关于多元线性回归分析——Python&SPSS
原始数据在这里
1.观察数据
首先,用Pandas打开数据,并进行观察。
import numpy
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('Folds5x2_pp.csv')
data.head()
会看到数据如下所示:

这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力)。我们不用纠结于每项具体的意思。
我们的问题是得到一个线性的关系,对应PE是样本输出,而AT/V/AP/RH这4个是样本特征, 机器学习的目的就是得到一个线性回归模型,即: PE=θ0+θ1∗AT+θ2∗V+θ3∗AP+θ4∗RH 而需要学习的,就是θ0,θ1,θ2,θ3,θ4这5个参数。
接下来对数据进行归一化处理:
data = (data - data.mean())/data.std()
因为回归线的截距θ0是不受样本特征影响的,因此我们在此可以设立一个X0=1,使得回归模型为:
PE=θ0*X0+θ1∗AT+θ2∗V+θ3∗AP+θ4∗RH
将方程向量化可得:
PE = hθ(x) = θx (θ应转置)
2.线性回归
在线性回归中,首先应建立 cost function,当 cost function 的值最小时所取得θ值为所求的θ。
在线性回归中,Cost function如下所示:

因此,可以在Python中建立函数求损失方程:
def CostFunction(X,y,theta): inner = np.power((X*theta.T)-y,2) return np.sum(inner)/(2*len(X))
然后,设初始θ为=[0,0,0,0,0],可得到最初的J(θ)值为0.49994774247491858,代码如下所示
col = data.shape[1] X = data.iloc[:,0:col-1] y = data.iloc[:,col-1:col] X = np.matrix(X.values) y = np.matrix(y.values) theta = np.matrix(np.array([0,0,0,0,0])) temp = np.matrix(np.zeros(theta.shape)) CostFunction(X,y,theta)
接下来,有两种方法可以使用。1.梯度下降法(gradient descent)和 2.最小二乘法(normal equation)。在此我们使用梯度下降法来求解。
梯度下降法是求得J对θ的偏导数,通过设置步长,迭代使J(θ)逐步下降,从而求得局部最优解。
公式如下所示:

j:特征编号
m:样本编号
我们可以在Python中写出计算迭代后的θ和J(θ)
def gradientDescent(X,y,theta,alpha,iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X*theta.T)-y
for j in range(parameters):
term = np.multiply(error,X[:,j])
temp[0,j] = theta[0,j] - (alpha/len(X))*np.sum(term)
theta = temp
cost[i] = CostFunction(X,y,theta)
return theta,cost
在此,我设置初始的α为0.1,可求得迭代1000次后θ0,θ1,θ2,θ3,θ4的值分别是:
-5.22080706e-14,-8.63485491e-01,-1.74182863e-01,2.16058120e-02,-1.35205248e-01
此时 J(θ)的值为0.0379648。
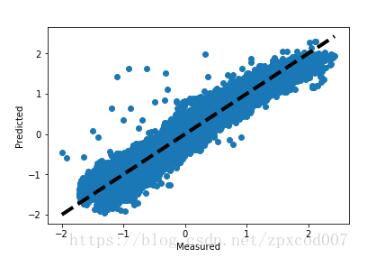
通过,可视化J(θ)和迭代次数可以发现,J(θ)收敛的非常快。

画图观察预测值和损失值,距离直线约近说明损失越小:
predicted = X*g.T
predicted = predicted.flatten().A[0]
y_f= y.flatten().A[0]
fig, ax = plt.subplots()
ax.scatter(y_f,predicted)
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()
3.sckit-learn
因为J(θ)收敛的太快了…所以我又用sckit-learn和SPSS验证了一下。
先看sckit-learn,在sklearn中,线性回归是使用的最小二乘法而不是梯度下降法,用起来也十分的简单。
代码如下:
from sklearn import linear_model model = linear_model.LinearRegression() model.fit(X, y)
打印出θ值后发现和梯度下降法算出来的相差无几,θ0,θ1,θ2,θ3,θ4的值分别是:
0,-0.86350078,-0.17417154,0.02160293,-0.13521023
4.SPSS
在看看SPSS
同样先将数据标准化后进行线

然后进行线性回归分析得到结果:

嘛…和前面两种方法的结果也差不多…就这样吧。
以上这篇关于多元线性回归分析——Python&SPSS就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
sklearn+python:线性回归案例
使用一阶线性方程预测波士顿房价 载入的数据是随sklearn一起发布的,来自boston 1993年之前收集的506个房屋的数据和价格.load_boston()用于载入数据. from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import time from sklearn.linear_model import LinearRegression bosto
-
关于多元线性回归分析——Python&SPSS
原始数据在这里 1.观察数据 首先,用Pandas打开数据,并进行观察. import numpy import pandas as pd import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('Folds5x2_pp.csv') data.head() 会看到数据如下所示: 这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力).我
-

R语言与多元线性回归分析计算案例
目录 计算实例 分析 模型的进一步分析 计算实例 例 6.9 某大型牙膏制造企业为了更好地拓展产品市场,有效地管理库存,公司董事会要求销售部门根据市场调查,找出公司生产的牙膏销售量与销售价格,广告投入等之间的关系,从而预测出在不同价格和广告费用下销售量.为此,销售部门的研究人员收集了过去30个销售周期(每个销售周期为4周)公司生产的牙膏的销售量.销售价格.投入的广告费用,以及周期其他厂家生产同类牙膏的市场平均销售价格,如表6.4所示. 试根据这些数据建立一个数学模型,分析牙膏销售量与其他因素的关
-
Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧! """ # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围. #验证就会发现任
-
如何用Python进行回归分析与相关分析
目录 一.前言 1.1 回归分析 1.2 相关分析 二.代码的编写 2.1 前期准备 2.2 编写代码 2.2.1 相关分析 2.2.2 一元线性回归分析 2.2.3 多元线性回归分析 2.2.4 广义线性回归分析 2.2.5 logistic回归分析 三.代码集合 一.前言 1.1 回归分析 是用于研究分析某一变量受其他变量影响的分析方法,其基本思想是以被影响变量为因变量,以影响变量为自变量,研究因变量与自变量之间的因果关系. 1.2 相关分析 不考虑变量之间的因果关系而只研究变量之间的相关关
-
Python多项式回归的实现方法
多项式回归是一种线性回归形式,其中自变量x和因变量y之间的关系被建模为n次多项式.多项式回归拟合x的值与y的相应条件均值之间的非线性关系,表示为E(y | x) 为什么多项式回归: 研究人员假设的某些关系是曲线的.显然,这种类型的案例将包括多项式项. 检查残差.如果我们尝试将线性模型拟合到曲线数据,则预测变量(X轴)上的残差(Y轴)的散点图将在中间具有许多正残差的斑块.因此,在这种情况下,这是不合适的. 通常的多元线性回归分析的假设是所有自变量都是独立的.在多项式回归模型中,不满足该假设. 多项
-
Python机器学习入门(五)算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位. --
-
Python机器学习入门(五)之Python算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.3分类与回归树 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它
-
R语言实现线性回归的示例
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析. 简单对来说就是用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析.如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析. 一元线性回归分析法的数学方程: y = ax + b
-
Tensorflow 实现线性回归模型的示例代码
目录 1.线性与非线性回归 案例讲解 1.数据集 2.读取训练数据Income.csv并可视化展示 3.利用Tensorflow搭建和训练神经网络模型[线性回归模型的建立] 4. 模型预测 1.线性与非线性回归 线性回归 Linear Regression:两个变量之间的关系是一次函数关系的——图像是直线,叫做线性.线性是指广义的线性,也就是数据与数据之间的关系,如图x1. 非线性回归:两个变量之间的关系不是一次函数关系的——图像不是直线,叫做非线性,如图x2. 一元线性回归:只包括一个自变量和
-
python实现机器学习之多元线性回归
总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便. 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: import numpy as np def linearRegression(data_X,data_Y,learningRate,loopNum): W = np.zeros(shape=[1, data_X.shape[1]]) # W的shape取决于特征个数,而x的行是样本个数,x的列是特征值个数 # 所需要的W的形式为 行=特征个数,列=1 这