FastAPI 部署在Docker的详细过程
Docker 学习
https://www.cnblogs.com/poloyy/p/15257059.html
项目结构
. ├── app │ ├── __init__.py │ └── main.py ├── Dockerfile └── requirements.txt
FastAPI 应用程序 main.py 代码
from typing import Optional
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Optional[str] = None):
return {"item_id": item_id, "q": q}
Dockerfile
# 1、从官方 Python 基础镜像开始 FROM python:3.9 # 2、将当前工作目录设置为 /code # 这是放置 requirements.txt 文件和应用程序目录的地方 WORKDIR /code # 3、先复制 requirements.txt 文件 # 由于这个文件不经常更改,Docker 会检测它并在这一步使用缓存,也为下一步启用缓存 COPY ./requirements.txt /code/requirements.txt # 4、运行 pip 命令安装依赖项 RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt # 5、复制 FastAPI 项目代码 COPY ./app /code/app # 6、运行服务 CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
第四步:运行 pip 命令解析
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
- --no-cache-dir 选项告诉pip不要将下载的包保存在本地,因为只有当pip 将再次运行以安装相同的包时才会这样,但在使用容器时情况并非如此
- --no-cache-dir只与pip有关,与 Docker或容器无关
- --upgrade选项告诉 pip升级已经安装的软件包
- 因为上一步复制文件可能会被Docker 缓存检测到,所以这一步也会在Docker 缓存可用时使用
- 在这一步中使用缓存会在开发过程中一次又一次地构建镜像时节省大量时间,而不是每次都下载并安装所有依赖项
Docker 缓存
这里有一个重要的技巧Dockerfile,首先只复制依赖项的文件,而不是 FastAPI 应用程序代码
./requirements.txt /code/requirements.txt
- Docker 和其他工具以增量方式构建这些容器映像,在另一层之上添加一层
- 从 Dockerfile 的顶部(首行)开始,由 Dockerfile 的每个指令来创建任何文件
- Docker 和其他工具在构建镜像时也是用内部缓存
- 如果文件自上次构建容器镜像后没有更改,则它将重用上次创建的同一层,而不是再次复制文件并从头开始创建一个新的层
- 仅仅避免文件副本并不一定会改善太多,但是因为它在该步骤中使用了缓存,所以它可以在下一步中使用缓存
- 例如,它可以将缓存用于安装依赖项的指令
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
- requirements.txt 不会经常改变,所以通过复制该文件,Docker 可以在该步骤中使用缓存
- Docker 将能够使用缓存进行下一步下载和安装这些依赖项,这就是节省大量时间的地方
- 下载并安装该软件包的依赖关系可能需要几分钟,但使用的缓存将只需要几秒
- 由于在开发过程中一次又一次地构建容器镜像以检查代码更改是否有效,因此可以节省大量累积时间
./app /code/app
- 在 Dockerfile 尾部,复制 FastAPI 应用程序代码
- 由于这是最常更改的内容,因此将其放在最后,在此步骤之后的任何内容都将无法使用缓存
构建 Docker Image
在 Dockerfile 打开命令行
docker build -t myimage .
查看镜像
docker images

启动 docker 容器
docker run -d --name mycontainer -p 80:80 myimage
查看容器
docker ps

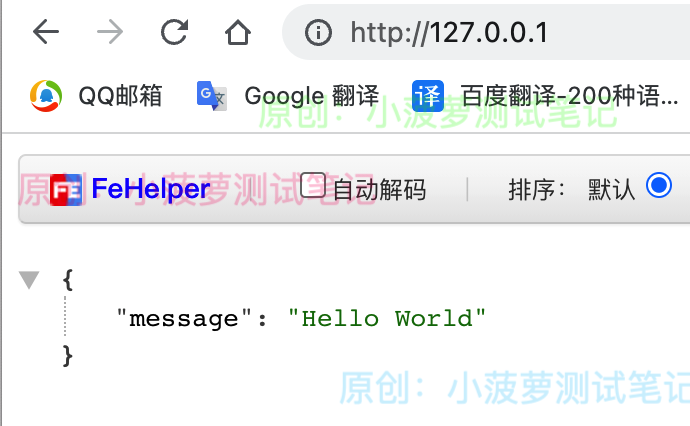
访问 127.0.0.1/
访问 127.0.0.1/docs

带有 Gunicorn 的官方 Docker 镜像 - Uvicorn
- 此镜像包含一个自动调整机制,可根据可用的 CPU 内核设置工作进程的数量
- 它具有合理的默认值,但仍然可以使用环境变量或配置文件更新所有配置
- 此镜像上的进程数是根据可用的 CPU 内核自动计算的,它将尝试从 CPU 中榨取尽可能多的性能
- 但这也意味着,由于进程数取决于容器运行的 CPU,消耗的内存量也将取决于此
- 因此,如果应用程序消耗大量内存(例如使用机器学习模型),并且服务器有很多 CPU 内核但内存很少,容器最终可能会使用比可用内存更多的内存,这会大大降低性能(甚至崩溃)
官方栗子
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9 COPY ./requirements.txt /app/requirements.txt RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt COPY ./app /app
应用场景
- 如果正在使用Kubernetes,并且已经设置了集群级别的复制,就不应该使用此镜像,最好从头开始构建镜像
- 如果应用程序足够简单,以至于根据 CPU 设置默认进程数效果很好,不想费心在集群级别手动配置复制,并且运行的容器不会超过一个应用程序
- 或者如果使用Docker Compose进行部署,在单个服务器上运行等
使用 poetry 的 docker image
# 第一阶段:将仅用于安装 Poetry 并从 Poetry 的 pyproject.toml 文件生成带有项目依赖项的 requirements.txt。 FROM tiangolo/uvicorn-gunicorn:python3.9 as requirements-stage # 将 /tmp 设置为当前工作目录;这是我们将生成文件requirements.txt的地方 WORKDIR /tmp # 安装 poetry RUN pip install poetry # 复制 COPY ./pyproject.toml ./poetry.lock* /tmp/ # 生成 requirements.txt RUN poetry export -f requirements.txt --output requirements.txt --without-hashes # 这是最后阶段,在这往后的任何内容都将保留在最终容器映像中 FROM python:3.9 # 将当前工作目录设置为 /code WORKDIR /code # 复制 requirements.txt;这个文件只存在于前一个 Docker 阶段,这就是使用 --from-requirements-stage 复制它的原因 COPY --from=requirements-stage /tmp/requirements.txt /code/requirements.txt # 运行命令 RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt # 复制 COPY ./app /code/app # 运行服务 CMD ["uvicorn", "app.1_快速入门:app", "--host", "0.0.0.0", "--port", "80"]
- 第一阶段 Docker 是 Dockerfile 的一部分,它作为一个临时容器的镜像是仅用于生成一些文件供后面阶段使用
- 使用 Poetry 时,使用Docker 多阶段构建是有意义的
- 因为实际上并不需要在最终容器镜像中安装 Poetry 及其依赖项,只需要生成的requirements.txt 文件来安装项目依赖项
poetry 详细教程
https://www.jb51.net/article/195070.htm
到此这篇关于FastAPI 部署在 Docker的文章就介绍到这了,更多相关FastAPI 部署在 Docker 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用docker部署spring boot并接入skywalking的方法
一.概述 最近在研究skywalking,打算使用k8s部署 skywalking 并将 pod 中的应用接入 skywalking 进行服务链路追踪.这篇文章先不介绍 skywalking 在k8s中的部署和使用,而是先介绍如何使用手动和docker的方式使用 skywalking.在整个实践过程中查阅了大量文档,遇到了各种问题,这里将我自己的实践过程记录下来,希望对有同样需求的小伙伴提供一些帮助. 1.skywalking 简介 SkyWalking是一款广受欢迎的国产APM(Applica
-
docker安装部署 onlyoffice的详细过程
0. 系统要求 中央处理器 I5-10400F以上 内存 16 GB,最佳32G内存 硬盘 至少40 GB的可用空间 1:安装Docker Desktop 2:进入BIOS设置CPU的虚拟化 https://jingyan.baidu.com/article/ab0b56305f2882c15afa7dda.html 3:启动Docker desktop 报错解决:https://www.jb51.net/article/214820.htm 3:cmd进入,使用命令安装onlyoffice 安
-
简简单单使用Docker部署Confluence
一.环境要求 1.已安装docker17及以上版本 二.容器运行 docker run -d --name confluence -p 8090:8090 --user root:root cptactionhank/atlassian-confluence 然后等待镜像拉取 启动完成之后,直接浏览器访问: http://${Server}:8090/ 下面看下Docker 部署Confluence15.2 一.数据库准备数据库版本:5.7 这里数据库并没有采用docker镜像方式,而是选择已有
-
FastAPI 部署在Docker的详细过程
Docker 学习 https://www.cnblogs.com/poloyy/p/15257059.html 项目结构 . ├── app │ ├── __init__.py │ └── main.py ├── Dockerfile └── requirements.txt FastAPI 应用程序 main.py 代码 from typing import Optional from fastapi import FastAPI app = FastAPI() @app.get("/&qu
-
使用Gitee自动化部署python脚本的详细过程
一.前期准备 1.1 安装环境 1.安装python3 2.打开命令行安装selenium pip install selenium 二.python代码 2.1 源码 #!/usr/bin/python # -*- coding: utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.alert import Alert # 模拟浏览器打开到gitee登录界面 driver = w
-
Ubuntu 20.04 上安装和使用 Docker的详细过程(安装包)
目录 一.解压文件 二.拷贝解压后的文件到/usr/bin/下面 三.加入系统文件 四.启动Docker 五.Docker配置文件 六.重启Docker 七.检查Docker是否安装成功 八.总结 安装前将所有的软件包上传到系统的/opt路径,所有的操作都在/opt目录下 一.解压文件 tar -xzvf docker-19.03.0.tgz 二.拷贝解压后的文件到/usr/bin/下面 cp docker/* /usr/bin/ 三.加入系统文件 cat >/etc/systemd/syste
-
SpringBoot 整合 Docker的详细过程
目录 1. Demo Project 1.1 接口准备 1.2 配置准备 2. Docker 开启远程连接 1.1 修改配置文件 1.2 刷新配置.重启 1.3 认证登录 3. IDEA 安装 Docker 插件 4. Maven 添加 Docker 插件 5. 编写Dockerfile 6. 打包项目 7. 创建容器 8. 校验部署 最近备忘录新加的东西倒是挺多的,但到了新环境水土不服没动力去整理笔记 1. Demo Project 首先准备一个简单的项目,用来部署到 Docker 主机上,并
-
idea整合docker快速部署springboot应用的详细过程
目录 一.前言 二.环境及工具 三.安装docker以及配置远程连接 四.idea连接远程docker 一.前言 容器化一词相信大家已经不陌生了,听到它我们可能会想到docker.k8s.jenkins.rancher等等.那么今天我来说一下idea如何使用docker快速部署springboot应用. 二.环境及工具 windows10(开发) centos 7.6 (部署) idea docker xshell 三.安装docker以及配置远程连接 安装docker步骤网上有很多,在这里还是
-
docker+Nginx部署前端项目的详细过程记录
目录 相关配置安装 创建配置文件 项目打包与部署 一个相关报错: 总结 相关配置安装 安装Docker yum install docker 启动服务 start docker systemctl start docker Docker中拉取nginx镜像 docker pull nginx 创建配置文件 我们需要在根目录下创建Dockerfile文件和default.conf文件. 其中default.conf文件的名称是什么无所谓,只要在配置文件中注意使用相同名称即可. Dokcerfile
-
docker 搭建部署 YAPI 框架的详细过程
目录 Yapi介绍 优点: Yapi的几个功能 1.启动 MongoDB 2.获取 Yapi 镜像,版本信息可在 阿里云镜像仓库 查看 3.初始化 Yapi 数据库索引及管理员账号 4.启动 Yapi 服务 5.Yapi 部署成功 Yapi介绍 Yapi是一个高效.易用.功能强大的接口文档管理工具,旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建.发布.维护 API.Yapi旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建.发布.维护 API.
-
CentOS 7安装Docker服务详细过程
Docker 简介 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何接口. Docker 官网:http://www.docker.com/ Docker 官方文档:https://docs.docker.com/ Docker Github 地址:https://github.com/docker/docker Docker 仓库:https:
-
10分钟在服务器部署好Jenkins的详细过程
目录 Linux安装Jenkins 1.下载安装 2.修改端口配置 3.启动 4.解决首页加载过慢问题 5.安装插件 6.设置管理员用户 7.一切准备就绪 8.新建任务,下回再续 总结 Linux安装Jenkins 哈喽,大家好,我是一条. 这是 DevOps 相关的第一篇文章,准确是第二篇,之前有一篇<Docker从入门到干事>. 本文主要是 Jenkins 的安装部署,那前提我们应该装好 Git Maven JDK.这些准备工作就简单过一下. Git Maven 非必需 Git 安装很简单
-
IDEA 2020.2 部署JSF项目的详细过程
目录 1.下载glassfish 2.配置glassfish环境变量 3.修改jdk环境变量 4.测试glassfish是否可以正常启动 5.在IDEA中创建一个JSF项目 6.问题:部分标签元素无法显示 1.下载glassfish idea2021最新激活方法 去官网下载glassfish4.1.1(最后发现glassfish5也行) 官网地址:GlassFish https://javaee.github.io/glassfish/ 点击download 选择图中版本 下载完解压到自己指定的