnist数据集的10000个te
-
pytorch 数据集图片显示方法
图片显示 pytorch 载入的数据集是元组tuple 形式,里面包括了数据及标签(train_data,label),其中的train_data数据可以转换为torch.Tensor形式,方便后面计算使用. 同样给一些刚入门的同学在使用载入的数据显示图片的时候带来一些难以理解的地方,这里主要是将Tensor与numpy转换的过程,理解了这些就可以就行转换了 CIAFA10数据集 首先载入数据集,这里做了一些数据处理,包括图片尺寸.数据归一化等 import torch from torch.a
-
pytorch读取图像数据转成opencv格式实例
pytorch读取图像数据转成opencv格式方法:先转成numpy通用的格式,再将其转换成opencv格式. pytorch读取的数据使用loaddata这类函数实现.pytorch网络输入图像的格式为(C, H, W),就是(通道数,高,宽)而numpy中图像的格式为(H,W,C). 那就将其通道调换一下.用到函数transpose. 转换方法如下 例如A 的格式为(c,h,w) 那么经过 A = A.transpose(1,2,0) 后就变成了(h,w,c)了 然后用语句 B= cv2.c
-
pytorch sampler对数据进行采样的实现
PyTorch中还单独提供了一个sampler模块,用来对数据进行采样.常用的有随机采样器:RandomSampler,当dataloader的shuffle参数为True时,系统会自动调用这个采样器,实现打乱数据.默认的是采用SequentialSampler,它会按顺序一个一个进行采样.这里介绍另外一个很有用的采样方法: WeightedRandomSampler,它会根据每个样本的权重选取数据,在样本比例不均衡的问题中,可用它来进行重采样. 构建WeightedRandomSampler时
-
Pytorch 使用 nii数据做输入数据的操作
使用pix2pix-gan做医学图像合成的时候,如果把nii数据转成png格式会损失很多信息,以为png格式图像的灰度值有256阶,因此直接使用nii的医学图像做输入会更好一点. 但是Pythorch中的Dataloader是不能直接读取nii图像的,因此加一个CreateNiiDataset的类. 先来了解一下pytorch中读取数据的主要途径--Dataset类.在自己构建数据层时都要基于这个类,类似于C++中的虚基类. 自己构建的数据层包含三个部分 class Dataset(object