R语言给图形填充颜色的操作(polygon函数)
1. 使用polygon进行纯色填充
# polygon函数介绍
polygon(x, y = NULL, density = NULL, angle = 45,
border = NULL, col = NA, lty = par("lty"),
..., fillOddEven = FALSE)
其中density为填充的阴影线的密度,angle为阴影线的斜率(角度)。值得注意的是,当你需要纯色填充时,density和angle可以忽略不写。然后border为边框的颜色。同时border也可以是逻辑。即FALSE相当于NULL,TRUE相当于为前景色。
# Distance Between Brownian Motions 布朗运动之间的距离
n <- 100
xx <- c(0:n, n:0) #生成202个元素的向量,其中前面101与后面101数字对称
yy <- c(c(0, cumsum(stats::rnorm(n))), rev(c(0, cumsum(stats::rnorm(n)))))
plot (xx, yy, type = "n", xlab = "Time", ylab = "Distance")
polygon(xx, yy, col = "gray", border = "red")
title("布朗运动之间的距离")

如图 两个布朗运动间的距离用灰色填充
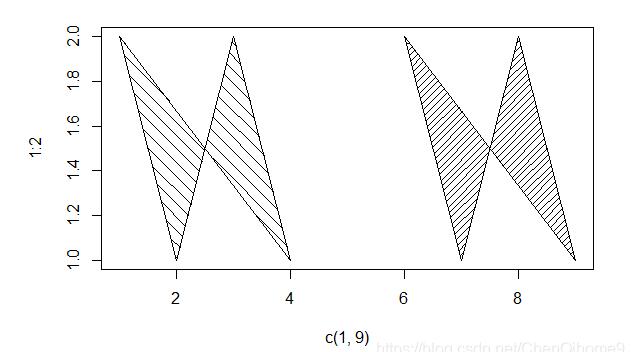
2. 使用polygon进行阴影线填充
# Line-shaded polygons 线阴影多边形
plot(c(1, 9), 1:2, type = "n")
polygon(1:9, c(2,1,2,1,NA,2,1,2,1),
density = c(10, 20), angle = c(-45, 45)) #density的值为两个,即不同的密度
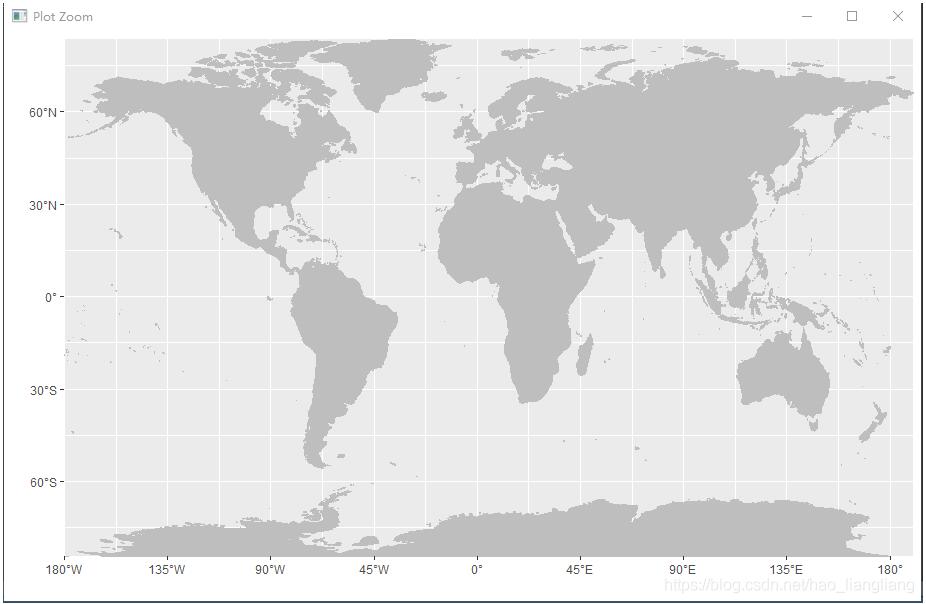
补充:R语言世界地图转为SpatialPolygons以及去除地图内国家边界
##加载包
library(maps) library(maptools) library(ggplot2) library(metR)
##提取地图并转换为Spatialpolygons
loc <- maps::map('world',interior = FALSE,
plot = FALSE, fill = TRUE,col = 'transparent')
ids <- sapply(strsplit(loc$names, ":"), function(x) x[1])
loc <- map2SpatialPolygons(map = loc, IDs = ids,proj4string = CRS('+proj=longlat +datum=WGS84 +no_defs'))
##去除内边界
worldmap1 <- unionSpatialPolygons(loc, IDs = rep(1,length(loc)))
##画图
worldmap2 <- fortify(worldmap1)
ggplot()+
scale_x_longitude(expand = c(0, 0), breaks = seq(-180, 180, 45))+
scale_y_latitude(expand = c(0, 0), breaks = seq(-90, 90, 30))+
geom_polygon(data = worldmap2,
mapping = aes(x = long, y = lat, group = group),
colour = 'gray', fill = 'gray', size = 0.5)
##结果图
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言 小数点位数的设置方式
经常用数据分析,有时不同的文件的小数位数不一样,但是我们可以让它们的位数保持一致的,下面的介绍就是设置小数位数. 使用options函数 > options(digits) 默认为7位 > a=0.234333323#9位> a[1] 0.2343333 下面开始设置下 > options(digits=3)> a=0.34434434#8位> a[1] 0.344 看最大的位数 > options(digits=27)Error in options(digit
-

R语言绘图样式设置操作(符号,线条,颜色,文本属性)
设置图像样式有两种方法,一种是全局修改,一种只针对一幅图片有效. 全局修改 a<-c(1:10) #全局修改 old_par<-par(no.readonly=TRUE) #记录默认样式到变量old_par中 par(lty=2,pch=17) #设置线型lty=2虚线,pch=17实心三角形,键值对的方式进行设置 #第一幅图,已经和默认样式不一样了 b<-rnorm(10) plot(a,b,type='b') #第二幅图,和第一幅图样式一样 b<-rnorm(10) plot(
-
R语言随机数生成的实现
1. 均匀分布 函数: runif(n, min=0, max=1),n 表示生成的随机数数量,min 表示均匀分布的下限,max 表示均匀分布的上限,若省略参min.max,则默认生成[0,1]上的均匀分布随机数. > q = runif(5,-1,1) > q [1] 0.73539909 0.72895000 -0.04357151 0.81696252 0.50210058 2. 正太分布 函数:rnorm(n, mean=0, sd=1),其中,n 表示生成的随机数数量,mean是正
-
R语言导入CSV数据的简单方法
第一.查看读取路径:getwd() ``` getwd() #获取文件存储位置 [1] "E:/R/meta-rbook-examples" #文件位置,如果是自己想要的存储位置可以直接将文件放到这里,如果不是更改路径. `` 第二.修改路径: setwd("E:/R")#设置新的路径`,将文件放入该文件夹中 第三.读取CSV文件: data1<-read.csv("dataset01.csv",as.is = TRUE)#读取文件名为:d
-
R语言删除/添加数据框中的某一行/列
假如数据是这样的,这是有一个数据框 > A <- data.frame(姓名 = c("张三", "李四", "王五"), 体重 = c(50, 70, 80), 视力 = c(5.0, 4.8, 5.2)) > A 姓名 体重 视力 1 张三 50 5.0 2 李四 70 4.8 3 王五 80 5.2 删除第一行"张三"的信息 > A <- A[-1,] > A 姓名 体重 视力 2 李
-
聊聊R语言中Legend 函数的参数用法
如下所示: legend(x, y = NULL, legend, fill = NULL, col = par("col"), border = "black", lty, lwd, pch, angle = 45, density = NULL, bty = "o", bg = par("bg"), box.lwd = par("lwd"), box.lty = par("lty")
-
R语言给图形填充颜色的操作(polygon函数)
1. 使用polygon进行纯色填充 # polygon函数介绍 polygon(x, y = NULL, density = NULL, angle = 45, border = NULL, col = NA, lty = par("lty"), ..., fillOddEven = FALSE) 其中density为填充的阴影线的密度,angle为阴影线的斜率(角度).值得注意的是,当你需要纯色填充时,density和angle可以忽略不写.然后border为边框的颜色.同时bor
-
R语言ggplot2设置图例(legend)的操作大全
目录 基本箱线图(带有图例) 移除图例 修改图例的内容 颠倒图例的顺序 隐藏图例标题 修改图例中的标签 修改data.frame的factor 修改标题和标签的显示 修改图例的框架 设置图例的位置 隐藏斜线 总结 本文在 http://www.cookbook-r.com/Graphs/Scatterplots_(ggplot2)/ 的基础上加入了自己的理解 图例用来解释图中的各种含义,比如颜色,形状,大小等等, 在ggplot2中aes中的参数(x, y 除外)基本都会生成图例来解释图形, 比
-
R语言数据的输入和输出操作
数据的载入 R本身已经提供了超过50个数据集,而在众多功能包中,默认的数据集被存放在datasets程序包中,通过函数data()k可以查看系统提供所有的数据包,同时可以通过函数library()加载程序包中的数据. 矩阵型数据最常用的读取方式是read.table()具体的调用格式是() read.table(file, header = FALSE, sep = "", quote = "\"'",dec = ".", numera
-
R语言-计算频数和频率的操作
首先,筛选出需要的列: data <- data2[,which(colnames(data2) %in% c("产品分类", "期数", "逾期月数"))] 产品分类 期数 逾期月数 委托贷款 24 1 委托贷款 36 1 担保贷款 24 2 委托贷款 24 2 信用贷款 36 4 担保贷款 24 3 信用贷款 24 1 委托贷款 36 3 担保贷款 24 2 现在希望得到每种产品种类在不同期数时 逾期月数的占比,使用table函数: #
-
R语言开发之输出折线图的操作
线形图是通过在多个点之间绘制线段来连接一系列点所形成的图形,这些点按其坐标(通常是x坐标)的值排序,并且它通常用于识别数据趋势. 在R中的通过使用plot()函数来创建线形图,语法如下: plot(v,type,col,xlab,ylab) 参数描述如下: v - 是包含数值的向量. type - 取值"p"表示仅绘制点,"l"表示仅绘制线条,"o"表示仅绘制点和线. xlab - 是x轴的标签. ylab - 是y轴的标签. main - 是图
-
R语言ggplot2x轴顺序设置自定义颜色的操作
先声明一下所用的数据集 第一个图如下 这个图主要在于x轴的顺序设置上,如果按不做任何处理的话>3那个就会在2之前,解决方法是b[,1]<-factor(b[,1],levels=c('2','3',">3")),这句代码可以重新设置因子的级别 完整代码如下: a[,1]<-factor(a[,1],levels=c('2','3',">3")) ggplot(a,aes(x=a[,1],y=a[,2]))+geom_bar(stat=&
-
R ggplot2 修改默认颜色的操作
我们都知道ggplot2包是R的神器,很多生物学文章都选择用这个包来画图.用ggplot2就像玩俄罗斯方块一样,一层一层地往上叠加元素,这使得它用起来很方便. 个人觉得它默认的配色系统很不错,但看到颜色后却不知道这种颜色叫啥,今天就来介绍一下,如果你有1~6个元素,ggplot2给的配色分别是啥. 1个元素: 2个元素(颜色分配顺序为先从左到右,后从上到下): 3个元素: 4个元素: 5个元素: 6个元素: 多余6个元素大家可以用下面的代码去实现 运行的代码为: library(scales)
-
R语言实现随机森林的方法示例
目录 随机森林算法介绍 算法介绍: 决策树生长步骤: 投票过程: 基本思想: 随机森林的优点: 缺点 R语言实现 随机森林模型搭建 1:randomForest()函数用于构建随机森林模型 2:importance()函数用于计算模型变量的重要性 3:MDSplot()函数用于实现随机森林的可视化 4:rfImpute()函数可为存在缺失值的数据集进行插补(随机森林法),得到最优的样本拟合值 5:treesize()函数用于计算随机森林中每棵树的节点个数 随机森林算法介绍 算法介绍: 简单的说,
-
R语言-如何将循环所得的矩阵组成一个矩阵
在矩阵合并中,常见的方法有cbind()和rbind() 其中,前者为按列合并,后者为按行合并. 但是这两个函数有个缺点,就是不能应用到循环之中.例如: A<-matrix(1:12,nrow = 4,byrow = T) B<-matrix(1:8,nrow = 4,byrow = T) C<-cbind(A,B) 得到的矩阵C为[按列合并两者行数必须相同]: 但是如果将这个方法应用在循环中,就无法取得预期效果: A<-matrix(1:12,nrow = 4,byrow = T
-
R语言实现导出矩阵
程序实在是调不出来了,我决定破釜沉舟,直接把所有表格都打印出来,看看数据到底哪儿有问题. 然后就开始了闹心的矩阵导出... 首先,百度了一下,数据导出的代码为: write.table (x, file ="", sep ="", row.names =TRUE, col.names =TRUE, quote =TRUE) 其中: x:需要导出的数据 file:导出的文件路径 sep:分隔符,默认为空格(" "),也就是以空格为分割列 row.n