数据结构与算法之并查集(不相交集合)
认识并查集
对于并查集(不相交集合),很多人会感到很陌生,没听过或者不是特别了解。实际上并查集是一种挺高效的数据结构。实现简单,只是所有元素统一遵从一个规律所以让办事情的效率高效起来。
对于定意义,百科上这么定义的:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
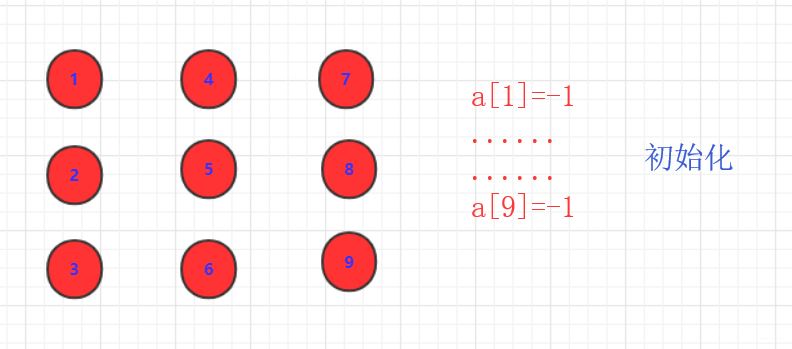
并查集解析基本思想初始化,一个森林每个都为独立。通常用数组表示,每个值初始为-1。各自为根
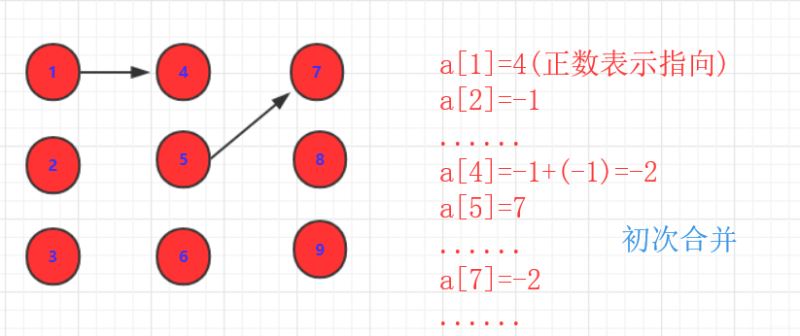
join
(a,b) 操作。a,b两个集合合并。注意这里的a,并不是a,b合并,而是a,b的集合合并。这就派生了一些情况:a,b如果是独立的(没有和其他合并),那么直接a指向b(或者b指向a),即data[a]=b;同时为了表示这个集合有多少个,原本-1的b再次-1.即data[b]=-2.表示以b为父亲的节点有|-2|个。
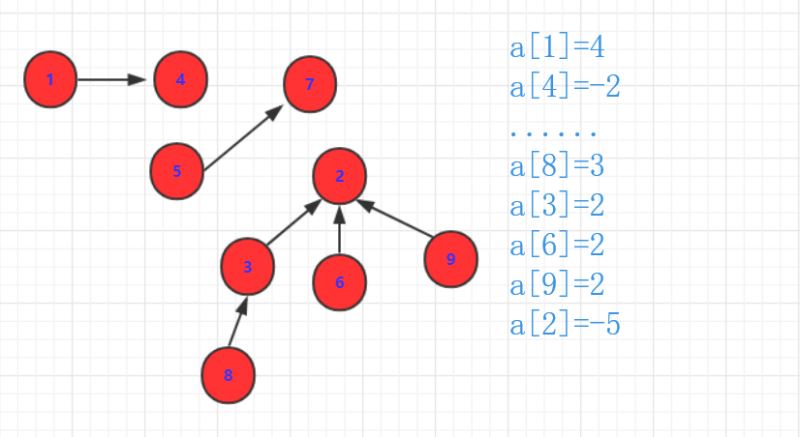 a,b
a,b
如果有集合(可能有父亲,可能自己是根),那么我们当然不能直接操作a,b(因为a,b可能已经指向别人了.)那么我们只能操作a,b的祖先。因为a,b的祖先是没有指向的(即数据为负值表示大小)。那么他们首先一个负值要加到另外一个上面去。另外这个数值要变成指向的那个表示联系。
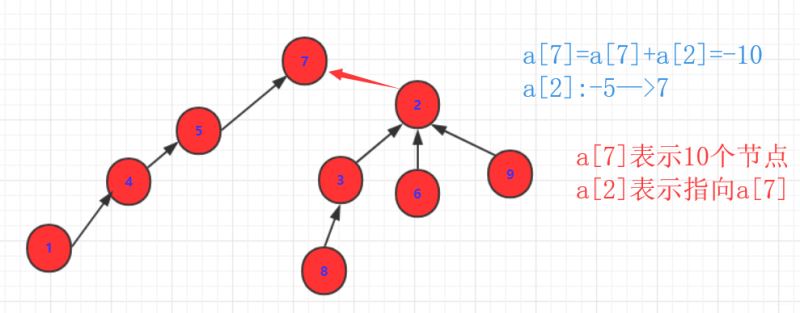
对于上述你可能会有疑问:
如何查看a,b是否在一个集合?查看是否在一个集合,只需要查看节点根祖先的结果是否相同即可。因为只有根的数值是负的,而其他都是正数表示指向的元素。所以只需要一直寻找直到不为正数进行比较即可!a,b合并,究竟是a的祖先合并在b的祖先上,还是b的祖先合并在a上?这里会遇到两种情况,这个选择也是非常重要的。你要弄明白一点:树的高度+1的化那么整个元素查询的效率都会降低!
所以我们通常是:小数指向大树(或者低树指向高树),这个使得查询效率能够增加!
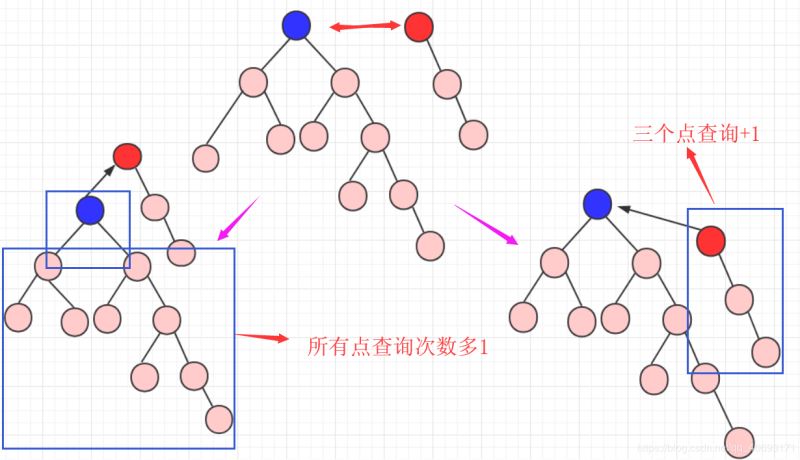
当然,在高度和数量的选择上,还需要你自己选择和考虑。
其他路径压缩?
每次查询,自下向上。当我们调用递归的时候,可以顺便压缩路径,因为我们查找一个元素其实只需要直到它的祖先,所以当他距离祖先近那么下次查询就很快。并且压缩路径的代价并不大!
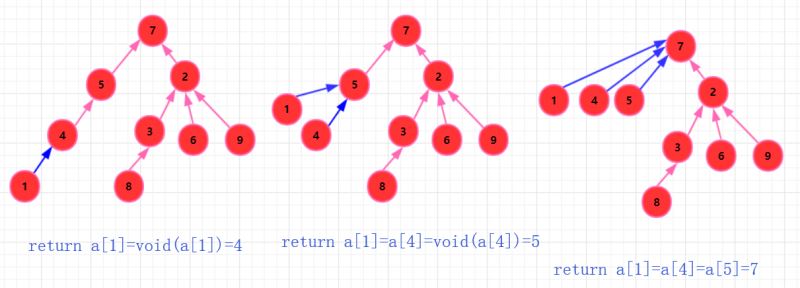
代码实现
并查集实现起来较为简单,直接贴代码!
package 并查集不想交集合;
import java.util.Scanner;
public class DisjointSet {
static int tree[]=new int[100000];//假设有500个值
public DisjointSet() {set(this.tree);}
public DisjointSet(int tree[])
{
this.tree=tree;
set(this.tree);
}
public void set(int a[])//初始化所有都是-1 有两个好处,这样他们指向-1说明是自己,第二,-1代表当前森林有-(-1)个
{
int l=a.length;
for(int i=0;i<l;i++)
{
a[i]=-1;
}
}
public int search(int a)//返回头节点的数值
{
if(tree[a]>0)//说明是子节点
{
return tree[a]=search(tree[a]);//路径压缩
}
else
return a;
}
public int value(int a)//返回a所在树的大小(个数)
{
if(tree[a]>0)
{
return value(tree[a]);
}
else
return -tree[a];
}
public void union(int a,int b)//表示 a,b所在的树合并
{
int a1=search(a);//a根
int b1=search(b);//b根
if(a1==b1) {System.out.println(a+"和"+b+"已经在一棵树上");}
else {
if(tree[a1]<tree[b1])//这个是负数,为了简单减少计算,不在调用value函数
{
tree[a1]+=tree[b1];//个数相加 注意是负数相加
tree[b1]=a1; //b树成为a的子树,直接指向a;
}
else
{
tree[b1]+=tree[a1];//个数相加 注意是负数相加
tree[a1]=b1; //b树成为a的子树,直接指向a;
}
}
}
public static void main(String[] args)
{
DisjointSet d=new DisjointSet();
d.union(1,2);
d.union(3,4);
d.union(5,6);
d.union(1,6);
d.union(22,24);
d.union(3,26);
d.union(36,24);
System.out.println(d.search(6)); //头
System.out.println(d.value(6)); //大小
System.out.println(d.search(22)); //头
System.out.println(d.value(22)); //大小
}
}
package 并查集不想交集合;import java.util.Scanner;public class DisjointSet {static int tree[]=new int[100000];//假设有500个值public DisjointSet() {set(this.tree);}public DisjointSet(int tree[]) {this.tree=tree;set(this.tree);}public void set(int a[])//初始化所有都是-1 有两个好处,这样他们指向-1说明是自己,第二,-1代表当前森林有-(-1)个{int l=a.length;for(int i=0;i<l;i++){a[i]=-1;}}public int search(int a)//返回头节点的数值{if(tree[a]>0)//说明是子节点{return tree[a]=search(tree[a]);//路径压缩}elsereturn a;}public int value(int a)//返回a所在树的大小(个数){if(tree[a]>0){return value(tree[a]);}elsereturn -tree[a];}public void union(int a,int b)//表示 a,b所在的树合并{int a1=search(a);//a根int b1=search(b);//b根if(a1==b1) {System.out.println(a+"和"+b+"已经在一棵树上");}else {if(tree[a1]<tree[b1])//这个是负数,为了简单减少计算,不在调用value函数{tree[a1]+=tree[b1];//个数相加 注意是负数相加tree[b1]=a1; //b树成为a的子树,直接指向a;}else{tree[b1]+=tree[a1];//个数相加 注意是负数相加tree[a1]=b1; //b树成为a的子树,直接指向a;}}}public static void main(String[] args){DisjointSet d=new DisjointSet();d.union(1,2);d.union(3,4);d.union(5,6);d.union(1,6);d.union(22,24);d.union(3,26);d.union(36,24);System.out.println(d.search(6));//头System.out.println(d.value(6)); //大小System.out.println(d.search(22));//头System.out.println(d.value(22)); //大小}}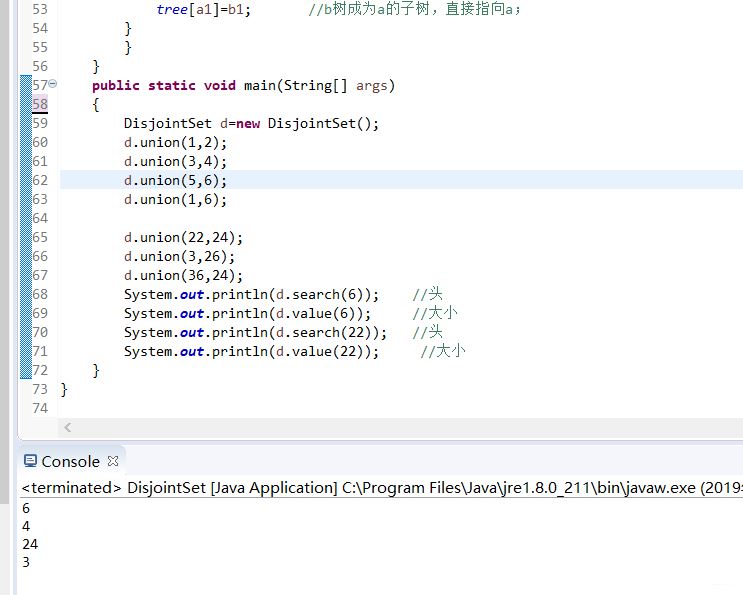
结语并查集属于简单但是很高效率的数据结构。在集合中经常会遇到。如果不采用并查集而传统暴力效率太低,而不被采纳。另外,并查集还广泛用于迷宫游戏中,下面有机会可以介绍用并查集实现一个走迷宫小游戏。
总结
以上所述是小编给大家介绍的数据结构与算法之并查集(不相交集合),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python数据结构与算法(几种排序)小结
Python数据结构与算法(几种排序) 数据结构与算法(Python) 冒泡排序 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 冒泡排序算法的运作如下: 比较相邻的元素.如果第一个比第二个大(升序),就交换他们两个. 对每一对相邻元素作同样的工作,从
-
JavaScript数据结构与算法之集合(Set)
集合(Set) 说起集合,就想起刚进高中时,数学第一课讲的就是集合.因此在学习集合这种数据结构时,倍感亲切. 集合的基本性质有一条: 集合中元素是不重复的.因为这种性质,所以我们选用了对象来作为集合的容器,而非数组. 虽然数组也能做到所有不重复,但终究过于繁琐,不如集合. 集合的操作 集合的基本操作有交集.并集.差集等.这儿我们介绍JavaScipt集合中交集.并集.差集的实现. JavaScipt中集合的实现 首先,创建一个构造函数. /** * 集合的构造函数 */ function Set
-
PHP常用算法和数据结构示例(必看篇)
实例如下: </pre><pre name="code" class="php"><?php /** * Created by PhpStorm. * User: qishou * Date: 15-8-2 * Time: 上午9:12 */ header("content-type:text/html;charset=utf-8"); $arr = array(3,5,8,4,9,6,1,7,2); echo im
-

C#常用数据结构和算法总结
1.数据 数据(Data)是外部世界信息的载体, 是能够被计算机识别,加工,存储的.在现实生活中也就是我们的产品原材料. 计算机中的数据包括数值数据,图片,影音资料等. 2. 数据元素和数据项 数据元素(Data Element)是数据的基本单位,在计算机处理的过程中通常是作为一个整体来作为处理的. 数据项(Data Item):一个数据元素通常由一个或多个数据项组成. 比如数据库表:(Student),它有Id,Name,Sex,Age,Address等字段,而这张表又有多行数据.我们通常将这
-
数据结构与算法之并查集(不相交集合)
认识并查集 对于并查集(不相交集合),很多人会感到很陌生,没听过或者不是特别了解.实际上并查集是一种挺高效的数据结构.实现简单,只是所有元素统一遵从一个规律所以让办事情的效率高效起来. 对于定意义,百科上这么定义的: 并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受:即使在
-
C++高级数据结构之并查集
目录 1.动态连通性 2.union-find算法API 3.quick-find算法 4.quick-union算法 5.加权quick-union算法 6.使用路径压缩的加权quick-union算法 7.算法比较 前言: 高级数据结构(Ⅰ)并查集(union-find) 动态连通性 union-find算法API quick-find算法 quick-union算法 加权quick-union算法 使用路径压缩的加权quick-union算法 算法比较 并查集 > 左神版 高级数据结构(Ⅰ
-
详解Java实现数据结构之并查集
一.什么是并查集 对于一种数据结构,肯定是有自己的应用场景和特性,那么并查集是处理什么问题的呢? 并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题,常常在使用中以森林来表示.在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受:即使在空
-
java并查集算法带你领略热血江湖
目录 一.什么是并查集 二.深入理解并查集 三.实现并查集 四.真题训练 五.路径压缩优化 六.总结 你好,我是小黄,一名独角兽企业的Java开发工程师. 校招收获数十个offer,年薪均20W~40W. 感谢茫茫人海中我们能够相遇, 俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习, 希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想. 一.什么是并查集 并查集被很多OIer认为是最简洁而优雅的数据结构之一,主要用于处理一些不相交集合的合并问题,并支持两种操作: 合并
-
Java数据结构之并查集的实现
目录 代码解析 代码应用 实际应用 并查集就是将原本不在一个集合里面的内容合并到一个集合中. 在实际的场景中用处不多. 除了出现在你需要同时去几个集合里面查询,避免出现查询很多次,从而放在一起查询的情况. 下面简单实现一个例子,我们来举例说明一下什么是并查集,以及究竟并查集解决了什么问题. 代码解析 package com.chaojilaji.book.andcheck; public class AndCheckSet { public static Integer getFather(in
-
java 数据结构并查集详解
目录 一.概述 二.实现 2.1 Quick Find实现 2.2 Quick Union实现 三.优化 3.1基于size的优化 3.2基于rank优化 3.2.1路径压缩(Path Compression ) 3.2.2路径分裂(Path Spliting) 3.2.3路径减半(Path Halving) 一.概述 并查集:一种树型数据结构,用于解决一些不相交集合的合并及查询问题.例如:有n个村庄,查询2个村庄之间是否有连接的路,连接2个村庄 两大核心: 查找 (Find) : 查找元素所在
-
C#并查集(union-find)算法详解
目录 算法的主题思想: 1. 动态连通性 2. 定义问题 3. quick-find算法实现 算法分析 4. quick-union算法实现 森林表示 算法分析 5.加权 quick-union 算法实现 算法分析 6.最优算法 - 路径压缩 算法的主题思想: 1.优秀的算法因为能够解决实际问题而变得更为重要: 2.高效算法的代码也可以很简单: 3.理解某个实现的性能特点是一个挑战: 4.在解决同一个问题的多种算法之间进行选择时,科学方法是一种重要的工具: 5.迭代式改进能够让算法的效率越来越高
-
C++并查集亲戚(Relations)算法实例
本文实例讲述了C++并查集亲戚(Relations)算法.分享给大家供大家参考.具体分析如下: 题目: 亲戚(Relations) 或许你并不知道,你的某个朋友是你的亲戚.他可能是你的曾祖父的外公的女婿的外甥的表姐的孙子.如果能得到完整的家谱,判断两个人是否亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代,使得家谱十分庞大,那么检验亲戚关系实非人力所能及.在这种情况下,最好的帮手就是计算机. 为了将问题简化,你将得到一些亲戚关系的信息,如同Marry和Tom是亲戚,Tom和B en是
-
c语言数据结构之并查集 总结
并查集(Union-Find Set): 一种用于管理分组的数据结构.它具备两个操作:(1)查询元素a和元素b是否为同一组 (2) 将元素a和b合并为同一组. 注意:并查集不能将在同一组的元素拆分为两组. 并查集的实现: 用树来实现. 使用树形结构来表示以后,每一组都对应一棵树,然而我们就可以将这个问题转化为树的问题了,我们看两个元素是否为一组我们只要看这两个元素的根是否一致.显然,使用树形结构将问题简单化了.合并时是我们只需要将一组的根与另一组的根相连即可. 并查集的核心在于,一棵树的所有节点
-
C++并查集算法简单详解
目录 1.并查集的初始化 2.并查集的查找操作 3.并查集的合并操作 4.为什么要路径压缩? 5.实现路径压缩 总结 1.并查集的初始化 并查集是用一个数组实现的.首先先定义一个数组: int father[N]; father[i]表示元素i的父亲结点. 接下来进行初始化.一开始,每个元素都分别是独立的一个集合,父亲结点就是它自己,所以初始化时将所有father[i]等于i: for(int i = 1; i <= N; i++){ father[i] = i; } 这样,就将father数组