卷积神经网络经典模型及其改进点学习汇总
目录
- 经典神经网络的改进点
- 经典神经网络的结构汇总
- 1、VGG16
- 2、ResNet50
- 3、InceptionV3
- 4、Xception
- 5、MobileNet
经典神经网络的改进点
| 名称 | 改进点 |
|---|---|
| VGG16 | 1、使用非常多的3*3卷积串联,利用小卷积代替大卷积,该操作使得其拥有更少的参数量,同时会比单独一个卷积层拥有更多的非线性变换。2、探索了卷积神经网络的深度与其性能之间的关系,成功构建16层网络(还有VGG19的19层网络)。 |
| ResNet50 | 1、使用残差网络,其可以解决由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。2、采用bottleneck design结构,在3x3网络结构前利用1x1卷积降维,在3x3网络结构后,利用1x1卷积升维,相比直接使用3x3网络卷积效果更好,参数更少。 |
| InceptionV3 | 1、Inception系列通用的改进点是使用不同大小的卷积核,使得存在不同大小的感受野,最后实现拼接达到不同尺度特征的融合。2、利用1x7的卷积和7x1的卷积代替7x7的卷积,这样可以只使用约(1x7 + 7x1) / (7x7) = 28.6%的计算开销;利用1x3的卷积和3x1的卷积代替3x3的卷积,这样可以只使用约(1x3 + 3x1) / (3x3) = 67%的计算开销。 |
| Xception | 1、开始采用残差网络,其可以解决由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。2、采用SeparableConv2D层,利用深度可分离卷积减少参数量。 |
| MobileNet | 1、是一种轻量级的深层神经网络,为一定设备设计。 2、采用depthwise separable convolution结构,3x3卷积核厚度只有一层,然后在输入张量上一层一层地滑动,所以一个卷积核就对应了一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度,实现参数减少。 |
经典神经网络的结构汇总
1、VGG16

1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
5、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
6、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
具体实现代码可以看我的博文神经网络学习VGG16模型的复现及其详解(包含如何预测)
2、ResNet50
ResNet50最大的特点是使用了残差网络。
残差网络的特点是将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下:

ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;
Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:

Identity Block的结构如下:

这两个都是残差网络结构。
总的网络结构如下:

具体实现代码可以看我的博文神经网络学习——ResNet50模型的复现详解
3、InceptionV3
Inception系列的网络的特点是采用不同大小的卷积核,使得存在不同大小的感受野,最后实现拼接达到不同尺度特征的融合。
对于InceptionV3而言,其网络中存在着如下的结构。
这个结构使用不同大小的卷积核对输入进行卷积(这个结构主要在代码中的block1使用)。

还存在着这样的结构,利用1x7的卷积和7x1的卷积代替7x7的卷积,这样可以只使用约(1x7 + 7x1) / (7x7) = 28.6%的计算开销;
利用1x3的卷积和3x1的卷积代替3x3的卷积,这样可以只使用约(1x3 + 3x1) / (3x3) = 67%的计算开销。
下图利用1x7的卷积和7x1的卷积代替7x7的卷积(这个结构主要在代码中的block2使用)。

下图利用1x3的卷积和3x1的卷积代替3x3的卷积(这个结构主要在代码中的block3使用)。
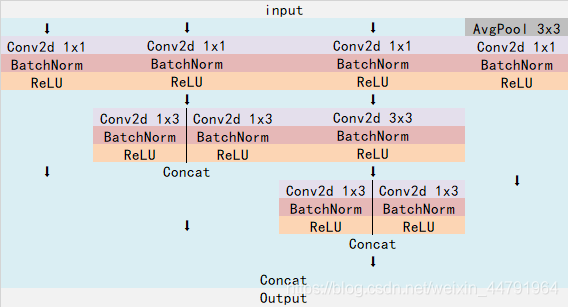
具体实现代码可以看我的博文神经网络学习——InceptionV3模型的复现详解
4、Xception
Xception是谷歌公司继Inception后,提出的InceptionV3的一种改进模型,其改进的主要内容为采用depthwise separable convolution来替换原来Inception v3中的多尺寸卷积核特征响应操作。
在讲Xception模型之前,首先要讲一下什么是depthwise separable convolution(深度可分离卷积块)。
深度可分离卷积块由两个部分组成,分别是深度可分离卷积和1x1普通卷积,深度可分离卷积的卷积核大小一般是3x3的,便于理解的话我们可以把它当作是特征提取,1x1的普通卷积可以完成通道数的调整。
下图为深度可分离卷积块的结构示意图:

深度可分离卷积块的目的是使用更少的参数来代替普通的3x3卷积。
我们可以进行一下普通卷积和深度可分离卷积块的对比:
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
通俗地理解深度可分离卷积结构块,就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,再利用1x1的卷积调整厚度。
Xception使用的深度可分离卷积块SeparableConv2D也就是先深度可分离卷积再进行1x1卷积。
对于Xception模型而言,其一共可以分为3个flow,分别是Entry flow、Middle flow、Exit flow;
分为14个block,其中Entry flow中有4个、Middle flow中有8个、Exit flow中有2个。
具体结构如下:

其内部主要结构就是残差卷积网络搭配SeparableConv2D层实现一个个block,在Xception模型中,常见的两个block的结构如下。
这个主要在Entry flow和Exit flow中:

这个主要在Middle flow中:

具体实现代码可以看我的博文神经网络学习——Xception模型的复现详解
5、MobileNet
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution。
对于一个卷积点而言:
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。
具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
如下这张图就是depthwise separable convolution的结构
在建立模型的时候,可以使用Keras中的DepthwiseConv2D层实现深度可分离卷积,然后再利用1x1卷积调整channels数。
通俗地理解就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。
如下就是MobileNet的结构,其中Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理,

具体实现代码可以看我的博文神经网络学习——MobileNet模型的复现详解
以上就是卷积神经网络经典模型及其改进点学习汇总的详细内容,更多关于卷积神经网络模型改进的资料请关注我们其它相关文章!
相关推荐
-
TensorFlow keras卷积神经网络 添加L2正则化方式
我就废话不多说了,大家还是直接看代码吧! model = keras.models.Sequential([ #卷积层1 keras.layers.Conv2D(32,kernel_size=5,strides=1,padding="same",data_format="channels_last",activation=tf.nn.relu,kernel_regularizer=keras.regularizers.l2(0.01)), #池化层1 keras.l
-

Python深度学习之实现卷积神经网络
一.卷积神经网络 Yann LeCun 和Yoshua Bengio在1995年引入了卷积神经网络,也称为卷积网络或CNN.CNN是一种特殊的多层神经网络,用于处理具有明显网格状拓扑的数据.其网络的基础基于称为卷积的数学运算. 卷积神经网络(CNN)的类型 以下是一些不同类型的CNN: 1D CNN:1D CNN 的输入和输出数据是二维的.一维CNN大多用于时间序列. 2D CNNN:2D CNN的输入和输出数据是三维的.我们通常将其用于图像数据问题. 3D CNNN:3D CNN的输入和输出数
-
使用卷积神经网络(CNN)做人脸识别的示例代码
上回书说到了对人脸的检测,这回就开始正式进入人脸识别的阶段. 关于人脸识别,目前有很多经典的算法,当我大学时代,我的老师给我推荐的第一个算法是特征脸法,原理是先将图像灰度化,然后将图像每行首尾相接拉成一个列向量,接下来为了降低运算量要用PCA降维, 最后进分类器分类,可以使用KNN.SVM.神经网络等等,甚至可以用最简单的欧氏距离来度量每个列向量之间的相似度.OpenCV中也提供了相应的EigenFaceRecognizer库来实现该算法,除此之外还有FisherFaceRecognizer.L
-
Numpy实现卷积神经网络(CNN)的示例
import numpy as np import sys def conv_(img, conv_filter): filter_size = conv_filter.shape[1] result = np.zeros((img.shape)) # 循环遍历图像以应用卷积运算 for r in np.uint16(np.arange(filter_size/2.0, img.shape[0]-filter_size/2.0+1)): for c in np.uint16(np.arange(
-
使用pytorch提取卷积神经网络的特征图可视化
目录 前言 1. 效果图 2. 完整代码 3. 代码说明 4. 可视化梯度,feature 总结 前言 文章中的代码是参考基于Pytorch的特征图提取编写的代码本身很简单这里只做简单的描述. 1. 效果图 先看效果图(第一张是原图,后面的都是相应的特征图,这里使用的网络是resnet50,需要注意的是下面图片显示的特征图是经过放大后的图,原图是比较小的图,因为太小不利于我们观察): 2. 完整代码 import os import torch import torchvision as tv
-
卷积神经网络的网络结构图Inception V3
目录 1.基于大滤波器尺寸分解卷积 1.1分解到更小的卷积 1.2. 空间分解为不对称卷积 2. 利用辅助分类器 3.降低特征图大小 Inception-V3模型: 总结: <Rethinking the Inception Architecture for Computer Vision> 2015,Google,Inception V3 1.基于大滤波器尺寸分解卷积 GoogLeNet性能优异很大程度在于使用了降维.降维可以看做卷积网络的因式分解.例如1x1卷积层后跟着3x3卷积层.在网络
-
卷积神经网络经典模型及其改进点学习汇总
目录 经典神经网络的改进点 经典神经网络的结构汇总 1.VGG16 2.ResNet50 3.InceptionV3 4.Xception 5.MobileNet 经典神经网络的改进点 名称 改进点 VGG16 1.使用非常多的3*3卷积串联,利用小卷积代替大卷积,该操作使得其拥有更少的参数量,同时会比单独一个卷积层拥有更多的非线性变换.2.探索了卷积神经网络的深度与其性能之间的关系,成功构建16层网络(还有VGG19的19层网络). ResNet50 1.使用残差网络,其可以解决由于网络深度加
-
TensorFlow 实战之实现卷积神经网络的实例讲解
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.相关性概念 1.卷积神经网络(ConvolutionNeural Network,CNN) 19世纪60年代科学家最早提出感受野(ReceptiveField).当时通过对猫视觉皮层细胞研究,科学家发现每一个视觉神经元只会处理一小块区域的视觉图像,即感受野.20世纪80年代,日本科学家提出神经认知机(Neocognitron)的概念,被视为卷积神经网络最初
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
深度卷积神经网络各种改进结构块汇总
目录 学习前言 1.残差网络 2.不同大小卷积核并行卷积 3.利用(1,x),(x,1)卷积代替(x,x)卷积 4.采用瓶颈(Bottleneck)结构 5.深度可分离卷积 6.改进版深度可分离卷积+残差网络 7.倒转残差(Inverted residuals)结构 8.并行空洞卷积 学习前言 看了好多代码呀,看了后面忘了前面,这个BLOG主要是记录一些神经网络的改进结构,比如残差结构那种,记录下来有助于自己设计一些轻且好的网络. 1.残差网络 这个网络主要源自于Resnet网络,其作用是: 将
-
Pytorch卷积神经网络迁移学习的目标及好处
目录 前言 一.经典的卷积神经网络 二.迁移学习的目标 三.好处 四.步骤 五.代码 前言 在深度学习训练的过程中,随着网络层数的提升,我们训练的次数,参数都会提高,训练时间相应就会增加,我们今天来了解迁移学习 一.经典的卷积神经网络 在pytorch官网中,我们可以看到许多经典的卷积神经网络. 附官网链接:https://pytorch.org/ 这里简单介绍一下经典的卷积神经发展历程 1.首先可以说是卷积神经网络的开山之作Alexnet(12年的夺冠之作)这里简单说一下缺点 卷积核大,步长大
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
Python深度学习pytorch卷积神经网络LeNet
目录 LeNet 模型训练 在本节中,我们将介绍LeNet,它是最早发布的卷积神经网络之一.这个模型是由AT&T贝尔实验室的研究院Yann LeCun在1989年提出的(并以其命名),目的是识别手写数字.当时,LeNet取得了与支持向量机性能相媲美的成果,成为监督学习的主流方法.LeNet被广泛用于自动取款机中,帮助识别处理支票的数字. LeNet 总体来看,LeNet(LeNet-5)由两个部分组成: 卷积编码器: 由两个卷积层组成 全连接层密集快: 由三个全连接层组成 每个卷积块中的基本单元
-
tensorflow学习笔记之mnist的卷积神经网络实例
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=Tru
-
TensorFlow深度学习另一种程序风格实现卷积神经网络
import tensorflow as tf import numpy as np import input_data mnist = input_data.read_data_sets('data/', one_hot=True) print("MNIST ready") n_input = 784 # 28*28的灰度图,像素个数784 n_output = 10 # 是10分类问题 # 权重项 weights = { # conv1,参数[3, 3, 1, 32]分别指定了fi