使用Python对Dicom文件进行读取与写入的实现
Pydicom
单张影像的读取
使用 pydicom.dcmread() 函数进行单张影像的读取,返回一个pydicom.dataset.FileDataset对象.
import os import pydicom # 调用本地的 dicom file folder_path = r"D:\Files\Data\Materials" file_name = "PA1_0001.dcm" file_path = os.path.join(folder_path,file_name) ds = pydicom.dcmread(file_path)
在一些特殊情况下,比如直接读取从医院拿到的数据(未经任何处理)时,可能会发生以下报错:
raise InvalidDicomError("File is missing DICOM File Meta Information "
pydicom.errors.InvalidDicomError: File is missing DICOM File Meta Information header or the 'DICM' prefix is missing from the header. Use force=True to force reading.
可以看到,由于缺失文件元信息头,无法直接读取,只能强行读取.这种情况可以直接根据提示,调整命令为:
ds = pydicom.dcmread(file_path,force=True)
但后续还会碰到:
AttributeError: 'Dataset' object has no attribute 'TransferSyntaxUID'
在网上检索后发现,可以通过设置TransferSyntaxUID来解决问题:
ds.file_meta.TransferSyntaxUID = pydicom.uid.ImplicitVRLittleEndian
这样就大功告成了(这里实际上就提前接触到了下面读取Dicom Tags的内容了)
一些简单处理
读取成功后,我们可以对 Dicom文件 进行一些简单的处理
读取并编辑Dicom Tags
可以通过两种方法来读取Tag的值
使用的Tag的Description
print(ds.PatientID,ds.StudyDate,ds.Modality)
使用 ds.get() 函数. 函数内参数采用的是Tag ID.几种简单的打开Dicom文件的软件(如RadiAnt DICOM Viewer)都可以直接看到.这里不再赘述.
ds.get(0x00100020) # 这里得到的是PatientID
读取到相应的Tag值后, 也可以将其他的值写入这些Tag.只要最后保存一下就可以了.
借助Numpy与PIL.Image
读取Dicom文件后,可以借助Numpy以及图像处理库(如PIL.Image)来进行简单的处理.
借助Numpy
import numpy as np data = np.array(ds.pixel_array)
注意这里使用的是 np.array() 而不是 np.asarray(). 因为前者的更改并不会带来原pixel_array的改变.
在转化为ndarray后 可以直接进行简单的切割和连接,比如截取某一部分和将两张图像拼在一起等,之后再写入并保存下来即可.
借助PIL.Image
from PIL import Image data_img = Image.fromarray(ds.pixel_array) data_img_rotated = data_img.rotate(angle=45,resample=Image.BICUBIC,fillcolor=data_img.getpixel((0,0)))
这里展示的是旋转, 还有其他功能如resize等.
需要注意的是,从Numpy的ndarray转化为Image时,一般会发生变化:
print(data.dtype) # int16 data_rotated = np.array(data_img_rotated) print(data_img) # int32
只需要指定参数就可以解决了
data_rotated = np.array(data_img_rotated,dtype = np.int16)
可视化
简单的可视化Pydicom没有直接的实现方法,我们可以通过上面借助Matplotlib以及Image模块来实现.但效果有限.
借助 Matplotlib (Pydicom官方文档中使用的方法)
from matplotlib import pyplot pyplot.imshow(ds.pixel_array,cmap=pyplot.cm.bone) pyplot.show()
效果如图所示:

但真实的图像是:
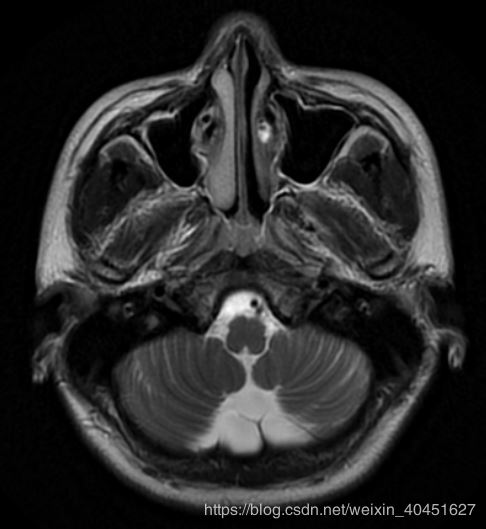
显然颜色是有区别的.导致这种差别的原因是pyplot函数使用的cm也就是"color map" 是简单的"bone" 并不能满足医学图像的要求.
借助Image模块
data_img.show()
一条指令即可,但是效果很差,如图所示:

综合来看,两种方法都不是很好.
单张影像的写入
经过上面对Tag值的修改, 对图像的切割, 旋转等操作.最后需要重新写入该Dicom文件.
ds.PixelData = data_rotated.tobytes() ds.Rows,ds.Columns = data_rotated.shape new_name = "dicom_rotated.dcm" ds.save_as(os.path.join(folder_path,new_name))
SimpleITK
SimpleITK 是从基于C++的ITK迁移到Python的,所以很多方法的使用都跟C++很相似.
import SimpleITK as sitk
单张影像的读取
有两种方法:
sitk.ReadImage()
这种方法直接返回image对象,简单易懂.但是无法读取Tag的值.
img = sitk.ReadImage(file_path) print(type(img)) # <class 'SimpleITK.SimpleITK.Image'>
sitk.ImageFileReader()
这种方法比较像C++的操作风格,需要先初始化一个对象,然后设置一些参数,最后返回image.相对更复杂,但可以操作的点比较多
file_reader = sitk.ImageFileReader() file_reader.SetFileName(file_path) #这里只显示了必需的,还有很多可以设置的参数 data = file_reader.Execute() # 使用这种方法读取Dicom的Tag Value for key in file_reader.GetMetaDataKeys(): print(key,file_reader.GetMetaData(key))
以上两种方法返回的都是三维的对象,这与Pydicom有很大的不同.
data_np = sitk.GetArrayFromImage(data) print(data_np.shape) # (1, 512, 512) = (Slice index, Rows, Columns)
序列读取
序列读取的方法与单张图像读取的第二种方法很相似.
(暂且只发现了一种方法读取序列,如果还有其他方法,请在评论区予以补充,感谢!)
series_reader = sitk.ImageSeriesReader() fileNames = series_reader.GetGDCMSeriesFileNames(folder_name) series_reader.SetFileNames(fileNames) images = series_reader.Execute()
同样,返回的也是三维的对象.
一些简单操作
SimpleITK 包含很多图像处理如滤波的工具,这里简单介绍一个边缘检测工具和可视化工具
边缘检测
以Canny边缘检测算子为例,与读取单张图像类似,同样有两种方式:
sitk.CannyEdgeDetection()
由于滤波的对象必须是32位图像或者其他格式, 需要通过 sitk.Cast() 转换. 之后可以再转换回原格式.
data_32 = sitk.Cast(data,sitk.sitkFloat32) data_edge_1 = sitk.CannyEdgeDetection(data_32,5,30,[5]*3,[0.8]*3)
sitk.CannyEdgeDetectionImageFilter()
这个操作相对麻烦一些
Canny = sitk.CannyEdgeDetectionImageFilter() Canny.SetLowerThreshold(5) Canny.SetUpperThreshold(30) Canny.SetVariance([5]*3) Canny.SetMaximumError([0.5]*3) data_edge_2 = Canny.Execute(data_32)
可视化
可视化的方法非常简单 只需要一条指令:
sitk.Show()
但需要先安装工具ImageJ,否则无法使用.具体的安装链接,可以参考这篇博文:sitk.show()与imageJ结合使用常见的问题
同一张Dicom文件使用sitk.Show()得到的效果如下图:

除此之外,ImageJ还有一个Tool Bar 支持对图像的进一步处理:

可见,SimpleITK的可视化要比上面介绍的强大很多,不仅可以实现单张图像的可视化以及图像处理,还可以同时对整个序列的图像进行统一处理.
单张影像的写入
同样有两种方法
sitk.WriteImage()
new_name = "new_MR_2.dcm" sitk.WriteImage(img,os.path.join(folder_name,new_name))
sitk.ImageFileWriter()
file_writer = sitk.ImageFileWriter() file_writer.SetFileName(os.path.join(folder_name,new_name)) file_writer.SetImageIO(imageio="GDCMImageIO") file_writer.Execute(img)
使用这两种方法进行写入的时候,会发现,即便什么也没有做,但得到的新Dicom文件要小于原始的Dicom文件.这是因为新的Dicom文件中没有Private Creator信息(属于Dicom Tag的内容).当然如果原始Dicom文件中本就没有这种信息,文件大小是保持相同的.
因为很多时候只是对图像进行处理,所以不再深究.
到此这篇关于使用Python对Dicom文件进行读取与写入的实现的文章就介绍到这了,更多相关Python Dicom文件进行读取与写入内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 读取dicom文件,生成info.txt和raw文件的方法
目标:利用python读取dicom文件,并进行处理生成info.txt和raw文件 实现:通过pydicom读取dicom文件 代码: import numpy import pydicom import os # dicom文件所在的文件夹目录 PathDicom = '/home/lk/testdata/1.3.6.1.4.1.9328.50.1.42697596859477567872763647333745089432/' # 筛选出文件夹目录下所有的dicom文件 lstFilesD
-
python 读取DICOM头文件的实例
用dicompyler软件打开dicom图像,头文件如图所示: 当然也可以直接读取: ds = dicom.read_file('H:\Data\data\\21662\\2.16.840.1.113662.2.0.105002416.1489146183.701\CT\\CT#0#21662#E7AB693D.dcm') print ds >> (0008, 0008) Image Type CS: ['ORIGINAL', 'SECONDARY', 'AXIAL'] (0008, 0016
-
python处理DICOM并计算三维模型体积
在已知DICOM和三维模型对应掩膜的情况下,计算三维模型的体积. 思路: 1.计算每个体素的体积.每个体素为长方体,x,y为PixelSpacing,z为层间距 使用pydicom.read_file读取DICOM文件,dcm_tag.PixelSpacing获取像素间距,dcm_tag.SliceLocation 获取层间距 2.计算体素的个数 代码如下: from PIL import Image import numpy as np import pydicom import os def
-
python读取dicom图像示例(SimpleITK和dicom包实现)
1. 用SimpleITK读取dicom序列: import SimpleITK as sitk import numpy as np img_path='F:\\dataset\\pancreas\\Output\\thick\\original\\1' mask_path='F:\\dataset\\pancreas\\Output\\thick\\groundtruth\\1' reader = sitk.ImageSeriesReader() img_names = reader.Get
-
python对DICOM图像的读取方法详解
DICOM介绍 DICOM3.0图像,由医学影像设备产生标准医学影像图像,DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线,CT,核磁共振,超声等),并且在眼科和牙科等其它医学领域得到越来越深入广泛的应用.在数以万计的在用医学成像设备中,DICOM是部署最为广泛的医疗信息标准之一.当前大约有百亿级符合DICOM标准的医学图像用于临床使用. 看似神秘的图像文件,究竟是如何读取呢?网上随便 一搜,都有很多方法,但缺乏比较系统的使用方法,下文综合百度资料,结合python2.7,
-
python 将dicom图片转换成jpg图片的实例
主要原理:调整dicom的窗宽,使之各个像素点上的灰度值缩放至[0,255]范围内. 使用到的python库:SimpleITK 下面是一个将dicom(.dcm)图片转换成jpg图片的demo: import SimpleITK as sitk import numpy as np import cv2 def convert_from_dicom_to_jpg(img,low_window,high_window,save_path): lungwin = np.array([low_win
-
Python解析多帧dicom数据详解
概述 pydicom是一个常用python DICOM parser.但是,没有提供解析多帧图的示例.本文结合相关函数和DICOM知识做一个简单说明. DICOM多帧数据存储 DICOM标准中关于多帧数据存储的最重要一部分说明是PS3.5 Annex A.4 A.4 Transfer Syntaxes For Encapsulation of Encoded Pixel Data. 无论何时,Pixel Data都存放在Pixel Data (7FE0,0010)中.有可能是直接存放的(nati
-
Python vtk读取并显示dicom文件示例
因为做项目的原因,所以接触到了医学图像dicom文件.vtk刚开始看,这里仅仅只是其最简单的读取显示功能.此处用到了vtk库,可自行百度安装方法. 下面附上代码: from vtk import * # reader the dicom file reader = vtkDICOMImageReader() reader.SetDataByteOrderToLittleEndian() reader.SetFileName("00efb2fedf64b867a36031a394e5855a.dc
-
使用Python对Dicom文件进行读取与写入的实现
Pydicom 单张影像的读取 使用 pydicom.dcmread() 函数进行单张影像的读取,返回一个pydicom.dataset.FileDataset对象. import os import pydicom # 调用本地的 dicom file folder_path = r"D:\Files\Data\Materials" file_name = "PA1_0001.dcm" file_path = os.path.join(folder_path,fi
-

聊聊Python对CSV文件的读取与写入问题
今天天气"刚刚好"(薛之谦么么哒),无聊的我翻到了一篇关于csv文件读取与写入的帖子,作为测试小白的我一直对python情有独钟,顿时心血来潮,决定小搞他一下,分享给那些需要的小白,对于python大神们来说,简直就是小儿科,对于我这种测试小白,看到代码就如同打了鸡血一样,恩恩,好东西,好东西! csv文件的读取: 前期工作:在定义的py文件里边创建一个excel文件,并另存为csv文件,放入三行数据,我这里是姓名+年龄(可以自己随意写) 首先我们要在python环境里导入csv板块(
-
Python中文件的读取和写入操作
从文件中读取数据 读取整个文件 这里假设在当前目录下有一个文件名为'pi_digits.txt'的文本文件,里面的数据如下: 3.1415926535 8979323846 2643383279 with open('pi_digits.txt') as f: # 默认模式为'r',只读模式 contents = f.read() # 读取文件全部内容 print contents # 输出时在最后会多出一行(read()函数到达文件末会返回一个空字符,显示出空字符就是一个空行) print '
-
python实现从文件中读取数据并绘制成 x y 轴图形的方法
如下所示: import matplotlib.pyplot as plt import numpy as np def readfile(filename): dataList = [] dataNum = 0 with open(filename,'r') as f: for line in f.readlines(): linestr = line.strip('\n') if len(linestr) < 8 and len(linestr) >1: dataList.append(f
-
Python从csv文件中读取数据及提取数据的方法
目录 1.从csv文件中读取数据 2.数据切割 数据保存在csv文件中 1.从csv文件中读取数据 参数header=None的有无 (1)没有header=None--直接将csv表中的第一行当作表头 # 读取数据 import pandas as pd data = pd.read_csv("data1.csv") print(data) 打印结果为: (2)有header=None--自动添加第一行当作表头 # 读取数据 import pandas as pd data = pd
-
Python 文本文件与csv文件的读取与写入
目录 一.文本文件读取与写入 1读取文件的read()方法 2读取文件的readline()方法 3读取文件的readlines()方法 4写入文件的write()方法 5写入文件的writelines()方法 二.csv文件读取与写入 一.文本文件读取与写入 1 读取文件的 read() 方法 file_object.read([size]) file_object 表示文件对象 size 表示读取数据的长度,单位是字节,如果size省略则读至文件尾 返回值是读取到的字符串 2 读取文件的 r
-
Python学习之文件的读取详解
目录 文件读取的模式 文件对象的读取方法 使用 read() 函数一次性读取文件全部内容 使用 readlines() 函数 读取文件内容 使用 readline() 函数 逐行读取文件内容 mode().name().closed() 函数演示 文件读取小实战 with open() 函数 利用with open() 函数读取文件的小实战 上一章节 我们学习了如何利用 open() 函数创建一个文件,以及如何在文件内写入内容:今天我们就来了解一下如何将文件中的内容读取出去来的方法. 文件读取的
-
Python 文本文件与csv文件的读取与写入
目录 一.文本文件读取与写入 1 读取文件的 read() 方法 2 读取文件的 readline() 方法 3 读取文件的 readlines() 方法 4 写入文件的 write() 方法 5 写入文件的 writelines() 方法 二.csv文件读取与写入 一.文本文件读取与写入 1 读取文件的 read() 方法 file_object.read([size]) file_object 表示文件对象 size 表示读取数据的长度,单位是字节,如果size省略则读至文件尾 返回值是读取
-
Python基于csv模块实现读取与写入csv数据的方法
本文实例讲述了Python基于csv模块实现读取与写入csv数据的方法.分享给大家供大家参考,具体如下: 通过csv模块可以轻松读取格式为csv的文件,而且csv模块是python内置的,不需要下载就可以直接用. 一.准备csv文件 文件名是 e:\t.csv,文件内容: org_id,org_name,state,emp_id 1,销售1,'1',123 2,销售2,'0',321 3,销售3,'1',231 1,,'1',1234 二.读取csv数据 代码非常简单: # -*- coding
-
Python学习之文件的创建与写入详解
目录 内置函数 - open 获取文件对象 open() 函数 利用文件对象进行创建与写入 文件操作的写入模式 文件对象的写入操作方法 实战小案例 在前面章节我们通过 os包学习了如何创建.读取一个文件夹,但是并没有学习如何创建.读写一个文件,接下来我们就学习关于文件的处理.当我们学习完文件处理之后,就可以随意读写文件. 内置函数 - open 获取文件对象 open() 函数 open()函数是是python的读写文件的基本函数,它可以生成文件对象可以创建,也可以操作文件的读写. 用法: op