TensorFlow人工智能学习数据合并分割统计示例详解
目录
- 一、数据合并与分割
- 1.tf.concat()
- 2.tf.split()
- 3.tf.stack()
- 二、数据统计
- 1.tf.norm()
- 2.reduce_min/max/mean()
- 3.tf.argmax/argmin()
- 4.tf.equal()
- 5.tf.unique()
一、数据合并与分割
1.tf.concat()
填入两个tensor, 指定某维度,在指定的维度合并。除了合并的维度之外,其他的维度必须相等。

2.tf.split()
填入tensor,指定维度,指定分割的数量。例如原数据维度是[2,4,35,8],当分割数量指定为2,维度是最后一维时,会分割成两个tensor,维度均是[2,4,35,4]。分割的维度,也可以直接指定数量及维度。比如指定为[2,2,4],则会分成三个tensor,最后一个维度分别是2,2,4。

3.tf.stack()
该方法会创造新的维度。要求两个合并的数据维度全部一样,在哪个维度合并,就会在哪个维度前面产生一个新维度,可以根据这个维度进行选择。

二、数据统计
注意:tf中指定维度的时候,就是把指定的维度上的内容进行操作,保留剩下的维度。
比如(2,3),求范数,如果指定axis=1,也就是列,那就是说,使用列上的3个数据,去求范数。得到的就是2维向量。也就是,指定了哪个维度,就会消去哪个维度。
1.tf.norm()
求范数,如果不指定几范数就是二范数。

指定ord=1就是1范数。可以指定维度,就是把指定的维度上的内容求范数,保留剩下的维度。
比如(2,3),如果指定axis=1,也就是列,那就是说,使用列上的3个数据,去求范数。得到的就是2维向量。也就是,指定了哪个维度,就会消去哪个维度。

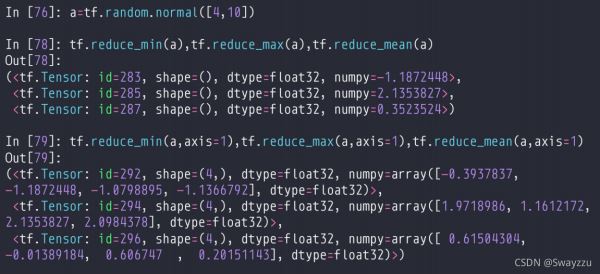
2.reduce_min/max/mean()
求数据的最小值、最大值、均值。这里有一个reduce,意思是提醒我们维度会降低。
3.tf.argmax/argmin()
返回最大值、最小值的索引,如果不指定维度,那就是默认把第0维的求出来。

4.tf.equal()
填入两个tensor,形状需要一样,返回一样形状的布尔tensor,可以通过先转换成整型(1,0),再累加的方式,求得两个tensor中相同数据的数量。

5.tf.unique()
和numpy中的unique一样。

以上就是TensorFlow人工智能学习数据合并分割统计示例详解的详细内容,更多关于TensorFlow数据合并分割统计的资料请关注我们其它相关文章!
相关推荐
-
TensorFlow2.0:张量的合并与分割实例
** 一 tf.concat( ) 函数–合并 ** In [2]: a = tf.ones([4,35,8]) In [3]: b = tf.ones([2,35,8]) In [4]: c = tf.concat([a,b],axis=0) In [5]: c.shape Out[5]: TensorShape([6, 35, 8]) In [6]: a = tf.ones([4,32,8]) In [7]: b = tf.ones([4,3,8]) In [8]: c = tf.conca
-

TensorFlow2基本操作之合并分割与统计
目录 合并与分割 tf.concat tf.stack tf.unstack tf.split 数据统计 tf.norm reduce_min/max/mean argmax / argmin tf.equal tf.unique 合并与分割 tf.concat tf.concat可以帮助我们实现拼接操作. 格式: tf.concat( values, axis, name='concat' ) 参数: values: 一个 tensor 或 tensor list axis: 操作的维度 na
-
使用Tensorflow将自己的数据分割成batch训练实例
学习神经网络的时候,网上的数据集已经分割成了batch,训练的时候直接使用batch.next()就可以获取batch,但是有的时候需要使用自己的数据集,然而自己的数据集不是batch形式,就需要将其转换为batch形式,本文将介绍一个将数据打包成batch的方法. 一.tf.slice_input_producer() 首先需要讲解两个函数,第一个函数是 :tf.slice_input_producer(),这个函数的作用是从输入的tensor_list按要求抽取一个tensor放入文件名队列
-
TensorFlow 合并/连接数组的方法
如下所示: import tensorflow as tf a = tf.Variable([4,5,6]) b = tf.Variable([1,2,3]) c = tf.concat(0,[a,b]) init_op = tf.initialize_all_variables() with tf.Session() as sess: sess.run(init_op) print(sess.run(c)) 结果打印: [4 5 6 1 2 3] 以上这篇TensorFlow 合并/连接数组的
-
Tensorflow进行多维矩阵的拆分与拼接实例
最近在使用tensorflow进行网络训练的时候,需要提取出别人训练好的卷积核的部分层的数据.由于tensorflow中的tensor和python中的list不同,无法直接使用加法进行拼接,后来发现一个函数可以完成tensor的拼接. 函数形式如下: tf.concat(concat_dim,values,name='concat') 其中,第一个参数表示需要拼接的多维tensor,并且可以将多个tensor同事拼接,第二个表示按照哪一个维度拼接(从数字0开始). 例子:创建一个三维的tens
-
TensorFlow人工智能学习数据合并分割统计示例详解
目录 一.数据合并与分割 1.tf.concat() 2.tf.split() 3.tf.stack() 二.数据统计 1.tf.norm() 2.reduce_min/max/mean() 3.tf.argmax/argmin() 4.tf.equal() 5.tf.unique() 一.数据合并与分割 1.tf.concat() 填入两个tensor, 指定某维度,在指定的维度合并.除了合并的维度之外,其他的维度必须相等. 2.tf.split() 填入tensor,指定维度,指定分割的数量
-
TensorFlow人工智能学习数据填充复制实现示例
目录 1.tf.pad() 2.tf.tile() 1.tf.pad() 该方法能够给数据周围填0,填的参数是:需要填充的数据+填0的位置 填0的位置是一个数组形式,对应如下:[[上行,下行],[左列,右列]],具体例子如下: 较为常用的是上下左右各一行. 给图片进行padding的时候,通常数据的维度是[b,h,w,c],那么增加两行,两列的话,是在中间的h和w增加: 2.tf.tile() 该方法可以复制数据,需要填的参数:数据,维度+对应的复制次数. broadcast_to = expa
-
人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
MySQL教程数据定义语言DDL示例详解
目录 1.SQL语言的基本功能介绍 2.数据定义语言的用途 3.数据库的创建和销毁 4.数据库表的操作(所有演示都以student表为例) 1)创建表 2)修改表 3)销毁表 如果你是刚刚学习MySQL的小白,在你看这篇文章之前,请先看看下面这些文章.有些知识你可能掌握起来有点困难,但请相信我,按照我提供的这个学习流程,反复去看,肯定可以看明白的,这样就不至于到了最后某些知识不懂却不知道从哪里下手去查. <MySQL详细安装教程> <MySQL完整卸载教程> <这点基础都不懂
-
Go语言学习教程之反射的示例详解
目录 介绍 反射的规律 1. 从接口值到反射对象的反射 2. 从反射对象到接口值的反射 3. 要修改反射对象,该值一定是可设置的 介绍 reflect包实现运行时反射,允许一个程序操作任何类型的对象.典型的使用是:取静态类型interface{}的值,通过调用TypeOf获取它的动态类型信息,调用ValueOf会返回一个表示运行时数据的一个值.本文通过记录对reflect包的简单使用,来对反射有一定的了解.本文使用的Go版本: $ go version go version go1.18 dar
-
Git基础学习之分支操作的示例详解
目录 1.新建一个分支并且使分支指向指定的提交对象 2.思考 3.项目分叉历史的形成 4.分支的总结 1.新建一个分支并且使分支指向指定的提交对象 使用命令:git branch branchname commitHash. 我们现在本地库中只有一个 master 分支,并且在 master 分支有三个提交历史. 需求:创建一个 testing 分支,并且testing 分支指向 master 分支第二个版本. # 1.查看提交历史记录 L@DESKTOP-T2AI2SU MINGW64 /j/
-
MySQL实现数据插入操作的示例详解
目录 一.方法分类 二.具体方法 三.实例 (1)常规插入 (2)从另一个表导入 (3)插入时数据重复 四.注意事项 (1)不写字段名,需要填充自增ID (2)按字段名填充,可以不录入id 其余注意事项 使用MySQL插入数据时,可以根据需求场景选择合适的插入语句,例如当数据重复时如何插入数据,如何从另一个表导入数据,如何批量插入数据等场景.本文通过给出每个使用场景下的实例来说明数据插入的实现过程和方法. 一.方法分类 二.具体方法 使用场景 作用 语句 注意 常规插入 忽略字段名 insert
-
React学习笔记之列表渲染示例详解
前言 本文主要给大家介绍了关于React列表渲染的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例详解: 列表渲染也很简单,利用map方法返回一个新的渲染列表即可,例如: const numbers = [1, 2, 3, 4, 5]; const listItems = numbers.map((number) => <li>{number}</li> ); ReactDOM.render( <ul>{listItems}<