Python计算不规则图形面积算法实现解析
这篇文章主要介绍了Python计算不规则图形面积算法实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
介绍:大三上做一个医学影像识别的项目,医生在原图上用红笔标记病灶点,通过记录红色的坐标位置可以得到病灶点的外接矩形,但是后续会涉及到红圈内的面积在外接矩形下的占比问题,有些外接矩形内有多个红色标记,在使用网上的opencv的fillPoly填充效果非常不理想,还有类似python计算任意多边形方法也不理想的情况下,自己探索出的一种效果还不错的计算多圈及不规则图形的面积的算法。
能较为准确的计算出不规则图形的面积
正文:算法的思想很简单,遍历图片每一列,通过色差判断是否遇到标记圈,将坐标全部记录,对每一列的坐标都进行最小行和最大行记录,确定每一列的最小和最大的坐标,然后上色(类似opencv的fillPoly的实现,但是细节有些区别),只是这样效果并不好,将图片旋转90度,再做一边,将两个图片的结果放在一起做与操作,得到结果就能很好的处理多圈的标记问题和多算面积的问题(比如上面的08-LM),

算法实现
全程只用pillow库
首先先用屏幕拾色器获取目标颜色的rgb值,我这种情况下就是(237,28,36),前期截取外接矩形也是要这一步的,颜色也一致
def pixel_wanted(pix): return pix==(237,28, 36)
每一列都设定翻转位初始为False,如果上一个像素点不是目标色,当前是目标色则开始记录,一旦不是目标色,停止检测
top_Pixel都设定为黑色(0,0,0)因为有图片最上方就是目标色,导致判定出问题,直接让最上面的像素初始化是黑色
coordinate_List记录了所有符合的点坐标
coordinate_List = []
top_Pixel = (0,0,0)
for x in range(im.size[0]):
flag = False #初始化每一列翻转位为False
for y in range(im.size[1]):
current_pixel = im.getpixel((x,y))
last_pixel = im.getpixel((x,y-1)) if y>0 else top_Pixel
#翻转判定
if pixel_wanted(current_pixel) and \
not pixel_wanted(last_pixel):
flag = True
if flag and not pixel_wanted(current_pixel):
flag = False
if(flag):
coordinate_List.append((x,y))
coordinate_List中的点如下图

然后就是将上面获得coordinate列表进行处理
将coordinate列表中每一列的最小坐标和最大坐标进行记录
因为每一列记录的数量并不确定(应该可以在上一步改进一下),所以需要遍历多次
首先找到第一个列出现的坐标,将它的行信息记录(行信息最小确定),
然后遍历出全部的同列的坐标,比较行坐标,如果大的就将最大的代替(行信息最大确定),用一个新的列表记录数据
coordinate_Min_Max_List = []
#找最小最大
for i in range(im.size[0]):
min=-1
max=-1
for coordinate in coordinate_List:
if coordinate[0] == i:
min = coordinate[1]
max = coordinate[1]
break
for coordinate in coordinate_List:
if coordinate[0] == i:
if coordinate[1]>max:
max = coordinate[1]
coordinate_Min_Max_List.append(min)
coordinate_Min_Max_List.append(max)
其中要将min和max都初始化为一个坐标不存在的值比如-1,为了在下一步多圈且有空隙情况下,不会出现残影现象,如下图
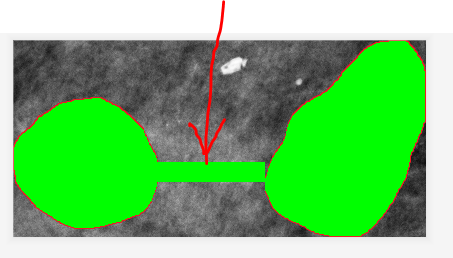

上一步的最后得到一个列表,第n列的最小行和最大行分别是第2n和2n+1元素,结果中的-1,为了让下一步不会画进去

然后就是绘制图片了,每一列将列表中对应的最小行到最大行涂满
#上色
for x in range(im.size[0]):
for y in range(im.size[1]):
min = coordinate_Min_Max_List[x*2]
max = coordinate_Min_Max_List[x*2+1]
if min<y<max:
im.putpixel((x,y),(0,255,0))
else:
#可以把非红圈的上掩膜遮住
pass
至此,就是类似opencv的算法实现,虽然还差翻转做与操作,但是已经比opencv生成的效果好,写成函数后续调用,
然后就是简单的翻转90度,再调用一次这个函数再做一遍
def Cal_S(im):
im_0 = im.rotate(0)
im_90 = im.rotate(90, expand=True)
im_0 = fillPoly(im_0)
im_90 = fillPoly(im_90)
im_90 = im_90.rotate(-90, expand=True)
i=0
for x in range(im.size[0]):
for y in range(im.size[1]):
if(im_0.getpixel((x,y))==(0,255,0) and
im_90.getpixel((x,y))==(0,255,0)):
im.putpixel((x,y),(0,255,0))
i+=1
return i/(im.size[0]*im.size[1])
做两遍的效果图


可以看到效果非常不错,但是依旧有个别图像有问题,比如十字分布的,
但现在的话误差已经降低非常多了,这些极其个别的十字现象可以手动把原图切割一下,或者干脆不处理了

所有代码,画出绿图片为了方便直观的查看,函数中可以把图片顺便保存一下,总体看一下效果
from PIL import Image
def pixel_wanted(pix):
return pix==(237,28, 36)
def fillPoly(im):
coordinate_List = []
top_Pixel = (0,0,0)
for x in range(im.size[0]):
flag = False #初始化每一列翻转位为False
for y in range(im.size[1]):
current_pixel = im.getpixel((x,y))
last_pixel = im.getpixel((x,y-1)) if y>0 else top_Pixel
#翻转判定
if pixel_wanted(current_pixel) and \
not pixel_wanted(last_pixel):
flag = True
if flag and not pixel_wanted(current_pixel):
flag = False
if(flag):
coordinate_List.append((x,y))
coordinate_Min_Max_List = []
#找最小最大
for i in range(im.size[0]):
min=-1
max=-1
for coordinate in coordinate_List:
if coordinate[0] == i:
min = coordinate[1]
max = coordinate[1]
break
for coordinate in coordinate_List:
if coordinate[0] == i:
if coordinate[1]>max:
max = coordinate[1]
coordinate_Min_Max_List.append(min)
coordinate_Min_Max_List.append(max)
#上色
for x in range(im.size[0]):
for y in range(im.size[1]):
min = coordinate_Min_Max_List[x*2]
max = coordinate_Min_Max_List[x*2+1]
if min<y<max:
im.putpixel((x,y),(0,255,0))
else:
#可以把非红圈的上掩膜遮住
pass
return im
def Cal_S(im):
im_0 = im.rotate(0)
im_90 = im.rotate(90, expand=True)
im_0 = fillPoly(im_0)
im_90 = fillPoly(im_90)
im_90 = im_90.rotate(-90, expand=True)
i=0
for x in range(im.size[0]):
for y in range(im.size[1]):
if(im_0.getpixel((x,y))==(0,255,0) and
im_90.getpixel((x,y))==(0,255,0)):
im.putpixel((x,y),(0,255,0))
i+=1
return i/(im.size[0]*im.size[1])
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python计算圆周长、面积、球体体积并画出圆
输入半径,计算圆的周长.面积.球体体积,并画出这个圆.拖动条.输入框和图像控件的数据保持一致! Fedora下测试通过 复制代码 代码如下: #https://github.com/RobberPhex/GTK-Example-CalcAreafrom gi.repository import Gtk, Gdk, GdkPixbuffrom PIL import Image, ImageDrawfrom io import BytesIOfrom math import pi class Mod
-
Python3计算三角形的面积代码
关于Python语言,众说纷纭,但无外乎两种,强大,垃圾.大多数人还是对Python持肯定意见,认为它很强大.前些天和两个的大学同学聊天,一个是在做手机测试,一个是给银行系统做维护一类的工作,都在北京.都在一边工作一边学习,其中一个学的就是Python.我也不能落后啊,走上了Python的不归路.我个人觉得对广大编程爱好者来说,尤其是在校大学生,大家可以有时间学习一门语言,对以后是很有帮助的. 以下实例为通过用户输入三角形三边长度,并计算三角形的面积: # -*- coding: UTF-8 -
-
Python计算两个矩形重合面积代码实例
这篇文章主要介绍了Python 实现两个矩形重合面积代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 计算两个矩形的重合面积 import math x1, y1, x2, y2 = input().split(" ") x1, y1, x2, y2=int(x1), int(y1), int(x2), int(y2) # print(x1, y1, x2, y2) x1,x2 = min(x1,x2),max(x1,
-
利用Python求阴影部分的面积实例代码
一.前言说明 今天看到微信群里一道六年级数学题,如下图,求阴影部分面积 看起来似乎并不是很难,可是博主添加各种辅助线,写各种方法都没出来,不得已而改用写Python代码来求面积了 二.思路介绍 1.用Python将上图画在坐标轴上,主要是斜线函数和半圆函数 2.均匀的在长方形上面洒满豆子(假设是豆子),求阴影部分豆子占比*总面积 三.源码设计 1.做图源码 import matplotlib.pyplot as plt import numpy as np def init(): plt.xla
-
Python求正态分布曲线下面积实例
正态分布应用最广泛的连续概率分布,其特征是"钟"形曲线.这种分布的概率密度函数为: 其中,μ为均值,σ为标准差. 求正态分布曲线下面积有3σ原则: 正态曲线下,横轴区间(μ-σ,μ+σ)内的面积为68.268949%,横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.449974%,横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.730020%. 求任意区间内曲线下的面积,通常可以引用scipy包中的相关函数 norm函数生成一个给定均值和标准差的正态分布,cdf(x
-
python KNN算法实现鸢尾花数据集分类
一.knn算法描述 1.基本概述 knn算法,又叫k-近邻算法.属于一个分类算法,主要思想如下: 一个样本在特征空间中的k个最近邻的样本中的大多数都属于某一个类别,则该样本也属于这个类别.其中k表示最近邻居的个数. 用二维的图例,说明knn算法,如下: 二维空间下数据之间的距离计算: 在n维空间两个数据之间: 2.具体步骤: (1)计算待测试数据与各训练数据的距离 (2)将计算的距离进行由小到大排序 (3)找出距离最小的k个值 (4)计算找出的值中每个类别的频次 (5)返回频次最高的类别 二.鸢
-
python基于K-means聚类算法的图像分割
1 K-means算法 实际上,无论是从算法思想,还是具体实现上,K-means算法是一种很简单的算法.它属于无监督分类,通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别. 1.1 算法思路 随机选取聚类中心 根据当前聚类中心,利用选定的度量方式,分类所有样本点 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心 计算下一次迭代的聚类中心与当前聚类中心的差距 如4中的差距小于给定迭代阈值时,迭代结束.反之,至2继续下
-
为什么说Python可以实现所有的算法
今天推荐一个Python学习的干货. 几个印度小哥,在GitHub上建了一个各种Python算法的新手入门大全,现在标星已经超过2.6万. 这个项目主要包括两部分内容:一是各种算法的基本原理讲解,二是各种算法的代码实现. 传送门在此: https://github.com/TheAlgorithms/Python 简单介绍下. 算法的基本原理讲解部分,包括排序算法.搜索算法.插值算法.跳跃搜索算法.快速选择算法.禁忌搜索算法.加密算法等. 这部分内容,主要介绍各种不同算法的原理,其中不少介绍还给
-
Python计算不规则图形面积算法实现解析
这篇文章主要介绍了Python计算不规则图形面积算法实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 介绍:大三上做一个医学影像识别的项目,医生在原图上用红笔标记病灶点,通过记录红色的坐标位置可以得到病灶点的外接矩形,但是后续会涉及到红圈内的面积在外接矩形下的占比问题,有些外接矩形内有多个红色标记,在使用网上的opencv的fillPoly填充效果非常不理想,还有类似python计算任意多边形方法也不理想的情况下,自己探索出的一种效果还不
-
Python递归函数 二分查找算法实现解析
一.初始递归 递归函数:在一个函数里在调用这个函数本身. 递归的最大深度:998 正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去.但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997(只要997!你买不了吃亏,买不了上当...). 拿什么来证明这个"998理论"呢?这里我们可以做一个实验: def foo(n): pr
-
使用Python检测文章抄袭及去重算法原理解析
在互联网出现之前,"抄"很不方便,一是"源"少,而是发布渠道少:而在互联网出现之后,"抄"变得很简单,铺天盖地的"源"源源不断,发布渠道也数不胜数,博客论坛甚至是自建网站,而爬虫还可以让"抄"完全自动化不费劲.这就导致了互联网上的"文章"重复性很高.这里的"文章"只新闻.博客等文字占据绝大部分内容的网页. 中文新闻网站的"转载"(其实就是抄)现象非
-
python Opencv计算图像相似度过程解析
这篇文章主要介绍了python Opencv计算图像相似度过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.相关概念 一般我们人区分谁是谁,给物品分类,都是通过各种特征去辨别的,比如黑长直.大白腿.樱桃唇.瓜子脸.王麻子脸上有麻子,隔壁老王和儿子很像,但是儿子下巴涨了一颗痣和他妈一模一样,让你确定这是你儿子. 还有其他物品.什么桌子带腿.镜子反光能在里面倒影出东西,各种各样的特征,我们通过学习.归纳,自然而然能够很快识别分类出新物品.
-
Python自定义计算时间过滤器实现过程解析
这篇文章主要介绍了Python自定义计算时间过滤器实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在写自定义的过滤器时,因为django.template.Library.filter()本身可以作为一个装饰器,所以可以使用: register = django.template.Library() @register.filter 代替 register.filter("过滤器名","函数名") 如果
-
Python cookbook(数据结构与算法)对切片命名清除索引的方法
本文实例讲述了Python对切片命名清除索引的方法.分享给大家供大家参考,具体如下: 问题:如何清理掉到处都是硬编码的切片索引 解决方案:对切片命名 假设有一些代码用来从字符串的固定位置中取出具体的数据(比如从一个平面文件或类似的格式:平面文件flat file是一种包含没有相对关系结构的记录文件): ########0123456789012345678901234567890123456789012345678901234567890123456789 record='...........
-
Python cookbook(数据结构与算法)从序列中移除重复项且保持元素间顺序不变的方法
本文实例讲述了Python从序列中移除重复项且保持元素间顺序不变的方法.分享给大家供大家参考,具体如下: 问题:从序列中移除重复的元素,但仍然保持剩下的元素顺序不变 解决方案: 1.如果序列中的值时可哈希(hashable)的,可以通过使用集合和生成器解决. # example.py # # Remove duplicate entries from a sequence while keeping order def dedupe(items): seen = set() for item i
-
Python实现基于POS算法的区块链
区块链中的共识算法 在比特币公链架构解析中,就曾提到过为了实现去中介化的设计,比特币设计了一套共识协议,并通过此协议来保证系统的稳定性和防攻击性. 并且我们知道,截止目前使用最广泛,也是最被大家接受的共识算法,是我们先前介绍过的POW(proof of work)工作量证明算法.目前市值排名前二的比特币和以太坊也是采用的此算法. 虽然POW共识算法取得了巨大的成功,但对它的质疑也从来未曾停止过. 其中最主要的一个原因就是电力消耗.据不完全统计,基于POW的挖矿机制所消耗的电量是非常巨大的,甚至比
-
python使用Word2Vec进行情感分析解析
python实现情感分析(Word2Vec) ** 前几天跟着老师做了几个项目,老师写的时候劈里啪啦一顿敲,写了个啥咱也布吉岛,线下自己就瞎琢磨,终于实现了一个最简单的项目.输入文本,然后分析情感,判断出是好感还是反感.看最终结果:↓↓↓↓↓↓ 1 2 大概就是这样,接下来实现一下. 实现步骤 加载数据,预处理 数据就是正反两类,保存在neg.xls和pos.xls文件中, 数据内容类似购物网站的评论,分别有一万多个好评和一万多个差评,通过对它们的处理,变成我们用来训练模型的特征和标记. 首先导
-
异常点/离群点检测算法——LOF解析
局部异常因子算法-Local Outlier Factor(LOF) 在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据.异常检测也是数据挖掘的一个方向,用于反作弊.伪基站.金融诈骗等领域. 异常检测方法,针对不同的数据形式,有不同的实现方法.常用的有基于分布的方法,在上.下α分位点之外的值认为是异常值(例如图1),对于属性值常用此类方法.基于距离的方法,适用于二维或高维坐标体系内异常点的判别,例如二维平面坐标或经纬度空间坐标下异常点识别,可