如何基于pandas读取csv后合并两个股票
最近在研究螺纹钢与铁矿石的比价变化,所以用python写个代码分析一下。
数据文件:
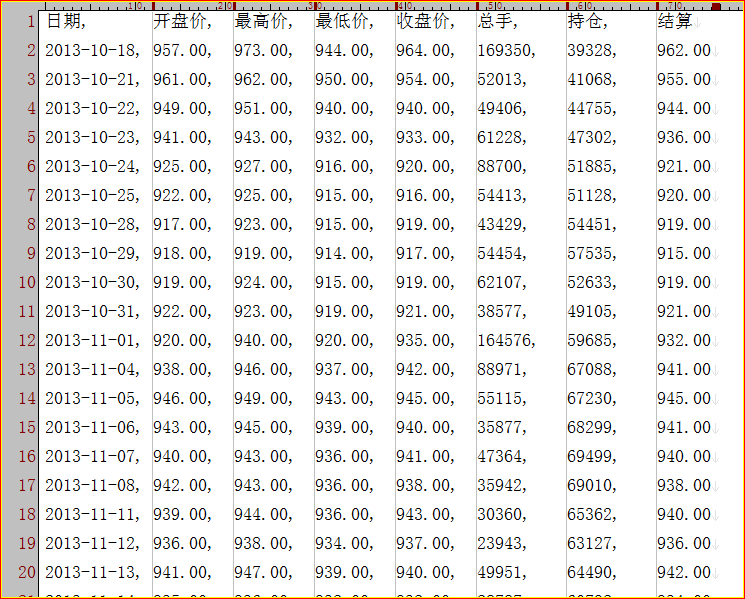

数据下载自网络。
代码:
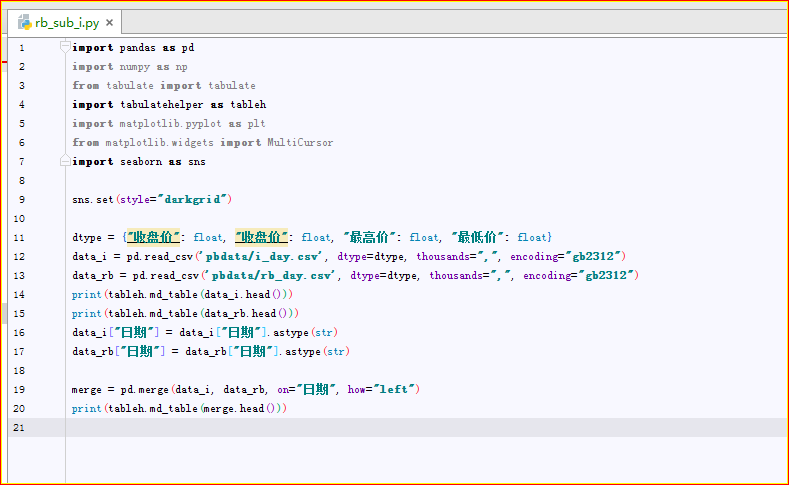
中间有些没用的,看官们请忽略,那是我从另一个文件直接复制来的,后面要plt出图的。
今天的文章只讲两个DataFrame如何连接到一起,相当于SQL的left-join ,或者update A left join B ON key1=key2。
控制台输出:
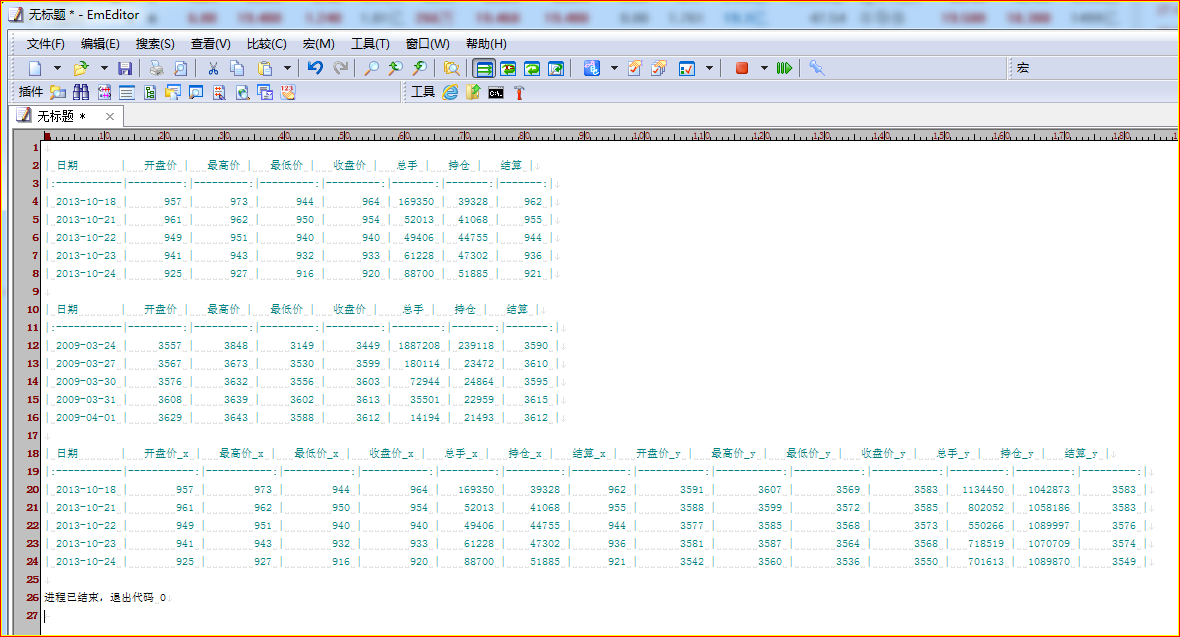
好了, 数据已经按日期关联到一起,后面就简单了,准备用matplotlib画3条拆线,观察历史相关性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
pandas读取CSV文件时查看修改各列的数据类型格式
下面给大家介绍下pandas读取CSV文件时查看修改各列的数据类型格式,具体内容如下所述: 我们在调bug的时候会经常查看.修改pandas列数据的数据类型,今天就总结一下: 1.查看: Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64 2.修改 import pandas as pd import numpy a
-
pandas读取csv文件,分隔符参数sep的实例
在python中读取csv文件时,一般操作如下: import pandas as pd pd.read_csv(filename) 该读文件方式,默认是以逗号","作为分割符,若是以其它分隔符,比如制表符"/t",则需要显示的指定分隔符.如下 pd_read_csv(filename,'/t') 但如果遇见某个字段包含了"/t"的字符,比如网址"www.xxx.xx/t-",则也会把字段中的"/t"理解为
-
python pandas读取csv后,获取列标签的方法
在Python中,经常会去读csv文件,如下 import pandas as pd import numpy as np df = pd.read_csv("path.csv") data = np.array(df.loc[:,:]) 通过这种方式得到的data,不包含第一行,一般来说,第一行即是列标签.那么如何获取第一行的内容呢.如下 column_headers = list(df.columns.values) 以上这篇python pandas读取csv后,获取列标签的方法
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
Pandas之read_csv()读取文件跳过报错行的解决
读取文件时遇到和列数不对应的行,此时会报错.若报错行可以忽略,则添加以下参数: 样式: pandas.read_csv(***,error_bad_lines=False) pandas.read_csv(filePath) 方法来读取csv文件时,可能会出现这种错误: ParserError:Error tokenizing data.C error:Expected 2 fields in line 407,saw 3. 是指在csv文件的第407行数据,期待2个字段,但在第407行实际发现
-
解决pandas使用read_csv()读取文件遇到的问题
如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.01 2.35 武钢股份 (sh600005) 75.85 1.3 浦发银行 (sh600000) 6.65 0.96 在使用read_csv() API读取CSV文件时求取某一列数据比较大小时, df=pd.read_csv(output_file,encoding='gb23
-

如何基于pandas读取csv后合并两个股票
最近在研究螺纹钢与铁矿石的比价变化,所以用python写个代码分析一下. 数据文件: 数据下载自网络. 代码: 中间有些没用的,看官们请忽略,那是我从另一个文件直接复制来的,后面要plt出图的. 今天的文章只讲两个DataFrame如何连接到一起,相当于SQL的left-join ,或者update A left join B ON key1=key2. 控制台输出: 好了, 数据已经按日期关联到一起,后面就简单了,准备用matplotlib画3条拆线,观察历史相关性. 以上就是本文的全部内容,
-
基于Pandas读取csv文件Error的总结
OSError:报错1 <span style="font-size:14px;">pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas\_libs\parsers.c:4209)() pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas\_libs\
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
Python Pandas读取csv/tsv文件(read_csv,read_table)的区别
目录 前言 read_csv()和read_table()之间的区别 读取没有标题的CSV 读取有标题的CSV 读取有index的CSV 指定(选择)要读取的列 跳过(排除)行的读取 skiprows skipfooter nrows 通过指定类型dtype进行读取 NaN缺失值的处理 读取使用zip等压缩的文件 tsv的读取 总结 前言 要将csv和tsv文件读取为pandas.DataFrame格式,可以使用Pandas的函数read_csv()或read_table(). 在此 read_
-
pandas读取csv格式数据时header参数设置方法
目录 写在前面 参考文档 read_csv的header参数 header参数测试 思考 写在前面 使用pandas中read_csv读取csv数据时,对于有表头的数据,将header设置为空(None),会报错:pandas_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error() ParserError: Error tokenizing data. C error: Expected 4 fields in line 2,