Python连接HDFS实现文件上传下载及Pandas转换文本文件到CSV操作
1. 目标
通过hadoop hive或spark等数据计算框架完成数据清洗后的数据在HDFS上
爬虫和机器学习在Python中容易实现
在Linux环境下编写Python没有pyCharm便利
需要建立Python与HDFS的读写通道
2. 实现
安装Python模块pyhdfs
版本:Python3.6, hadoop 2.9
读文件代码如下
from pyhdfs import HdfsClient
client=HdfsClient(hosts='ghym:50070')#hdfs地址
res=client.open('/sy.txt')#hdfs文件路径,根目录/
for r in res:
line=str(r,encoding='utf8')#open后是二进制,str()转换为字符串并转码
print(line)
写文件代码如下
from pyhdfs import HdfsClient
client=HdfsClient(hosts='ghym:50070',user_name='hadoop')#只有hadoop用户拥有写权限
str='hello world'
client.create('/py.txt',str)#创建新文件并写入字符串
上传本地文件到HDFS
from pyhdfs import HdfsClient
client = HdfsClient(hosts='ghym:50070', user_name='hadoop')
client.copy_from_local('d:/pydemo.txt', '/pydemo')#本地文件绝对路径,HDFS目录必须不存在
3. 读取文本文件写入csv
Python安装pandas模块
确认文本文件的分隔符
# pyhdfs读取文本文件,分隔符为逗号,
from pyhdfs import HdfsClient
client = HdfsClient(hosts='ghym:50070', user_name='hadoop')
inputfile=client.open('/int.txt')
# pandas调用读取方法read_table
import pandas as pd
df=pd.read_table(inputfile,encoding='gbk',sep=',')#参数为源文件,编码,分隔符
# 数据集to_csv方法转换为csv
df.to_csv('demo.csv',encoding='gbk',index=None)#参数为目标文件,编码,是否要索引
补充知识:记 读取hdfs 转 pandas 再经由pandas转为csv的一个坑
工作流程是这样的:
读取 hdfs 的 csv 文件,采用的是 hdfs 客户端提供的 read 方法,该方法返回一个生成器。
将读取到的数据按 逗号 处理,变为一个二维数组。
将二维数组传给 pandas,生成 df。
经若干处理后,将 df 转为 csv 文件并写入hdfs。
问题是这样的:
正常的数据:
ZERO,MEAN,STD,CV,INC,OPP,CS,IS_OUTNET
0,9.233,2.445,0.265,1.202,241,1,0
0,8.667,1.882,0.217,1.049,179,1,0
三行数据,正常走流程,没有任何问题。
异常数据:
ZERO,MEAN,STD,CV,INC,OPP,CS,IS_OUTNET,probability,prediction
0,9.233,2.445,0.265,1.202,241,1,0,'[0.9653901649086855,0.03460983509131456]',0.0
0,8.667,1.882,0.217,1.049,179,1,0,'[0.9653901649086855,0.03460983509131456]',0.0
在每一行中都会有一个数组类似的数据,有一对引号包起来,中间存在逗号,不可以拆分。
为此,我的做法如下:
匹配逗号是被成对引号包围的字符串。
将匹配到的字符串中的逗号替换为特定字符。
将替换后的新字符串替换回原字符串。
在将原字符串中的特定字符串替换为逗号。
本来这样做没有什么问题,但是在经由pandas转为csv的时候,发现原来带引号的字符串变为了前后各带三个引号。
源数据:
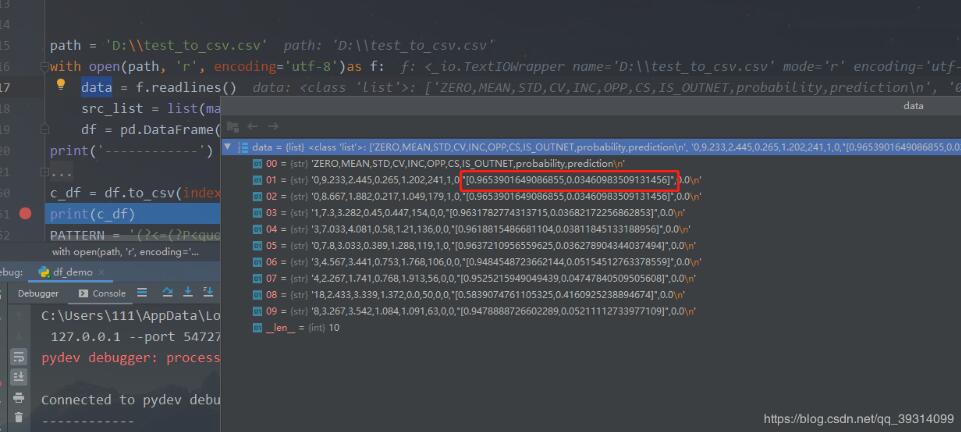
处理后的数据:

方法如下:
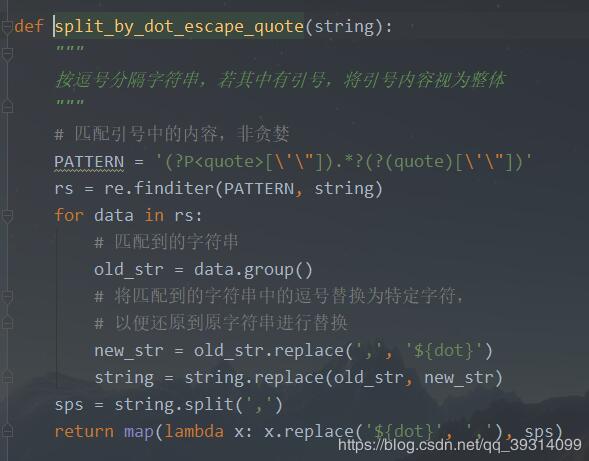
仔细研究对比了下数据,发现数据里的引号其实只是在纯文本文件中用来标识其为字符串,并不应该存在于实际数据中。
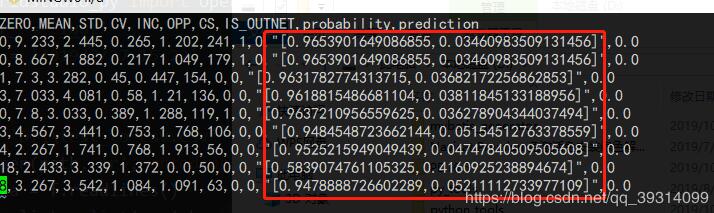
而我每次匹配后都是原封不动替换回去,譬如:
源数据:
"[0.9653901649086855,0.03460983509131456]"
匹配替换后:
"[0.9653901649086855${dot}0.03460983509131456]"
这样传给pandas,它就会认为这个数据是带引号的,在重新转为csv的时候,就会进行转义等操作,导致多出很多引号。
所以解决办法就是在替换之前,将匹配时遇到的引号也去掉:
PATTERN = '(?<=(?P<quote>[\'\"]))([^,]+,[^,]+)+?(?=(?P=quote))'
中间 ([^,]+,[^,]+)+? 要用+?,因为必须确定是有这样的组合才可以,并且非贪婪模式,故不可 ? 或者 *?
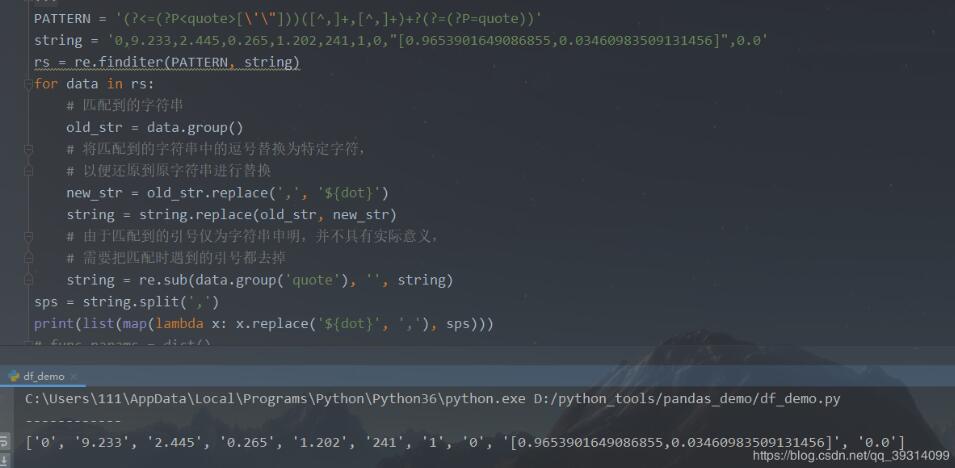
(ps:为了方便后面引用前面的匹配,我在环视匹配中创建了一个组)
再来个整体效果:

为了说明效果,引用pandas的自带读取csv方法:
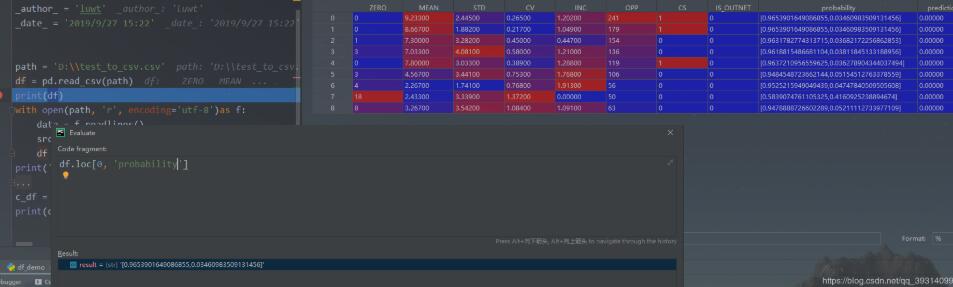
可以看到pandas读取出的该位置数据也是字符串,引号正是作为一个字符串声明而存在。
再次修改正则:
def split_by_dot_escape_quote(string):
"""
按逗号分隔字符串,若其中有引号,将引号内容视为整体
"""
# 匹配引号中的内容,非贪婪,采用正向肯定环视,
# 当左引号(无论单双引)被匹配到,放入组quote,
# 中间的内容任意,但是要用+?,非贪婪,且至少有一次匹配到字符,
# 若*?,则匹配0次也可,并不会匹配任意字符(环视只匹配位置不匹配字符),
# 由于在任意字符后面又限定了前面匹配到的quote,故只会匹配到",
# +?则会限定前面必有字符被匹配,故"",或引号中任意值都可匹配到
pattern = re.compile('(?=(?P<quote>[\'\"])).+?(?P=quote)')
rs = re.finditer(pattern, string)
for data in rs:
# 匹配到的字符串
old_str = data.group()
# 将匹配到的字符串中的逗号替换为特定字符,
# 以便还原到原字符串进行替换
new_str = old_str.replace(',', '${dot}')
# 由于匹配到的引号仅为字符串申明,并不具有实际意义,
# 需要把匹配时遇到的引号都去掉,只替换掉当前匹配组的引号
new_str = re.sub(data.group('quote'), '', new_str)
string = string.replace(old_str, new_str)
sps = string.split(',')
return map(lambda x: x.replace('${dot}', ','), sps)
s = '"2011,603","3510006998","F","5","5","0",""'
print(list(split_by_dot_escape_quote(s)))
运行结果如下:
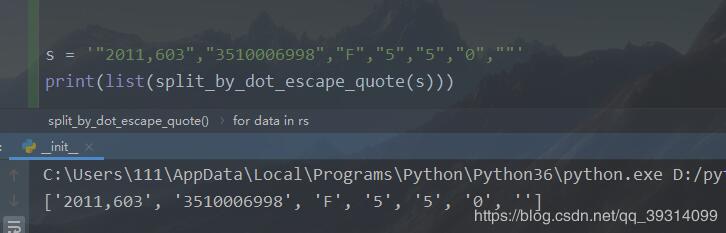
之前想的正则有些复杂,反而偏离了本意,还是对正则的认识不够深。
以上这篇Python连接HDFS实现文件上传下载及Pandas转换文本文件到CSV操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python将列表数据写入文件(txt, csv,excel)
写入txt文件 def text_save(filename, data):#filename为写入CSV文件的路径,data为要写入数据列表. file = open(filename,'a') for i in range(len(data)): s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,
-
python写入数据到csv或xlsx文件的3种方法
本文实例为大家分享了三种方式使用python写数据到csv或xlsx文件,供大家参考,具体内容如下 第一种:使用csv模块,写入到csv格式文件 # -*- coding: utf-8 -*- import csv with open("my.csv", "a", newline='') as f: writer = csv.writer(f) writer.writerow(["URL", "predict", "
-
python将pandas datarame保存为txt文件的实例
CSV means Comma Separated Values. It is plain text (ansi). The CSV ("Comma Separated Value") file format is often used to exchange data between disparate applications. The file format, as it is used in Microsoft Excel, has become a pseudo standa
-
Python连接HDFS实现文件上传下载及Pandas转换文本文件到CSV操作
1. 目标 通过hadoop hive或spark等数据计算框架完成数据清洗后的数据在HDFS上 爬虫和机器学习在Python中容易实现 在Linux环境下编写Python没有pyCharm便利 需要建立Python与HDFS的读写通道 2. 实现 安装Python模块pyhdfs 版本:Python3.6, hadoop 2.9 读文件代码如下 from pyhdfs import HdfsClient client=HdfsClient(hosts='ghym:50070')#hdfs地址
-

Python接口自动化之文件上传/下载接口详解
目录 〇.前言 一.文件上传接口 1. 接口文档 2. 代码实现 二.文件下载接口 1. 接口文档 2. 代码实现 总结 〇.前言 文件上传/下载接口与普通接口类似,但是有细微的区别. 如果需要发送文件到服务器,例如:上传文档.图片.视频等,就需要发送二进制数据,上传文件一般使用的都是 Content-Type: multipart/form-data 数据类型,可以发送文件,也可以发送相关的消息体数据. 反之,文件下载就是将二进制格式的响应内容存储到本地,并根据需要下载的文件的格式来写文件名,
-
Python Socketserver实现FTP文件上传下载代码实例
一.Socketserver实现FTP,文件上传.下载 目录结构 1.socketserver实现ftp文件上传下载,可以同时多用户登录.上传.下载 效果图: 二.上面只演示了下载,上传也是一样的,来不及演示了,上代码 1.客户端 import socket,hashlib,os,json,sys,time class Ftpclient(object): def __init__(self): self.client = socket.socket() def connect(self,ip,
-
python实现的简单FTP上传下载文件实例
本文实例讲述了python实现的简单FTP上传下载文件的方法.分享给大家供大家参考.具体如下: python本身自带一个FTP模块,可以实现上传下载的函数功能. #!/usr/bin/env python # -*- coding: utf-8 -*- from ftplib import FTP def ftp_up(filename = "20120904.rar"): ftp=FTP() ftp.set_debuglevel(2) #打开调试级别2,显示详细信息;0为关闭调试信息
-
python实现支持目录FTP上传下载文件的方法
本文实例讲述了python实现支持目录FTP上传下载文件的方法.分享给大家供大家参考.具体如下: 该程序支持ftp上传下载文件和目录.适用于windows和linux平台. #!/usr/bin/env python # -*- coding: utf-8 -*- import ftplib import os import sys class FTPSync(object): conn = ftplib.FTP() def __init__(self,host,port=21): self.c
-
Java实现HDFS文件上传下载
本文实例为大家分享了利用Java实现HDFS文件上传下载的具体代码,供大家参考,具体内容如下 1.pom.xml配置 <!--配置--> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <mav
-
详解ftp文件上传下载命令
介绍:从本地以用户wasqry登录的机器1*.1**.21.67上通过ftp远程登录到ftp服务器上,登录用户名是lte****,以下为使用该连接做的实验. 查看远程ftp服务器上用户lte****相应目录下的文件所使用的命令为:ls,登录到ftp后在ftp命令提示符下查看本地机器用户wasqry相应目录下文件的命令是:!ls.查询ftp命令可在提示符下输入:?,然后回车. 1.从远程ftp服务器下载文件的命令格式: get 远程ftp服务器上当前目录下要下载的文件名 [下载到本地机器上
-
FasfDFS整合Java实现文件上传下载功能实例详解
在上篇文章给大家介绍了FastDFS安装和配置整合Nginx-1.13.3的方法,大家可以点击查看下. 今天使用Java代码实现文件的上传和下载.对此作者提供了Java API支持,下载fastdfs-client-java将源码添加到项目中.或者在Maven项目pom.xml文件中添加依赖 <dependency> <groupId>org.csource</groupId> <artifactId>fastdfs-client-java</arti
-
利用ssh实现服务器文件上传下载
通过ssh实现服务器文件上传下载 写在前面的话 之前记录过一篇使用apache的FTP开源组件实现服务器文件上传下载的方法,但是后来发现在删除的时候会有些权限问题,导致无法删除服务器上的文件.虽然在Windows上使用FileZilla Server设置读写权限后没问题,但是在服务器端还是有些不好用. 因为自己需要实现资源管理功能,除了单文件的FastDFS存储之外,一些特定资源的存储还是打算暂时存放服务器上,项目组同事说后面不会专门在服务器上开FTP服务,于是改成了sftp方式进行操作. 这个
-
Java实现FTP批量大文件上传下载篇1
本文介绍了在Java中,如何使用Java现有的可用的库来编写FTP客户端代码,并开发成Applet控件,做成基于Web的批量.大文件的上传下载控件.文章在比较了一系列FTP客户库的基础上,就其中一个比较通用且功能较强的j-ftp类库,对一些比较常见的功能如进度条.断点续传.内外网的映射.在Applet中回调JavaScript函数等问题进行详细的阐述及代码实现,希望通过此文起到一个抛砖引玉的作用. 一.引子 笔者在实施一个项目过程中出现了一种基于Web的文件上传下载需求.在全省(或全国)各地的用