pandas将list数据拆分成行或列的实现
数据
import numpy as np
import pandas as pd
data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
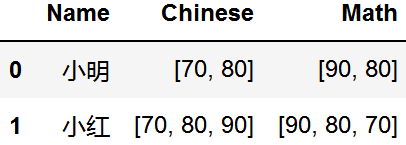
data
拆分成行

def split_row(data, column):
'''拆分成行
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
row_len = list(map(len, data[column].values))
rows = []
for i in data.columns:
if i == column:
row = np.concatenate(data[i].values)
else:
row = np.repeat(data[i].values, row_len)
rows.append(row)
return pd.DataFrame(np.dstack(tuple(rows))[0], columns=data.columns)
split_row(data, column='Chinese')
拆分成列

from copy import deepcopy
def split_col(data, column):
'''拆分成列
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
data = deepcopy(data)
max_len = max(list(map(len, data[column].values))) # 最大长度
new_col = data[column].apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[column + str(i)] = j
return data
split_col(data, column='Chinese')
其他情况
1. 批量处理+不要原列

def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(len, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data
2. 带int和list数据
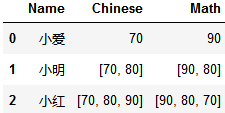
转成这样:
import numpy as np
import pandas as pd
data = [{'Name': '小爱', 'Chinese': 70, 'Math': 90},
{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(lambda x:len(x) if isinstance(x, list) else 1, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x+[None]*(max_len - len(x)) if isinstance(x, list) else [x]+[None]*(max_len - 1)) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
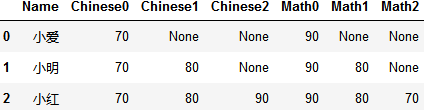
split_col(data, columns=['Chinese','Math'])
data
参考文献
Python Pandas list(列表)数据列拆分成多行的方法
到此这篇关于pandas将list数据拆分成行或列的实现的文章就介绍到这了,更多相关pandas list数据拆分内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas DataFrame数据转为list的方法
首先使用np.array()函数把DataFrame转化为np.ndarray(),再利用tolist()函数把np.ndarray()转为list,示例代码如下: # -*- coding:utf-8-*- import numpy as np import pandas as pd data_x = pd.read_csv("E:/Tianchi/result/features.csv",usecols=[2,3,4])#pd.dataframe data_y = pd.read_
-
Pandas将列表(List)转换为数据框(Dataframe)
Python中将列表转换成为数据框有两种情况:第一种是两个不同列表转换成一个数据框,第二种是一个包含不同子列表的列表转换成为数据框. 第一种:两个不同列表转换成为数据框 from pandas.core.frame import DataFrame a=[1,2,3,4]#列表a b=[5,6,7,8]#列表b c={"a" : a, "b" : b}#将列表a,b转换成字典 data=DataFrame(c)#将字典转换成为数据框 print(data) 输出的结
-
Pandas把dataframe或series转换成list的方法
把dataframe转换为list 输入多维dataframe: df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9], 'b':[3,5,6,2,4,6,7,8,7,8,9]}) 把a列的元素转换成list: # 方法1df['a'].values.tolist() # 方法2df['a'].tolist() 把a列中不重复的元素转换成list: df['a'].drop_duplicates().values.tolist() 输入一维datafram
-
pandas 将list切分后存入DataFrame中的实例
如下所示: #-*- coding:utf-8 -*- import random import pandas as pd import numpy as np list=[1,2,3,4,5,6,7,8,9,0,11,0,13,14,15,16,17,18,19,20] #把list切分后存入矩阵中 matrix=[] for j in range(0,len(list),5): matrix.append(list[j:j+5]) matrix=np.array(matrix)#转np.ar
-

pandas将list数据拆分成行或列的实现
数据 import numpy as np import pandas as pd data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]}, {'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}] data = pd.DataFrame(data) data 拆分成行 def split_row(data, column): '''拆分成行 :param da
-
Python Pandas list列表数据列拆分成多行的方法实现
1.实现的效果 示例代码: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[458]: A B 0 1 [1, 2] 1 2 [1, 2] 拆分成多行的效果: A B 0 1 1 1 1 2 3 2 1 4 2 2 2.拆分成多行的方法 1)通过apply和pd.Series实现 容易理解,但在性能方面不推荐. df.set_index('A').B.apply(pd.Series).stack().reset_ind
-
Pandas实现一列数据分隔为两列
分割成一个包含两个元素列表的列 对于一个已知分隔符的简单分割(例如,用破折号分割或用空格分割).str.split() 方法就足够了 . 它在字符串的列(系列)上运行,并返回列表(系列). >>> import pandas as pd >>> df = pd.DataFrame({'AB': ['A1-B1', 'A2-B2']}) >>> df AB 0 A1-B1 1 A2-B2 >>> df['AB_split'] = df[
-
pandas数据框,统计某列数据对应的个数方法
现在要解决的问题如下: 我们有一个数据的表 第7列有许多数字,并且是用逗号分隔的,数字又有一个对应的关系: 我们要得到第7列对应关系的统计,就是每一行的第7列a有多少个,b有多少个 好了,我给的解决方法如下: #!/bin/python #-*-coding:UTF-8-*- import pandas as pd import numpy as np dfidspec = pd.read_table("one.txt")#这个是对应关系的文件 dfmgs = pd.read_tabl
-
pandas将DataFrame的几列数据合并成为一列
目录 1.1 方法归纳 1.2 .str.cat函数详解 1.2.1 语法格式: 1.2.2 参数说明: 1.2.3 核心功能: 1.2.4 常见范例: 1.1 方法归纳 使用 + 直接将多列合并为一列(合并列较少): 使用pandas.Series.str.cat方法,将多列合并为一列(合并列较多): 范例如下: dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone&q
-
Python实战基础之Pandas统计某个数据列的空值个数
目录 一.实战场景 二.主要知识点 三.菜鸟实战 1.创建 python 文件 2.运行结果 补充:Pandas检查是否有空值.处理空值 总结 一.实战场景 实战场景:Pandas 如何统计某个数据列的空值个数 二.主要知识点 文件读写 基础语法 Pandas numpy 三.菜鸟实战 马上安排! 1.创建 python 文件 """ 对如下DF,设置两个单元格的值 ·使用iloc 设置(3,B)的值是nan ·使用loc设置(8,D)的值是nan ""&
-
Pandas数据分析之批量拆分/合并Excel
目录 前言 一.假造数据 二.程序演示 1.将一个大Excel等份拆成多个Excel 2.合并多个小Excel到一个大Excel 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中数据的合并(concat和append) 将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源 一.假造数据 work_dir="./datas" splits_dir=f"{work_dir}/
-
Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
pandas把dataframe转成Series,改变列中值的类型方法
使用 pd.Series把dataframe转成Series ts = pd.Series(df['Value'].values, index=df['Date']) 使用astype改变列中的值的类型,注意前面要有np df['列名'] = df['列名'].astype(np.int64) 以上这篇pandas把dataframe转成Series,改变列中值的类型方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: python panda
-
对pandas处理json数据的方法详解
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe. 先拿出我要处理的json字符串: strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529