详解Python排序算法的实现(冒泡,选择,插入,快速)
目录
- 1. 前言
- 2. 冒泡排序算法
- 2.1 摆擂台法
- 2.2 相邻两个数字相比较
- 3. 选择排序算法
- 4. 插入排序
- 5. 快速排序
- 6. 总结
1. 前言
所谓排序,就是把一个数据群体按个体数据的特征按从大到小或从小到大的顺序存放。
排序在应用开发中很常见,如对商品按价格、人气、购买数量……显示。
初学编程者,刚开始接触的第一个稍微有点难理解的算法应该是排序算法中的冒泡算法。
我初学时,“脑思维”差点绕在 2 个循环结构的世界里出不来了。当时,老师要求我们死记冒泡的口诀,虽然有点搞笑,但是当时的知识层次只有那么点,口诀也许是最好的一种学习方式。
当知识体系慢慢建全,对于冒泡排序的理解,自然也会从形式到本质的理解。
本文先从冒泡排序的本质说起,不仅是形式上理解,而是要做到本质里的理解。
2. 冒泡排序算法
所谓冒泡排序算法,本质就是求最大值、最小值算法。
所以,可以暂时抛开冒泡排序,先从最大值算法聊起。
为了更好理解算法本质,在编写算法时不建议直接使用 Python 中已经内置的函数。如 max()、min()……
求最大值,有多种思路,其中最常用的思路有:
- 摆擂台法
- 相邻的两个数字比较法
如一个数列 nums=[3,1,8,9,12,32,7]
2.1 摆擂台法
算法思想:
找一个擂台,从数列中随机拎一个数字出来,站在擂台上充当老大。
老大不是说你想当就能当,要看其它的兄弟服不服。于是,其它的数字兄弟会一一登上擂台和擂台上的数字比较,原则是大的留下,小的离开。
如果是找最大值,则是大的留下,小的离开。
反之,如果是找最小值,则是小的留下,大的离开。
你方唱罢我登场。最后留在擂台上的就是真老大了。

nums = [3, 1, 8, 9, 12, 32, 7]
# 第一个数字登上擂台
m = nums[0]
# 其它数字不服气
for i in range(1, len(nums)):
# PK 过程中,大的留在擂台上
if nums[i] > m:
m = nums[i]
# 最后留在擂台上的就是最大值
print("最大值是:", m)
很简单,对不对,如果,找到一个最大值后,再在余下的数字中又找最大值,以此类推,结局会怎样?
最后可以让所有数字都排好序!这就是排序的最本质道理,找着找着就排好序了。
在上面的代码上稍做改动一下,每次找到最大值后存入到另一个列表中。
nums = [3, 1, 8, 9, 12, 32, 7]
# 第一个数字登上擂台
ms=[]
for _ in range(len(nums)):
m = nums[0]
for i in range(1, len(nums)):
if nums[i] > m:
m = nums[i]
# 依次找到的最大值存入新数列
ms.append(m)
# 从原数列中移出找到的最大值,下一轮要在没有它的数列中重新找,不移走,无论找多少次,还会是它
nums.remove(m)
print(ms)
'''
输出结果
[32, 12, 9, 8, 7, 3, 1]
'''
我们可以看到原数列中的数字全部都排序了。但是上述排序算法不完美:
- 另开辟了新空间,显然空间复杂度增加了。
- 原数列的最大值找到后就删除了,目的是不干扰余下数字继续查找最大值。当对所有数字排好序后,原数列也破坏了。
能不能不开辟新空间,在原数列里就完成排序?当然可以。
可以找到最大值就向后移!原数列从逻辑上从右向左缩小。
nums = [3, 1, 8, 9, 12, 32, 7]
# 第一个数字登上擂台
nums_len = len(nums)
for _ in range(len(nums)):
m = nums[0]
for i in range(1, nums_len):
if nums[i] > m:
m = nums[i]
# 最大值找到,移动最后
nums.remove(m)
nums.append(m)
# 这个很关键,缩小原数列的结束位置
nums_len = nums_len - 1
print(nums)
'''
输出结果:
[32, 12, 9, 8, 7, 3, 1]
'''
在原数列上面,上述代码同样完成了排序。
归根结底,上述排序的思路就是不停地找最大值呀、找最大值……找到最后一个数字,大家自然而然就排好序了。
所以算法结构中内层循环是核心找最大值逻辑,而外层就是控制找呀找呀找多少次。
上述排序算法我们也可称是冒泡排序算法,其时间复杂度=外层循环次数X内层循环次数。如有 n 个数字 ,则外层循环 n-1 次,内层循环 n-1 次,在大O表示法中,常量可以忽视不计,时间复杂度应该是 O(n2)。
2.2 相邻两个数字相比较
如果有 7 个数字,要找到里面的最大值,有一种方案就是每相邻的两个数字之行比较,如果前面的比后面的数字大,则交换位置,否则位置不动。
上体育课的时候,老师排队用的就是这种方式,高的和矮的交换位置,一直到不能交换为此。
nums = [3, 1, 8, 9, 12, 32, 7]
for i in range(len(nums)-1):
# 相邻 2 个数字比较
if nums[i] > nums[i + 1]:
# 如果前面的数字大于后面的数字,则交换
nums[i], nums[i + 1] = nums[i + 1], nums[i]
# 显然,数列最后位置的数字是最大的
print(nums[len(nums) - 1])
'''
输出结果
32
'''
上述代码同样实现了找最大值。
和前面的思路一样,如果找了第一个最大值后,又继续在剩下的数字中找最大值,不停地找呀找,会发现最后所有数字都排好序了。
在上述找最大值的逻辑基础之上,再在外面嵌套一个重复语法,让找最大值逻辑找完一轮又一轮,外层重复只要不少于数列中数字长度,就能完成排序工作,即使外层重复大于数列中数字长度,只是多做了些无用功而已。
nums = [3, 1, 8, 9, 12, 32, 7]
# 外层重复的 100 意味着找了 100 次最大值,这里只是说明问题,就是不停找最大值,显然,是用不着找100 次的
for j in range(100):
for i in range(len(nums)-1):
# 相邻 2 个数字比较
if nums[i] > nums[i + 1]:
# 如果前面的数字大于后面的数字,则交换
nums[i], nums[i + 1] = nums[i + 1], nums[i]
print(nums)
上面的代码就是冒泡排序算法实现。其实冒泡排序就是找了一轮最大值,又继续找最大值的思路。可以对上述算法进行一些优化,如已经找到的最大值没有必要再参与后继的找最大值中去。
显然,找最大值的最多轮数是数列长度减 1 就可以了。5 个数字,前面 4 个找到了,自然大家就都排好序了。
nums = [3, 1, 8, 9, 12, 32, 7]
# 找多少次最大值,数列长度减 1
for j in range(len(nums)-1):
for i in range(len(nums)-1-j):
# 相邻 2 个数字比较
if nums[i] > nums[i + 1]:
# 如果前面的数字大于后面的数字,则交换
nums[i], nums[i + 1] = nums[i + 1], nums[i]
print(nums)
在学习冒泡排序算法时,不要被外层、内层循环结构吓住,核心是理解求最大值算法。上述冒泡排序算法的时间复杂度也是 O(n2)。
3. 选择排序算法
选择排序算法是冒泡排序的变种,还是在找最大(小)值算法,冒泡排序是一路比较一路交换,为什么要这样,因为不知道数列中哪一个数字是最大(小)值,所以只能不停的比较不停的交换。
选择排序有一个优于冒泡的理念,需要交换时才交换。
所以选择排序算法的问题就是什么时候需要交换?
选择排序先是假设第一个数字是最小值,然后在后面的数字里找有没有比这个假设更小的。不是说,找一个小的就交换,因为有可能还有比之更小的,只有当后续所有数字找完后,再确定进行交换,
还是使用擂擂台算法实现找最大(小)值,找到后交换位置。
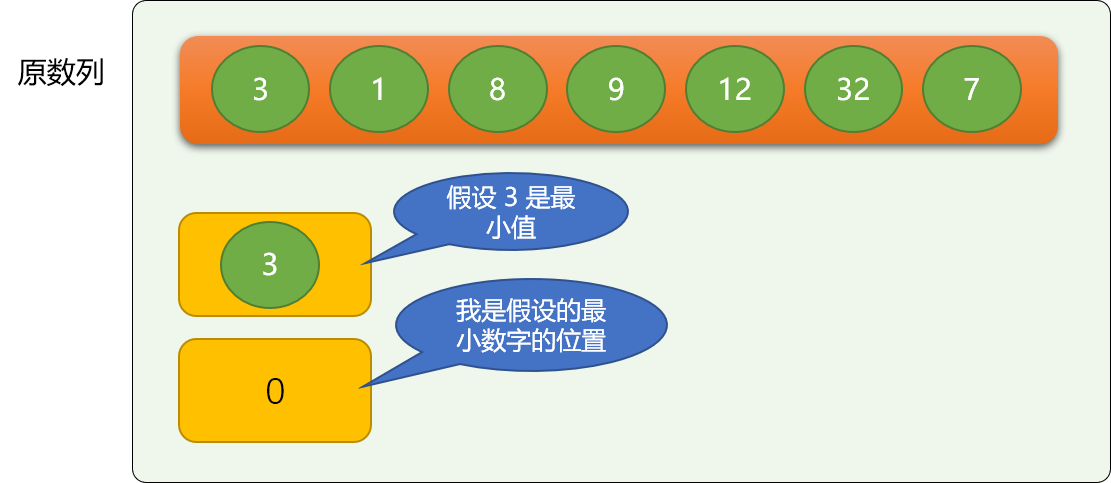
nums = [6, 2, 5, 9, 12, 1, 7]
# 擂台!假充第一 个数字是最小值
mi = nums[0]
# 假设的最小数字位置
mi_idx = 0
# 真正最小数字的位置
real_idx = mi_idx
for i in range(mi_idx + 1, len(nums)):
if nums[i] < mi:
mi = nums[i]
# 记住更小数字的位置,不记着交换
real_idx = i
# 如有更小的
if real_idx != mi_idx:
# 交换
nums[real_idx], nums[mi_idx] = nums[mi_idx], nums[real_idx]
print(nums)
'''
输出结果
[1, 2, 5, 9, 12, 6, 7]
'''
以上代码就是选择排序的核心逻辑,实现了把最小的数字移动最前面。
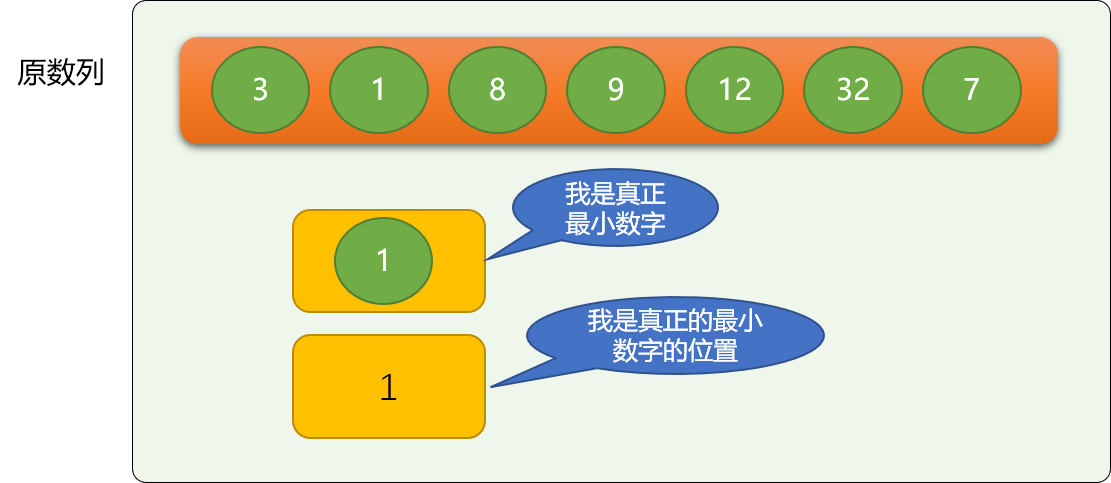
再在上述逻辑基础上,继续在后续数字中找出最小值,并移动前面。多找几次就可以了!本质和冒泡算法还是一样的,不停找最大(小)值。
nums = [6, 2, 5, 9, 12, 1, 7]
for j in range(len(nums)-1):
mi = nums[j]
# 假设的最小数字位置
mi_idx = j
# 真正最小数字的位置
real_idx = mi_idx
for i in range(mi_idx + 1, len(nums)):
if nums[i] < mi:
mi = nums[i]
# 记住更小数字的位置
real_idx = i
# 如有更小的
if real_idx != mi_idx:
# 交换
nums[real_idx], nums[mi_idx] = nums[mi_idx], nums[real_idx]
print(nums)
'''
输出结果:
[1, 2, 5, 6, 7, 9, 12]
'''
选择排序的时间复杂度和冒泡排序的一样 O(n2)。
4. 插入排序
打牌的时候,我们刚拿到手上的牌是无序的,在整理纸牌并让纸牌一步一步变得的有序的过程就是插入算法的思路。
插入排序的核心思想:
1.把原数列从逻辑(根据起始位置和结束位置在原数列上划分)上分成前、后两个数列,前面的数列是有序的,后面的数列是无序的。
刚开始时,前面的数列(后面简称前数列)只有唯一的一个数字,即原数列的第一个数字。显然是排序的!

2.依次从后数列中逐个拿出数字,与前数列的数字进行比较,保证插入到前数列后,整个前数列还是有序的。
如上,从后数列中拿到数字 1 ,然后与前数字的 3 进行比较,如果是从大到小排序,则 1 就直接排到 3 后面,如果是从小到大排序,则 1 排到 3 前面。
这里,按从小到大排序。

从如上描述可知,插入排序核心逻辑是:
- 比较: 后数列的数字要与前数字的数字进行大小比较,这个与冒泡和选择排序没什么不一样。
- 移位: 如果前数列的数字大于后数列的数字,则需要向后移位。也可以和冒泡排序一样交换。
- 插入: 为后数列的数字在前数列中找到适当位置后,插入此数据。
插入排序的代码实现:
这里使用前指针和后指针的方案。
前指针用来在前数列中定位数字,方向是从右向左。
后指针用来在后数字中定位数字,方向是从左向右。
前指针初始的位置之前为前数列,后指针初始时的位置为后数列。

nums = [3, 1, 8, 9, 12, 32, 7]
# 后指针指向原数列的第 2 个数字,所以索引号从 1 开始
for back_idx in range(1, len(nums)):
# 前指针和后指针的关系,
front_idx = back_idx - 1
# 临时变量,比较时,前数列的数字有可能要向后移位,需要把后指针指向的数字提前保存
tmp = nums[back_idx]
# 与前数列中的数字比较
while front_idx >= 0 and tmp < nums[front_idx]:
# 移位
nums[front_idx + 1] = nums[front_idx]
front_idx -= 1
if front_idx != back_idx - 1:
# 插入
nums[front_idx + 1] = tmp
print(nums)
'''
输出结果
[1,3,7,8,9,12,32]
'''
上述代码用到了移位和插入操作,也可以使用交换操作。如果是交换操作,则初始时,前、后指针可以指向同一个位置。
nums = [3, 1, 8, 9, 12, 32, 7]
for back_idx in range(1, len(nums)):
for front_idx in range(back_idx, 0, -1):
if nums[front_idx] < nums[front_idx - 1]:
nums[front_idx], nums[front_idx - 1] = nums[front_idx - 1], nums[front_idx]
else:
break
print(nums)
后指针用来选择后数列中的数字,前指针用来对前数列相邻数字进行比较、交换。和冒泡排序一样。
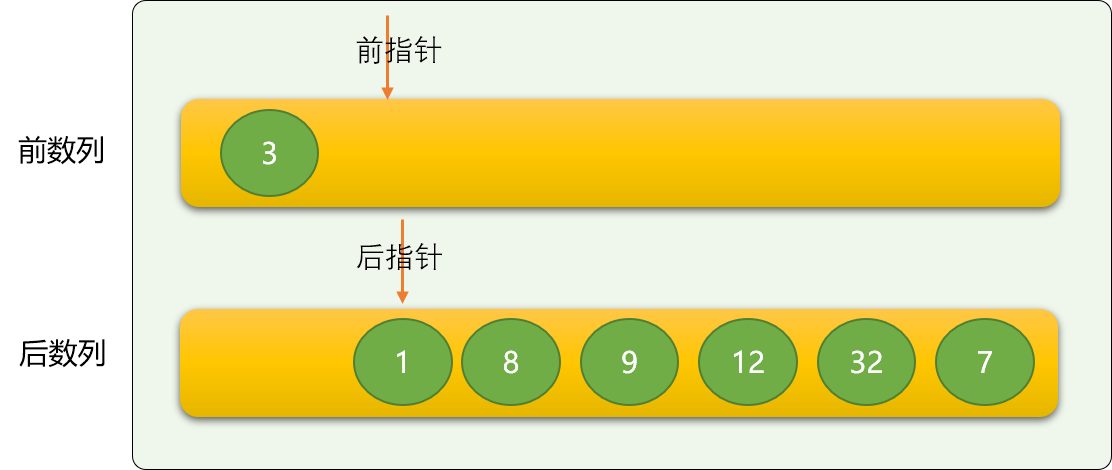
这里有一个比冒泡排序优化的地方,冒泡排序需要对数列中所有相邻两个数字进行比较,不考虑是不是有必要比较。
但插入不一样,因插入是假设前面的数列是有序的,所以如果后指针指向的数字比前数列的最后一个数字都大,显然,是不需要再比较下去,如下的数字 `` 是不需要和前面的数字进行比较,直接放到前数列的尾部。

插入排序的时间复杂度还是 O(n2) 。
5. 快速排序
快速排序是一个很有意思的排序算法,快速排序的核心思想:
分治思想: 全局到局部、或说是粗糙到完美的逐步细化过程。
类似于画人物画。
先绘制一个轮廓图,让其看起来像什么!
然后逐步细化,让它真的就是什么!
快速排序也是这个思想,刚开始,让数列粗看起来有序,通过逐步迭代,让其真正有序。
二分思想: 在数列选择一个数字(基数)为参考中心,数列比基数大的,放在左边(右边),比基数小的,放在右边(左边)。
第一次的二分后:整个数列在基数之上有了有序的轮廓,然后在对基数前部分和后部分的数字继续完成二分操作。
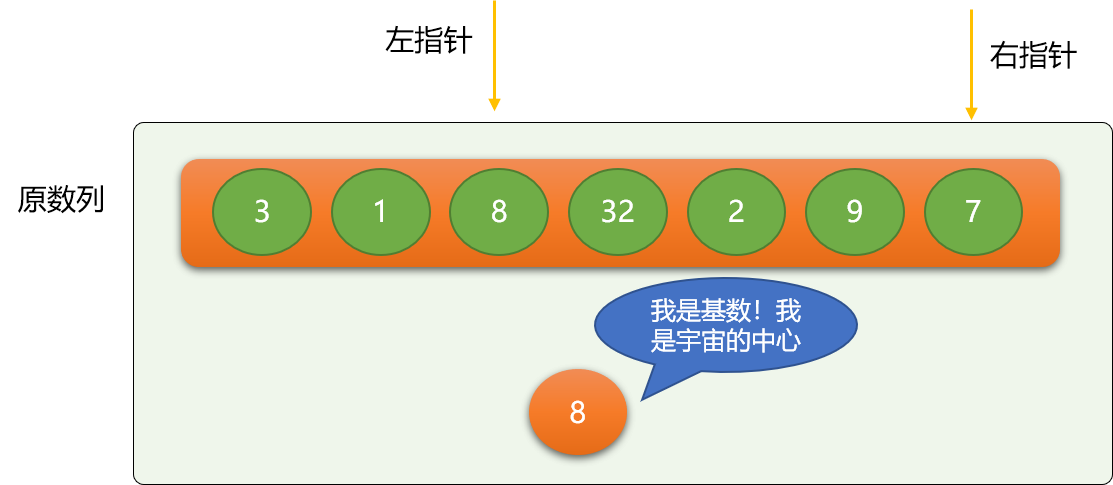
这里使用左、右指针方式描述快速排序:
- 左指针初始指向最左边数字。
- 右指针初始指向最右边数字。
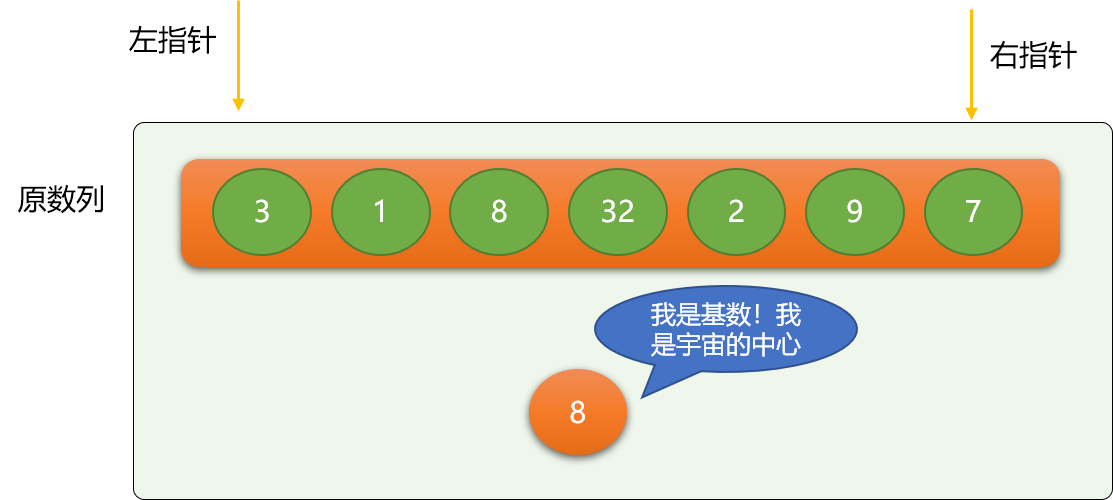
这里选择 8 作为第一次二分的基数,基数的选择没有特定要求,只要是数列中的数字,别客气,任意选择。这里把比 8 小的移到 8 的左边,比 8 大的移动 8 的右边。
移位的流程:
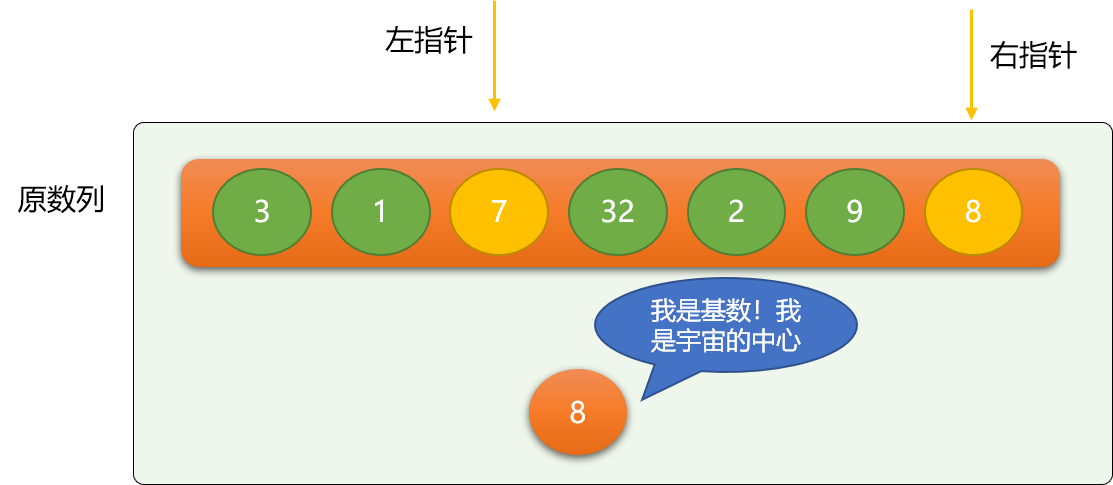
- 左指针不停向右移动,至到遇到大于等于基数的数字 ,同理右指针不停向左移动,至到碰到小于等于基数的数字。
- 交换左指针和右指针的位置的数据。
如上图,左指针最后会停止在数字 8 所在位置,右指针会停在数字 7 所在位置。
交换左、右指针位置的数字。
依此类推,继续移动指针、交换。
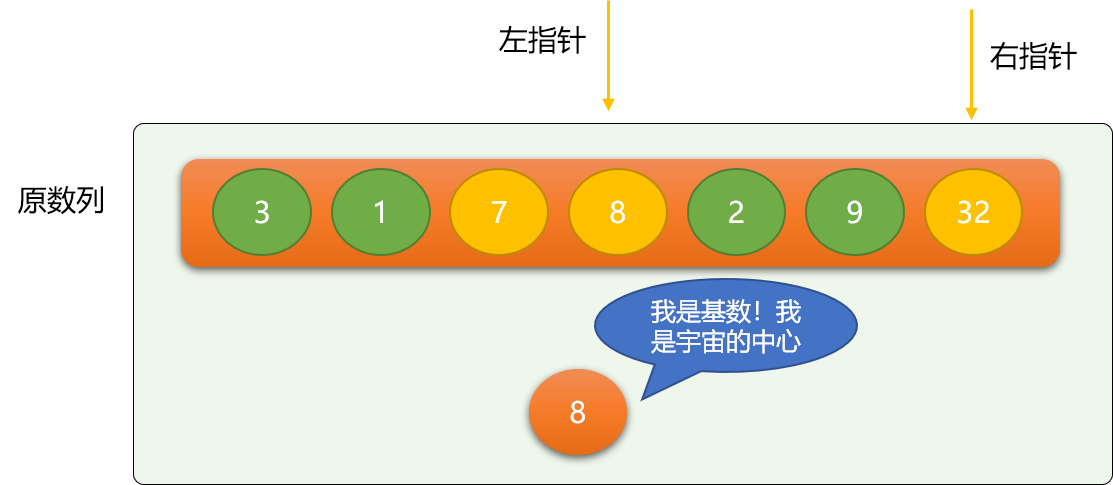
第一次二分后,整个数列会变成如下图所示:
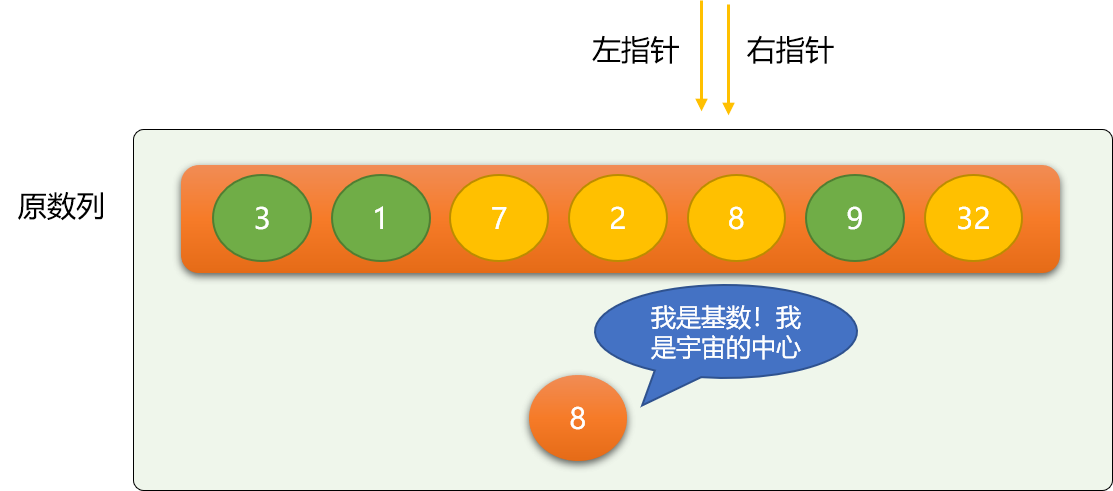
当左、右指针重合在一起时,第一次二分过程到此结束。以基数 8 为分界线,把原数列分成前、后两部分,继续在前、后数列上面使用如上二分思想 。显然,使用递归是最直接有效的选择。
如下第一次二分代码:
nums = [3, 1, 8, 32, 2, 9, 7]
def quick_sort(nums):
# 左指针
left = 0
# 右指针
right = len(nums) - 1
# 基数,可以是任意数字,一般选择数列的第一个数字
base_n = 8
while left < right:
# 左指针向右移动,至到时左指针位置数字大于等于基数,
while nums[left] < base_n and left < right:
left += 1
while nums[right] > base_n and right > left:
right -= 1
# 交换
nums[left], nums[right] = nums[right], nums[left]
quick_sort(nums)
print(nums)
输出结果:
[3, 1, 7, 2, 8, 9, 32]
和上面的演示流程图的结果一样。
使用递归进行多次二分:
nums = [3, 1, 8, 32, 2, 9, 7]
def quick_sort(nums, start, end):
if start >= end:
return
# 左指针
left = start
# 右指针
right = end
# 基数
base_n = nums[start]
while left < right:
while nums[right] > base_n and right > left:
right -= 1
# 左指针向右移动,至到时左指针位置数字大于等于基数,
while nums[left] < base_n and left < right:
left += 1
# 交换
nums[left], nums[right] = nums[right], nums[left]
# 左边数列
quick_sort(nums, start, left - 1)
# 右边数列
quick_sort(nums, right + 1, end)
quick_sort(nums, 0, len(nums) - 1)
print(nums)
'''
输出结果
[1, 2, 3, 7, 8, 9, 32]
'''
快速排序的时间复杂度为 O(nlogn),空间复杂度为O(nlogn)。
6. 总结
除了冒泡、选择、插入、快速排序算法,还有很多其它的排序算法,冒泡、选择 、插入算法很类似,有其相似的比较、交换逻辑。快速排序使用了分治理念,可从减少时间复杂度。
到此这篇关于详解Python排序算法的实现(冒泡,选择,插入,快速)的文章就介绍到这了,更多相关Python 排序算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现排序算法解析
本文实例为大家分享了python实现排序算法的具体代码,供大家参考,具体内容如下 一.冒泡排序 def bububle_sort(alist): """冒泡排序(稳定|n^2m)""" n = len(alist) for j in range(n-1): count = 0 for i in range(0,n-1-j): if alist[i]>alist[i+1]: count +=1 alist[i], alist[i+1] = a
-
python数据结构的排序算法
目录 十大经典的排序算法 一.交换排序 1.冒泡排序(前后比较-交换) 2.快速排序(选取一个基准值,小数在左大数在右) 二.插入排序 1.简单插入排序(逐个插入到前面的有序数中) 2.希尔排序(从大范围到小范围进行比较-交换) 三.选择排序 1.简单选择排序(选择最小的数据放在前面) 2.堆排序(利用最大堆和最小堆的特性) 四.归并排序 五.其他排序 1.计数排序(字典计数-还原) 2.桶排序(链表) 3.基数排序 十大经典的排序算法 数据结构中的十大经典算法:冒泡排序.快速排序.简单插入排序
-
python实现经典排序算法的示例代码
以下排序算法最终结果都默认为升序排列,实现简单,没有考虑特殊情况,实现仅表达了算法的基本思想. 冒泡排序 内层循环中相邻的元素被依次比较,内层循环第一次结束后会将最大的元素移到序列最右边,第二次结束后会将次大的元素移到最大元素的左边,每次内层循环结束都会将一个元素排好序. def bubble_sort(arr): length = len(arr) for i in range(length): for j in range(length - i - 1): if arr[j] > arr[j
-
Python 十大经典排序算法实现详解
目录 关于时间复杂度 关于稳定性 名词解释 1.冒泡排序 (1)算法步骤 (2)动图演示 (3)Python代码 2.选择排序 (1)算法步骤 (2)动图演示 (3)Python代码 3.插入排序 (1)算法步骤 (2)动图演示 (3)Python代码 4.希尔排序 (1)算法步骤 (2)Python代码 5.归并排序 (1)算法步骤 (2)动图演示 (3)Python代码 6.快速排序 (1)算法步骤 (2)动图演示 (3)Python代码 7.堆排序 (1)算法步骤 (2)动图演示 (3)P
-
python如何实现常用的五种排序算法详解
一.冒泡排序 原理: 比较相邻的元素.如果第一个比第二个大就交换他们两个 每一对相邻元素做同样的工作,直到结尾最后一对 每个元素都重复以上步骤,除了最后一个 第一步: 将乱序中的最大值找出,逐一移到序列最后的位置 alist = [3, 5, 9, 2, 1, 7, 8, 6, 4] def bubble_sort(alist): # 找最大值的方式是通过对列表中的元素进行两两比较,值大的元素逐步向后移动 # 序列中有n个元素,两两比较的话,需要比较n-1次 for i in range(len
-
10个python3常用排序算法详细说明与实例(快速排序,冒泡排序,桶排序,基数排序,堆排序,希尔排序,归并排序,计数排序)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法. Python3常用排序算法 1.Python3冒泡排序--交换类排序 冒泡排序(Bubble Sort)也是一种简单直观的排序算法. 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来. 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 作为最简单的排序算法
-
python常用排序算法的实现代码
这篇文章主要介绍了python常用排序算法的实现代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升. 1.插入排序 插入排序默认当前被插入的序列是有序的,新元素插入到应该插入的位置,使得新序列仍然有序. def insertion_sort(old_list): n=len(old_list) k=0 for i in range(1,n): temp=old_lis
-
详解Python排序算法的实现(冒泡,选择,插入,快速)
目录 1. 前言 2. 冒泡排序算法 2.1 摆擂台法 2.2 相邻两个数字相比较 3. 选择排序算法 4. 插入排序 5. 快速排序 6. 总结 1. 前言 所谓排序,就是把一个数据群体按个体数据的特征按从大到小或从小到大的顺序存放. 排序在应用开发中很常见,如对商品按价格.人气.购买数量……显示. 初学编程者,刚开始接触的第一个稍微有点难理解的算法应该是排序算法中的冒泡算法. 我初学时,“脑思维”差点绕在 2 个循环结构的世界里出不来了.当时,老师要求我们死记冒泡的口诀,虽然有点搞笑,但是当
-
详解Python查找算法的实现(线性、二分、分块、插值)
目录 1. 线性查找 2. 二分查找 3. 插值查找 4. 分块查找 5. 总结 查找算法是用来检索序列数据(群体)中是否存在给定的数据(关键字),常用查找算法有: 线性查找:线性查找也称为顺序查找,用于在无序数列中查找. 二分查找:二分查找也称为折半查找,其算法用于有序数列. 插值查找:插值查找是对二分查找算法的改进. 分块查找:又称为索引顺序查找,它是线性查找的改进版本. 树表查找:树表查找又可分二叉查找树.平衡二叉树查找. 哈希查找:哈希查找可以直接通过关键字查找到所需要数据. 因树表查找
-
详解Python中图像边缘检测算法的实现
目录 写在前面 1.一阶微分算子 1.1 Prewitt算子 1.2 Sobel算子 2.二阶微分算子 2.1 Laplace算子 2.2 LoG算子 3.Canny边缘检测 写在前面 从本节开始,计算机视觉教程进入第三章节——图像特征提取.在本章,你会见到一张简简单单的图片中蕴含着这么多你没注意到的细节特征,而这些特征将会在今后更高级的应用中发挥着极其重要的作用.本文讲解基础特征之一——图像边缘. 本文采用面向对象设计,定义了一个边缘检测类EdgeDetect,使图像边缘检测算法的应用更简洁,
-
详解Python中4种超参自动优化算法的实现
目录 一.网格搜索(Grid Search) 二.随机搜索(Randomized Search) 三.贝叶斯优化(Bayesian Optimization) 四.Hyperband 总结 大家好,要想模型效果好,每个算法工程师都应该了解的流行超参数调优技术. 今天我给大家总结超参自动优化方法:网格搜索.随机搜索.贝叶斯优化 和 Hyperband,并附有相关的样例代码供大家学习. 一.网格搜索(Grid Search) 网格搜索是暴力搜索,在给定超参搜索空间内,尝试所有超参组合,最后搜索出最优
-
详解Python OpenCV图像分割算法的实现
目录 前言 1.图像二值化 2.自适应阈值分割算法 3.Otsu阈值分割算法 4.基于轮廓的字符分离 4.1轮廓检测 4.2轮廓绘制 4.3包围框获取 4.4矩形绘制 前言 图像分割是指根据灰度.色彩.空间纹理.几何形状等特征把图像划分成若干个互不相交的区域. 最简单的图像分割就是将物体从背景中分割出来 1.图像二值化 cv2.threshold是opencv-python中的图像二值化方法,可以实现简单的分割功能. retval, dst = cv2.threshold(src, thresh
-
python 贪心算法的实现
贪心算法 贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择.也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解. 贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关. 基本思路 思想 贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解.每一步只考虑一个数据,他的选取应该满足局部优化的条件.若
-
python 决策树算法的实现
''' 数据集:Mnist 训练集数量:60000 测试集数量:10000 ------------------------------ 运行结果:ID3(未剪枝) 正确率:85.9% 运行时长:356s ''' import time import numpy as np def loadData(fileName): ''' 加载文件 :param fileName:要加载的文件路径 :return: 数据集和标签集 ''' # 存放数据及标记 dataArr = []; labelArr
-
详解python使用金山词霸的翻译功能(调试工具断点的使用)
今天试着用python获取金山词霸的翻译功能,链接在这里: ICIBA传送门 打开之后,界面是这样的,还是比较干净的. 按F12,打开调试工具,选择Network,找到XHR 这里就是查看网络传输的内容.XHR就是不刷新页面的网络传输,就是常说的ajax(阿贾克斯,像是希腊神话里的名字--). 然后我们在翻译窗口写点儿内容,然后点翻译 看,左边的页面出现了翻译结果,右边调试窗口出现了两条数据传输. 两条?那我们选哪条呢?点开看看-- 哦,天哪~两条都是一样的,那我们随便选一条就可以了. 点一下,
-
详解Python 关联规则分析
1. 关联规则 大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品. 不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules. 关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系. 1