Python统计学一数据的概括性度量详解
一、数据的概括性度量
1、统计学概括:
统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策提供依据和参考。统计学主要又分为描述统计学和推断统计学。给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学。另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学。
2、数据的概括性度量:
1)集中趋势的度量:
众数:众数(Mode),是一组数据中出现次数最多的数值,叫众数,有时众数在一组数中有好几个。用M表示。
中位数:中位数(Median)是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数用Me表示。计算公式:
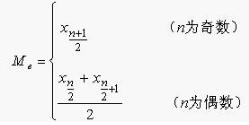
四分位数:四分位数(Quartile)把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。QL=下四分位数,即第25百分位数( n / 4);QU=上四分位数,即第75百分位数( 3n / 4)。
平均数:算术平均数(arithmetic mean)算术平均数是指资料中各观测值的总和除以观测值个数所得的商,简称平均数或均数。
2)离散趋势的度量:
四分位差:四分位差(quartile deviation),也称为内距或四分间距(inter-quartile range),它是上四分位数(QU,即位于75%)与下四分位数(QL,即位于25%)的差。
极差:全距(Range),又称极差,是用来表示统计资料中的变异量数(measures of variation),其最大值与最小值之间的差距
方差:方差(variance)(样本方差)是各个数据分别与其平均数之差的平方的和的平均数,通常以σ2表示,方差的计算公式为:
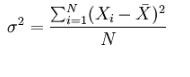
标准差:标准差 (Standard Deviation),也称均方差(Mean square error), 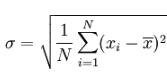 。
。
离散系数:离散系数又称变异系数,CV(Coefficient of Variance)表示。CV(Coefficient of Variance):标准差与均值的比值。离散系数越小,数据的离散程度就越小,反之,亦然。
3)偏度与峰度的度量:
偏态系数:偏度(Skewness)亦称偏态、偏态系数,偏度是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。Sk>0时,分布呈正偏态(右偏),Sk<0时,分布呈负偏态(左偏)。
峰态系数:(Kurtosis)峰度系数是用来反映频数分布曲线顶端尖峭或扁平程度的指标。在正态分布情况下,峰度系数值是3。>3的峰度系数说明观察量更集中,有比正态分布更短的尾部;<3的峰度系数说明观测量不那么集中,有比正态分布更长的尾部,类似于矩形的均匀分布。峰度系数的标准误用来判断分布的正态性。峰度系数与其标准误的比值用来检验正态性。如果该比值绝对值大于2,将拒绝正态性。
3、Python代码实现:
<span style="font-family:Microsoft YaHei;font-size:12px;">#以下代码基于Python3.5环境编写
import numpy as np
import stats as sts
scores = [31, 24, 23, 25, 14, 25, 13, 12, 14, 23,
32, 34, 43, 41, 21, 23, 26, 26, 34, 42,
43, 25, 24, 23, 24, 44, 23, 14, 52,32,
42, 44, 35, 28, 17, 21, 32, 42, 12, 34]
#集中趋势的度量
print('求和:',np.sum(scores))
print('个数:',len(scores))
print('平均值:',np.mean(scores))
print('中位数:',np.median(scores))
print('众数:',sts.mode(scores))
print('上四分位数',sts.quantile(scores,p=0.25))
print('下四分位数',sts.quantile(scores,p=0.75))
#离散趋势的度量
print('最大值:',np.max(scores))
print('最小值:',np.min(scores))
print('极差:',np.max(scores)-np.min(scores))
print('四分位差',sts.quantile(scores,p=0.75)-sts.quantile(scores,p=0.25))
print('标准差:',np.std(scores))
print('方差:',np.var(scores))
print('离散系数:',np.std(scores)/np.mean(scores))
#偏度与峰度的度量
print('偏度:',sts.skewness(scores))
print('峰度:',sts.kurtosis(scores))</span>
以上这篇Python统计学一数据的概括性度量详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现PCA降维的示例详解
概述 本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析).降维致力于解决三类问题. 1. 降维可以缓解维度灾难问题: 2. 降维可以在压缩数据的同时让信息损失最小化: 3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解. PCA简介 在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难.随着数据集维度的增加,算法学习需要的样本数量呈指数级增加.有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习
-
Python数据可视化库seaborn的使用总结
seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看.http://seaborn.pydata.org/ 从官网的主页我们就可以看出,seaborn在数据可视化上真的非常强大. 1.首先我们还是需要先引入库,不过这次要用到的python库比较多. import numpy as np import pandas as pd import matplotlib as mpl import matpl
-
Python计算库numpy进行方差/标准方差/样本标准方差/协方差的计算
使用numpy可以做很多事情,在这篇文章中简单介绍一下如何使用numpy进行方差/标准方差/样本标准方差/协方差的计算. variance: 方差 方差(Variance)是概率论中最基础的概念之一,它是由统计学天才罗纳德·费雪1918年最早所提出.用于衡量数据离散程度,因为它能体现变量与其数学期望(均值)之间的偏离程度.具有相同均值的数据,而标准差可能不同,而通过标准差的大小则能更好地反映出数据的偏离度. 计算:一组数据1,2,3,4,其方差应该是多少? 计算如下: 均值=(1+2+3+4)/
-
Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主要又分为描述统计学和推断统计学.给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学.另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学. 2.数据的概括性度量: 1)集中趋势的度量: 众数:众数(Mode
-

python FastApi实现数据表迁移流程详解
目录 啥是数据迁移 1.需要新的数据表 2.需要对现有表结构进行调整 回到ORM 迁移手段 安装alembic 初始化项目 修改alembic.ini 修改alembic/env.py 开始生成迁移工作 变更数据库 FAQ 啥是数据迁移 在我们平时的开发过程中,经常需要对一些数据进行调整.一般会有以下几种场景: 1.需要新的数据表 我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能. 大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库)
-
使用python将excel数据导入数据库过程详解
因为需要对数据处理,将excel数据导入到数据库,记录一下过程. 使用到的库:xlrd 和 pymysql (如果需要写到excel可以使用xlwt) 直接丢代码,使用python3,注释比较清楚. import xlrd import pymysql # import importlib # importlib.reload(sys) #出现呢reload错误使用 def open_excel(): try: book = xlrd.open_workbook("XX.xlsx")
-
python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0,1]区间.方便数据的处理.消除单位影响及变异大小因素影响. 基本公式为: x'=(x-min)/(max-min) 代码: #!/user/bin/env python #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplo
-
Python数据存储之 h5py详解
1.Python数据存储(压缩) (1)numpy.save , numpy.savez , scipy.io.savemat numpy和scipy内建的数据存储方式. (2)cPickle + gzip cPickle是pickle内建的数据存储方式,gzip是常用的文件压缩模块. (3)h5py h5py是对HDF5文件格式进行读写的python包,关于h5py更多介绍与安装,参考官方网站 关于HDF5,参考官方网站.: 一个HDF5文件就是一个由两种基本数据对象(groups and d
-
python数据XPath使用案例详解
目录 XPath XPath使用方法 xpath解析原理: 安装lxml 案例-58二手房 XPath XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath使用方法 xpath解析原理: 1.实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获 安装lxml pip install -i https://mirro
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python实现数据的序列化操作详解
目录 Json 模块 dumps()函数 dump()函数 loads()函数 load()函数 Pickle 模块 dumps()函数 dump()函数 loads()函数 load()函数 总结 在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块.这两个模块主要区别如下: json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式: json 是我们可以直观阅读的,而 p
-
Python Matplotlib数据可视化模块使用详解
目录 前言 1 matplotlib 开发环境搭建 2 绘制基础 2.1 绘制直线 2.2 绘制折线 2.3 设置标签文字和线条粗细 2.4 绘制一元二次方程的曲线 y=x^2 2.5 绘制正弦曲线和余弦曲线 3 绘制散点图 4 绘制柱状图 5 绘制饼状图 6 绘制直方图 7 绘制等高线图 8 绘制三维图 总结 本文主要介绍python 数据可视化模块 Matplotlib,并试图对其进行一个详尽的介绍. 通过阅读本文,你可以: 了解什么是 Matplotlib 掌握如何用 Matplotlib