以示例讲解Clickhouse Docker集群部署以及配置
目录
- 写在前面
- 环境部署
- Zookeeper集群部署
- Clickhouse集群部署
- 1.临时镜像拷贝出配置
- 2.修改config.xml配置
- 3.拷贝到其他文件夹
- 4.分发到其他服务器
- 配置集群
- 1.修改配置
- 2.新增集群配置文件metrika.xml
- 集群运行及测试
写在前面
抽空来更新一下大数据的玩意儿了,起初架构选型的时候有考虑Hadoop那一套做数仓,但是Hadoop要求的服务器数量有点高,集群至少6台或以上,所以选择了Clickhouse(后面简称CH)。CH做集群的话,3台服务器起步就可以的,当然,不是硬性,取决于你的zookeeper做不做集群,其次CH性能更强大,对于量不是非常巨大的场景来说,单机已经足够应对OLAP多种场景了。
进入正题,相关环境:
| IP | 服务器名 | 操作系统 | 服务 | 备注 |
| 172.192.13.10 | server01 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例1端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片1 CH实例2端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server02的副本 |
| 172.192.13.11 | server02 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例3端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片2 CH实例4端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server03的副本 |
| 172.192.13.12 | server03 | Ubuntu20.04 | 两个Clickhouse实例、Zookeeper |
CH实例5端口:tcp 9000, http 8123, 同步端口9009,MySQL 9004, 类型: 主分片3 CH实例6端口:tcp 9000, http 8124, 同步端口9010,MySQL 9005, 类型: server01的副本 |
在每一台服务上都安装docker,docker里面分别安装有3个服务:ch-main,ch-sub,zookeeper_node,如图所示:

细心的已经看到,PORTS没有映射关系,这里是使用Docker host网络模式,模式简单并且性能高,避免了很多容器间或跨服务器的通信问题,这个踩了很久。
环境部署
1. 服务器环境配置
在每一台服务器上执行:vim /etc/hosts,打开hosts之后新增配置:
172.192.13.10 server01 172.192.13.11 server02 172.192.13.12 server03
2.安装docker
太简单,略...
3.拉取clickhouse、zookeeper镜像
太简单,略...
Zookeeper集群部署
在每个服务器上你想存放的位置,新建一个文件夹来存放zk的配置信息,这里是/usr/soft/zookeeper/,在每个服务器上依次运行以下启动命令:
server01执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \ -v /usr/soft/zookeeper/data:/data \ -v /usr/soft/zookeeper/datalog:/datalog \ -v /usr/soft/zookeeper/logs:/logs \ -v /usr/soft/zookeeper/conf:/conf \ --network host \ -e ZOO_MY_ID=1 zookeeper
server02执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \ -v /usr/soft/zookeeper/data:/data \ -v /usr/soft/zookeeper/datalog:/datalog \ -v /usr/soft/zookeeper/logs:/logs \ -v /usr/soft/zookeeper/conf:/conf \ --network host \ -e ZOO_MY_ID=2 zookeeper
server03执行:
docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper_node --restart always \ -v /usr/soft/zookeeper/data:/data \ -v /usr/soft/zookeeper/datalog:/datalog \ -v /usr/soft/zookeeper/logs:/logs \ -v /usr/soft/zookeeper/conf:/conf \ --network host \ -e ZOO_MY_ID=3 zookeeper
唯一的差别是:-e ZOO_MY_ID=*而已。
其次,每台服务上打开/usr/soft/zookeeper/conf路径,找到zoo.cfg配置文件,修改为:
dataDir=/data dataLogDir=/datalog tickTime=2000 initLimit=5 syncLimit=2 clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=0 maxClientCnxns=60 server.1=172.192.13.10:2888:3888 server.2=172.192.13.11:2888:3888 server.3=172.192.13.12:2888:3888
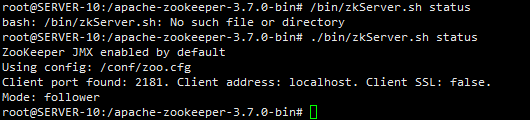
然后进入其中一台服务器,进入zk查看是否配置启动成功:
docker exec -it zookeeper_node /bin/bash ./bin/zkServer.sh status
Clickhouse集群部署
1.临时镜像拷贝出配置
运行一个临时容器,目的是为了将配置、数据、日志等信息存储到宿主机上:
docker run --rm -d --name=temp-ch yandex/clickhouse-server
拷贝容器内的文件:
docker cp temp-ch:/etc/clickhouse-server/ /etc/ //https://www.cnblogs.com/EminemJK/p/15138536.html
2.修改config.xml配置
//同时兼容IPV6,一劳永逸 <listen_host>0.0.0.0</listen_host> //设置时区 <timezone>Asia/Shanghai</timezone> //删除原节点<remote_servers>的测试信息 <remote_servers incl="clickhouse_remote_servers" /> //新增,和上面的remote_servers 节点同级 <include_from>/etc/clickhouse-server/metrika.xml</include_from> //新增,和上面的remote_servers 节点同级 <zookeeper incl="zookeeper-servers" optional="true" /> //新增,和上面的remote_servers 节点同级 <macros incl="macros" optional="true" />
其他listen_host仅保留一项即可,其他listen_host则注释掉。
3.拷贝到其他文件夹
cp -rf /etc/clickhouse-server/ /usr/soft/clickhouse-server/main cp -rf /etc/clickhouse-server/ /usr/soft/clickhouse-server/sub
main为主分片,sub为副本。
4.分发到其他服务器
#拷贝配置到server02上 scp /usr/soft/clickhouse-server/main/ server02:/usr/soft/clickhouse-server/main/ scp /usr/soft/clickhouse-server/sub/ server02:/usr/soft/clickhouse-server/sub/ #拷贝配置到server03上 scp /usr/soft/clickhouse-server/main/ server03:/usr/soft/clickhouse-server/main/ scp /usr/soft/clickhouse-server/sub/ server03:/usr/soft/clickhouse-server/sub/
SCP真香。
然后就可以删除掉临时容器:docker rm -f temp-ch
配置集群

这里三台服务器,每台服务器起2个CH实例,环状相互备份,达到高可用的目的,资源充裕的情况下,可以将副本Sub实例完全独立出来,修改配置即可,这个又是Clickhouse的好处之一,横向扩展非常方便。
1.修改配置
进入server1服务器,/usr/soft/clickhouse-server/sub/conf修改config.xml文件,主要修改内容:
原: <http_port>8123</http_port> <tcp_port>9000</tcp_port> <mysql_port>9004</mysql_port> <interserver_http_port>9009</interserver_http_port> 修改为: <http_port>8124</http_port> <tcp_port>9001</tcp_port> <mysql_port>9005</mysql_port> <interserver_http_port>9010</interserver_http_port>
修改的目的目的是为了和主分片main的配置区分开来,端口不能同时应用于两个程序。server02和server03如此修改或scp命令进行分发。
2.新增集群配置文件metrika.xml
server01,main主分片配置:
进入/usr/soft/clickhouse-server/main/conf文件夹内,新增metrika.xml文件(文件编码:utf-8)。
<yandex>
<!-- CH集群配置,所有服务器都一样 -->
<clickhouse_remote_servers>
<cluster_3s_1r>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server01</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server03</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server02</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server01</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server03</host>
<port>9000</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>server02</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
</shard>
</cluster_3s_1r>
</clickhouse_remote_servers>
<!-- zookeeper_servers所有实例配置都一样 -->
<zookeeper-servers>
<node index="1">
<host>172.16.13.10</host>
<port>2181</port>
</node>
<node index="2">
<host>172.16.13.11</host>
<port>2181</port>
</node>
<node index="3">
<host>172.16.13.12</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- marcos每个实例配置不一样 -->
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
<macros>节点每个服务器每个实例不同,其他节点配置一样即可,下面仅列举<macros>节点差异的配置。
server01,sub副本配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>
server02,main主分片配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>
server02,sub副本配置:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-2</replica>
</macros>
server03,main主分片配置:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-1</replica>
</macros>
server03,sub副本配置:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-01-2</replica>
</macros>
至此,已经完成全部配置,其他的比如密码等配置,可以按需增加。
集群运行及测试
在每一台服务器上依次运行实例,zookeeper前面已经提前运行,没有则需先运行zk集群。
运行main实例:
docker run -d --name=ch-main -p 8123:8123 -p 9000:9000 -p 9009:9009 --ulimit nofile=262144:262144 \-v /usr/soft/clickhouse-server/main/data:/var/lib/clickhouse:rw \-v /usr/soft/clickhouse-server/main/conf:/etc/clickhouse-server:rw \-v /usr/soft/clickhouse-server/main/log:/var/log/clickhouse-server:rw \ --add-host server01:172.192.13.10 \ --add-host server02:172.192.13.11 \ --add-host server03:172.192.13.12 \ --hostname server01 \ --network host \ --restart=always \ yandex/clickhouse-server
运行sub实例:
docker run -d --name=ch-sub -p 8124:8124 -p 9001:9001 -p 9010:9010 --ulimit nofile=262144:262144 \ -v /usr/soft/clickhouse-server/sub/data:/var/lib/clickhouse:rw \ -v /usr/soft/clickhouse-server/sub/conf:/etc/clickhouse-server:rw \ -v /usr/soft/clickhouse-server/sub/log:/var/log/clickhouse-server:rw \ --add-host server01:172.192.13.10 \ --add-host server02:172.192.13.11 \ --add-host server03:172.192.13.12 \ --hostname server01 \ --network host \ --restart=always \ yandex/clickhouse-server
在每台服务器执行命令,唯一不同的参数是hostname,因为我们前面已经设置了hostname来指定服务器,否则在执行select * from system.clusters查询集群的时候,将is_local列全为0,则表示找不到本地服务,这是需要注意的地方。在每台服务器的实例都启动之后,这里使用正版DataGrip来打开:

在任一实例上新建一个查询:
create table T_UserTest on cluster cluster_3s_1r
(
ts DateTime,
uid String,
biz String
)
engine = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/T_UserTest', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts
SETTINGS index_granularity = 8192;
cluster_3s_1r是前面配置的集群名称,需一一对应上,/clickhouse/tables/是固定的前缀,相关语法可以查看官方文档了。

刷新每个实例,即可看到全部实例中都有这张T_UserTest表,因为已经搭建zookeeper,很容易实现分布式DDL。
继续新建Distributed分布式表:
CREATE TABLE T_UserTest_All ON CLUSTER cluster_3s_1r AS T_UserTest ENGINE = Distributed(cluster_3s_1r, default, T_UserTest, rand())
每个主分片分别插入相关信息:
--server01insert into T_UserTest values ('2021-08-16 17:00:00',1,1)
--server02
insert into T_UserTest values ('2021-08-16 17:00:00',2,1)
--server03
insert into T_UserTest values ('2021-08-16 17:00:00',3,1)
然后查询分布式表select * from T_UserTest_All,
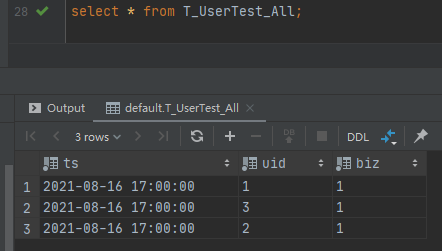
查询对应的副本表或者关闭其中一台服务器的docker实例,查询也是不受影响,时间关系不在测试。
到此这篇关于Clickhouse Docker集群配置及部署的文章就介绍到这了,更多相关Clickhouse Docker集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Docker下安装zookeeper(单机和集群)
启动Docker后,先看一下我们有哪些选择. 有官方的当然选择官方啦~ 下载: [root@localhost admin]# docker pull zookeeper Using default tag: latest Trying to pull repository docker.io/library/zookeeper ... latest: Pulling from docker.io/library/zookeeper 1ab2bdfe9778: Already exists 7a
-
Docker搭建Zookeeper&Kafka集群的实现
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用的笔记本,所以每次连接网络IP都会改变,还要总是修改配置文件的,过于繁琐,不方便测试.(通过Docker虚拟网络的方式可以避免此问题,当时实验的时候没有了解到) Docker 安装 如果已经安装Docker请忽略此步骤 Docker支持以下的CentOS版本: CentOS 7 (64
-

Docker安装ClickHouse并初始化数据测试
clickhouse简介 ClickHouse是一个面向列存储的数据库管理系统,可以使用SQL查询实时生成分析数据报告,主要用于OLAP(在线分析处理查询)场景.关于clickhouse原理以及基础知识在以后学习中慢慢总结. 1.Docker安装ClickHouse docker run -d --name some-clickhouse-server \ -p 8123:8123 -p 9009:9009 -p 9091:9000 \ --ulimit nofile=262144:262144
-
以示例讲解Clickhouse Docker集群部署以及配置
目录 写在前面 环境部署 Zookeeper集群部署 Clickhouse集群部署 1.临时镜像拷贝出配置 2.修改config.xml配置 3.拷贝到其他文件夹 4.分发到其他服务器 配置集群 1.修改配置 2.新增集群配置文件metrika.xml 集群运行及测试 写在前面 抽空来更新一下大数据的玩意儿了,起初架构选型的时候有考虑Hadoop那一套做数仓,但是Hadoop要求的服务器数量有点高,集群至少6台或以上,所以选择了Clickhouse(后面简称CH).CH做集群的话,3台服务器起步
-
Docker构建ELK Docker集群日志收集系统
当我们搭建好Docker集群后就要解决如何收集日志的问题 ELK就提供了一套完整的解决方案 本文主要介绍使用Docker搭建ELK 收集Docker集群的日志 ELK简介 ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成 Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等. Logstash是一个完全开源的工具,他可以对你的日志进行收集.过滤,并将
-
Docker集群的创建与管理实例详解
本文详细讲述了Docker集群的创建与管理.分享给大家供大家参考,具体如下: 在<Docker简单安装与应用入门教程>中编写一个应用程序,并将其转化为服务,在<Docker分布式应用教程>中,使应用程序在生产过程中扩展5倍,并定义应该如何运行.现在将此应用程序部署到集群上,并在多台机器上运行它,通过将多台机器连接到Dockerized集群上,使多容器.多机器应用成为可能. Swarm(集群)是运行Docker并加入到一个集群中的一组机器,在这种情况下,您将继续运行以往的Docker
-
MySQL之高可用集群部署及故障切换实现
一.MHA 1.概念 2.MHA 的组成 3.MHA 的特点 二.搭建MySQL+MHA 思路和准备工作 1.MHA架构 数据库安装 一主两从 MHA搭建 2.故障模拟 模拟主库失效 备选主库成为主库 原故障主库恢复重新加入到MHA成为从库 3.准备4台安装MySQL虚拟机 MHA高可用集群相关软件包 MHAmanager IP:192.168.221.30 MySQL1 IP:192.168.221.20 MySQL2 IP:192.168.221.100 MySQL3 IP: 192.168
-
Redis中常见的几种集群部署方案
目录 前言 几种常用的集群方案 主从集群模式 全量同步 增量同步 举个栗子 哨兵机制 什么是哨兵机制 如何保证选主的准确性 如何选主 选举主节点的规则 哨兵进行主节点切换 切片集群 RedisCluster方案 哈希槽重新分配 避免HotKey 如何发现HotKey HotKey如何解决 避免BigKey BigKey存在问题 如何发现BigKey BigKey如何避免 BigKey如何删除 参考 前言 这里来了解一下,Redis 中常见的集群方案 几种常用的集群方案 主从集群模式 哨兵机制 切
-
docker compose 一键部署分布式配置中心Apollo的过程详解
简介 说起分布式肯定要想到分布式配置中心.分布式日志.分布式链路追踪等 在分布式部署中业务往往有很多配置比如: 应用程序在启动和运行时需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,比如:数据库连接参数.启动参数等,都需要去维护和配置,但不可能一台台服务器登录上去配置 今天我要跟大家分享一下分布式配置中心Apollo: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等
-
redis sentinel监控高可用集群实现的配置步骤
目录 一.端口转发. 如果在一个主机里面,安装了两个redis实例,可以在项目里面配置IP端口,用iptables转发. iptables -t nat -A PREROUTING -p tcp --dport 6379 -j REDIRECT --to-ports 7379 当发生切换的时候,触发了脚本,执行语句.端口可以马上转发带正确的redis上面.参数的含义: 脚本配置: 脚本实例: #!/bin/bash iptables -t nat -I PREROUTING -p tcp --d
-
redis sentinel监控高可用集群实现的配置步骤
目录 一.端口转发 二.修改HOST文件 三.用第三方代理haproxy 四.插曲 一.端口转发 如果在一个主机里面,安装了两个redis实例,可以在项目里面配置IP端口,用iptables转发. iptables -t nat -A PREROUTING -p tcp --dport 6379 -j REDIRECT --to-ports 7379 当发生切换的时候,触发了脚本,执行语句.端口可以马上转发带正确的redis上面.参数的含义: 脚本配置: 脚本实例: #!/bin/bash i
-
详解Nginx + Tomcat 反向代理 负载均衡 集群 部署指南
Nginx是一种服务器软件,也是一种高性能的http和反向代理服务器,同时还是一个代理邮件服务器.也就是说,我们在Nginx上可以发布网站,可以实现负载均衡(提高应答效率,避免服务器崩溃),还可以作为邮件服务器实现收发邮件等功能.而最常见的就是使用Nginx实现负载均衡. Nginx与其他服务器的性能比较: Tomcat服务器面向Java语言,是重量级的服务器,而Nginx是轻量级的服务器.Apache服务器稳定.开源.跨平台,但是Apache服务器不支持高并发,Nginx能支持处理百万级的TC
-
具有负载均衡功能的MySQL服务器集群部署及实现
在实际生产环境中,部署和实现具有一定负载均衡功能的 MySQL服务器集群,对于提高用户数据库应用系统的性能.速度和稳定性具有明显的作用.本文简要介绍了在 FreeBSD 7.0-Release系统上部署实现MySQL服务器集群的方案,并对可能出现的问题提供了相应的解决方法.1. 引言MySQL是一个高速度.高性能.多线程.开放源代码,建立在客户/服务器(Client /Server)结构上的关系型数据库管理系统(RDBMS).它始于1979年,最初是Michael Widenius为瑞典TcX公