Pandas实现数据拼接的操作方法详解
目录
- merge 操作
- merge 拼接方式
- merge 举例
- join 操作
- join 举例
- concat 操作
- concat 举例
- append 举例
数据科学领域日常使用 Python 处理大规模数据集的时候经常需要使用到合并、链接的方式进行数据集的整合,其中应用的数据类型包括 Series 和 DataFrame,可以使用的方法也很多,比如本文中介绍的 .merge()、 .join() 和 .concat() 三种方法,进行拼接处理后的数据集可以发挥最大的用途。
merge 操作
.merge() 方法是用于组合通用列或索引上的数据,这个方法有点类似于 MySQL 中的 join 操作,可以实现左拼接、右拼接、全连接等操作。
通过关键字的索引进行拼接,实现多对一、一对多、多对多(笛卡尔乘积)连接。
merge 中参数解释:
- how:定义合并方式,选择参数有 『inner』,『outer』, 『left’』,『right』。
- on:定义2个 DataFrame 中都必须包含的列用于连接(索引键)。
- left_on 和 right_on:指定要合并的左侧或右侧对象中存在的列或索引。
- left_index 和 right_index:默认为 False,设置为以索引列作为合并基准。
- suffixes:字符串元组,用于附加到不是合并键的相同列名。
merge 拼接方式
一张图就能看明白不同关键字参数 merger 的方式。

merge 举例
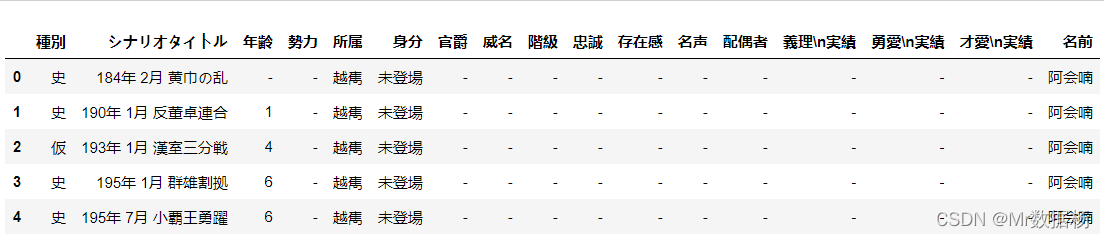
数据读取
我们要进行势力所属和人物直接关系的拼接操作,读取的数据包括下面的2个列表,并将 人物历史登入数据 中没有势力的数据剔除。
import pandas as pd
country = pd.read_excel("Romance of the Three Kingdoms 13/势力列表.xlsx")
people = pd.read_excel("Romance of the Three Kingdoms 13/人物历史登入数据.xlsx")
# 剔除不包含的势力数据,即武将在野的状态
people = people[people["勢力"]!="-"]
country.head()

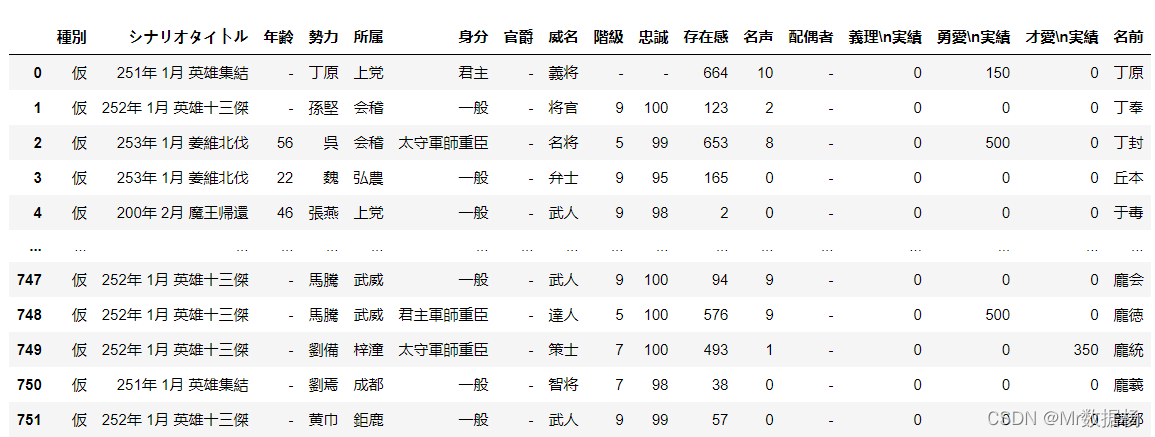
people.head()
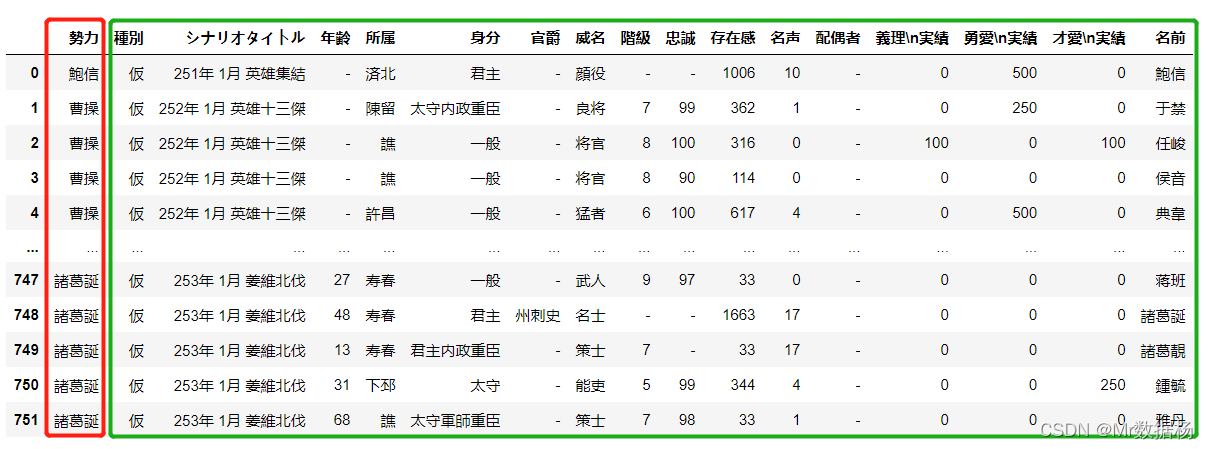
内部联接
使用 merge 默认参数可以直接进行内部连接,匹配两个DataFrame交集的结果。
将人物和所属势力进行一个拼接,这里我们取的是这个人物最终归属的势力,即改人物数据聚合后的最后一条数据信息。
people_new = people.groupby('名前').nth(-1)
people_new["名前"] = people_new.index
people_new.reset_index(drop=True,inplace=True)
people_new
merge 中DataFrame的顺序决定了拼接结果的顺序。
inner_merged_total = pd.merge(country,people_new,on=["勢力"]) inner_merged_total.head()
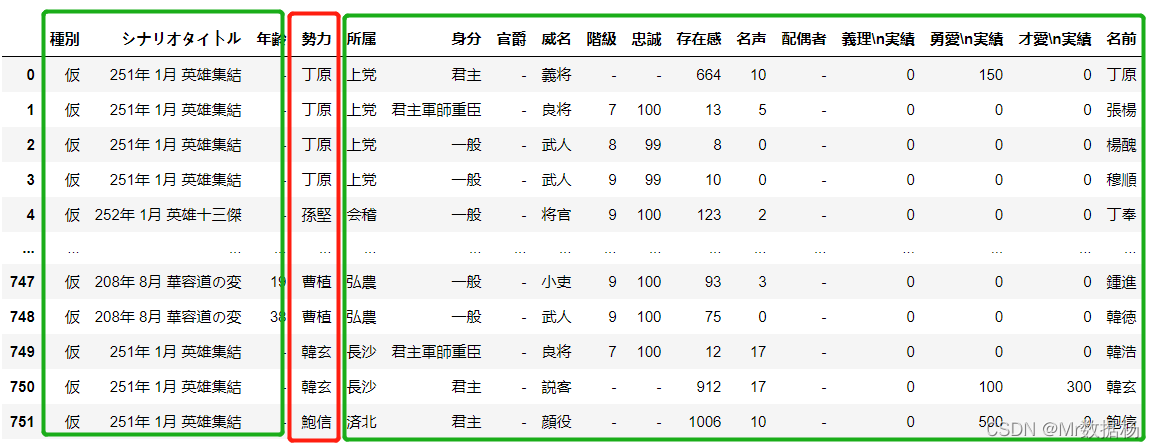
inner_merged_total = pd.merge(people_new,country,on=["勢力"]) inner_merged_total.head()
外连接
外连接(也称为完全外连接)中,来自两个 DataFrame 的所有行都将出现在新的 DataFrame 中。
本质上对于数据全的 df_A 和包含的 df_B 进行 outer 拼接,相当于 pd.merge(df_A ,df_B,on=[“key”])。
outer_merged = pd.merge(people_new,country,how="outer",on=["勢力"]) outer_merged.head()
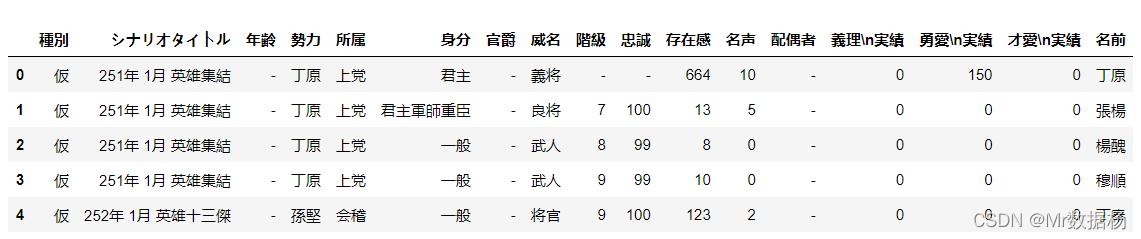
如果我们不剔除在野武将的数据的话会发现是整张表单进行拼接。
country = pd.read_excel("Romance of the Three Kingdoms 13/势力列表.xlsx")
people = pd.read_excel("Romance of the Three Kingdoms 13/人物历史登入数据.xlsx")
outer_merged = pd.merge(people_new,country,how="outer",on=["勢力"])
outer_merged
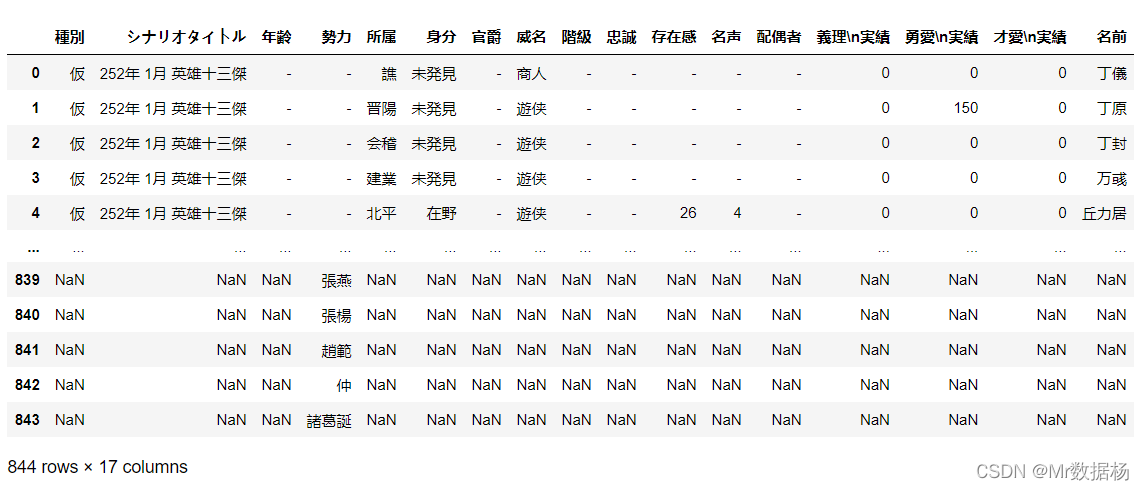
左连接
新合并的 DataFrame 与左侧 DataFrame 中的所有行一起保留(即merge中的第一个dataframe),同时丢弃右侧 DataFrame 中在左侧 DataFrame 的键列中没有匹配的行。
left_merged = pd.merge(people_new,country,how="left",on=["勢力"]) left_merged
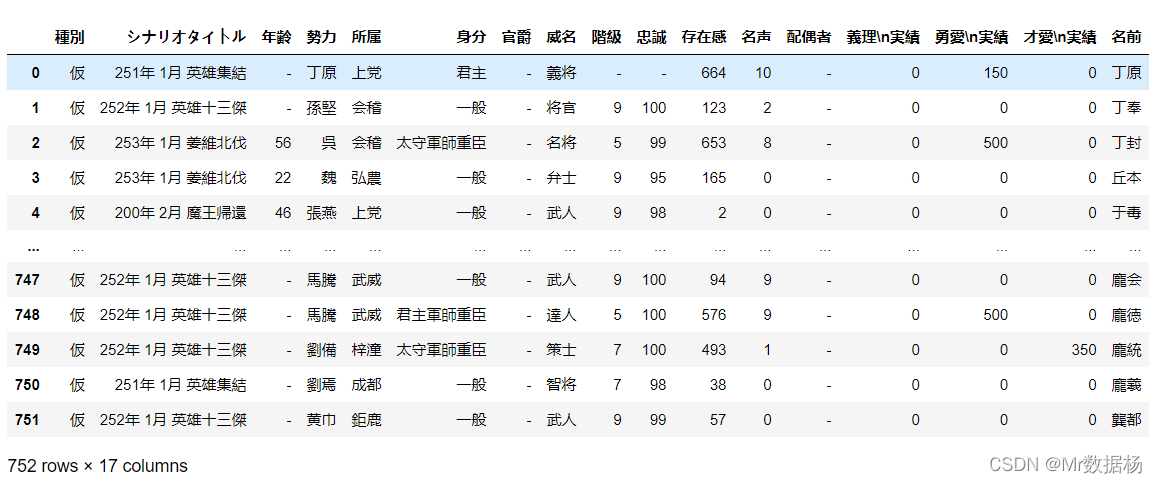
右连接
新合并的 DataFrame 与右侧 DataFrame 中的所有行一起保留(即merge中的第二个dataframe),同时丢弃右侧 DataFrame 中在左侧 DataFrame 的键列中没有匹配的行。
right_merged = pd.merge(people_new,country,how="right",on=["勢力"]) right_merged

join 操作
join 操作和 merge 很相似,是在列或索引上组合数据,join 相当于指定了 merge 中的第一个 DataFreme 。并且命名冲突的列可以定义后缀进行重新命名。
这个结果和之前的左右 merger 很相似。
join 中参数解释:
- other:定义要拼接的 DataFrame。
- on:指定左侧 DataFrame 的可选列或索引名称。如果设置为 None,这是默认 index 连接。
- how:与 merge 中的 how 具有相同,如果不指定列则使用索引拼接。
- lsuffix 和 rsuffix:类似 merge() 中的后缀。
- sort:对生成后的 DataFrame 进行排序。
join 举例
people_new.join(country, lsuffix="left", rsuffix="right")

仅仅是index的横向拼接。
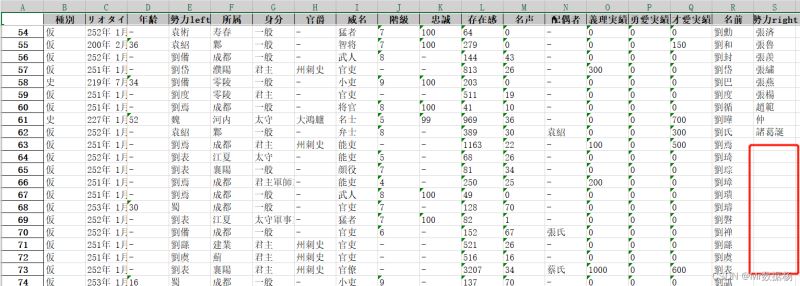
concat 操作
concat 操作起来就比较灵活,可以进行横向的拼接操作,也可以进行纵向的拼接操作。
纵向拼接操作
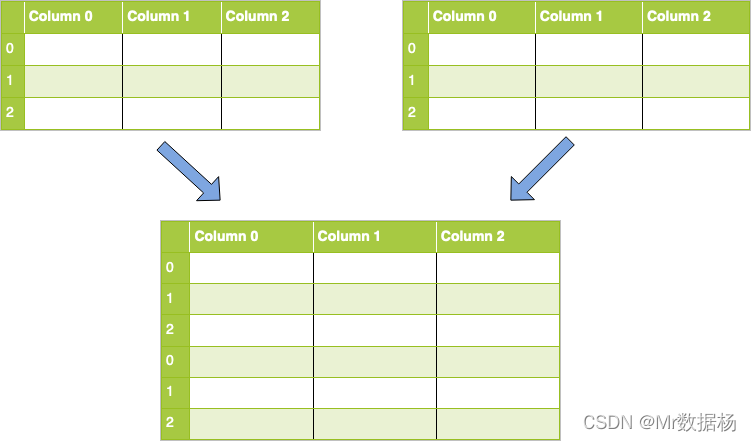
横拼接操作
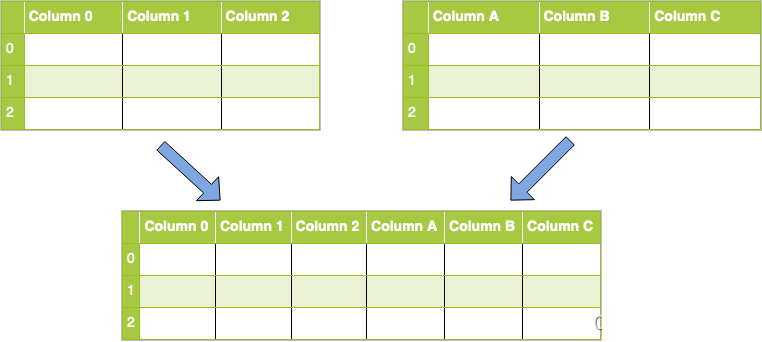
concat 中参数解释:
- objs:要连接的任何数据对象。可以是List,Serices,DataFrame,Dict 等等。
- axis:连接的轴。默认值为0(行轴),1(纵直)连接。
- join:类似于 merger 中的 how 参数,只接受值 inner 或 outer 。
- ignore_index:默认为False。True 为设置新的组合数据集将不会保留 axis 参数中指定的轴中的原始索引值。
- keys:构建分层索引,用于查询不同的行来自的原始数据集。
- copy:是否要复制源数据,默认值为True。
concat 举例
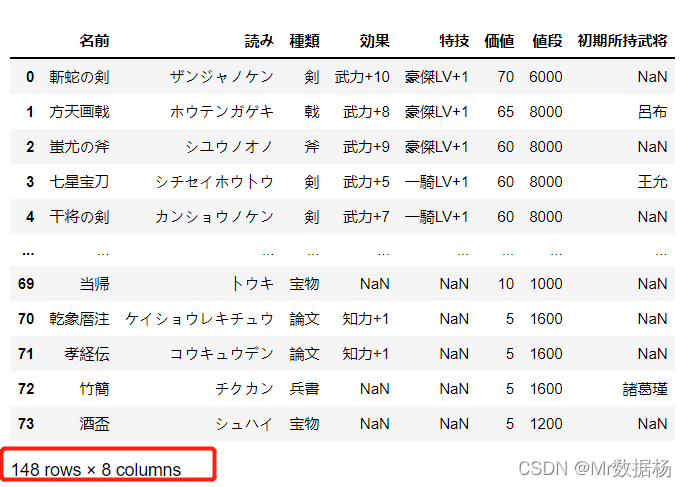
我们使用三国的宝物数据来观察,数据 74 行。
import pandas as pd
items = pd.read_excel("Romance of the Three Kingdoms 13/道具列表.xlsx")
items.head()

横向拼接后,保持数据最大行数 74。
pd.concat([items, items], axis=1)

纵向拼接后,最大行数变成 74 的 2倍。
pd.concat([items, items], axis=0)
append 举例
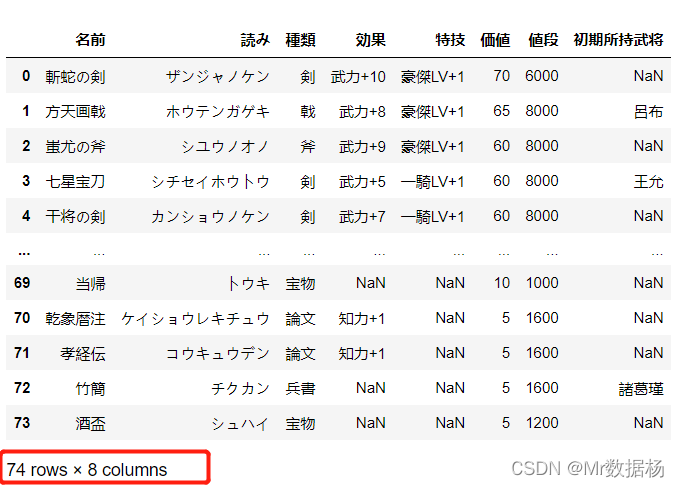
append 也是 DataFrame 数据进行拼接的有效方式,方式同 concat 的纵向拼接,返回的结果需要对变量重新定义才能生效。
注意下面2个 append 行数的区别
items.append(items) items
items = items.append(items) items
到此这篇关于Pandas实现数据拼接的操作方法详解的文章就介绍到这了,更多相关Pandas数据拼接内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
pandas数据的合并与拼接的实现
目录 1. Merge方法 1.1 内连接 1.2 外连接 1.3 左连接 1.4 右连接 1.5 基于多列的连接算法 1.6 基于index的连接方法 2. join方法 3. concat方法 3.1 series类型的拼接方法 3.2 dataframe类型的拼接方法 4. 小结 Pandas包的merge.join.concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat
-
pandas数据拼接的实现示例
一 前言 pandas数据拼接有可能会用到,比如出现重复数据,需要合并两份数据的交集,并集就是个不错的选择,知识追寻者本着技多不压身的态度蛮学习了一下下: 二 数据拼接 在进行学习数据转换之前,先学习一些数拼接相关的知识 2.1 join()联结 有关merge操作知识追寻者这边不提及,有空可能后面会专门出一篇相关文章,因为其学习方式根SQL的表联结类似,不是几行能说清楚的知识点: join操作能将 2 个DataFrame 合并为一块,前提是DataFrame 之间的列没有重复: # -*-
-
使用pandas读取表格数据并进行单行数据拼接的详细教程
业务需求 一个几十万条数据的Excel表格,现在需要拼接其中某一列的全部数据为一个字符串,例如下面简短的几行表格数据: id code price num 11 22 33 44 22 33 44 55 33 44 55 66 44 55 66 77 55 66 77 88 66 77 88 99 现在需要将code的这一列用逗号,拼接为字符串,并且每个单元格数据都用单引号包含,需要拼接成字符串'22','33','44','55','66','77',这样的情况,我们需要怎么处理呢?当然方式有
-
Pandas实现数据拼接的操作方法详解
目录 merge 操作 merge 拼接方式 merge 举例 join 操作 join 举例 concat 操作 concat 举例 append 举例 数据科学领域日常使用 Python 处理大规模数据集的时候经常需要使用到合并.链接的方式进行数据集的整合,其中应用的数据类型包括 Series 和 DataFrame,可以使用的方法也很多,比如本文中介绍的 .merge(). .join() 和 .concat() 三种方法,进行拼接处理后的数据集可以发挥最大的用途. merge 操作 .m
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
Pandas数据结构中Series属性详解
目录 Series属性 Series属性列表 Series属性详解 Series属性 Series属性列表 属性 说明 Series.index 系列的索引(轴标签) Series.array 系列或索引的数据 Series.values 系列的数据,返回ndarray Series.dtype 返回基础数据的数据类型 Series.shape 返回基础数据形状的元组 Series.nbytes 返回基础数据占的字节数 Series.ndim 基础数据的维数,永远是1 Series.size 返
-
django基础之数据库操作方法(详解)
Django 自称是"最适合开发有限期的完美WEB框架".本文参考<Django web开发指南>,快速搭建一个blog 出来,在中间涉及诸多知识点,这里不会详细说明,如果你是第一次接触Django ,本文会让你在感性上对Django有个认识,完成本文操作后会让你有兴趣阅读的相关书籍和文档. 本文客操作的环境,如无特别说明,后续都以下面的环境为基础: =================== Windows 7/10 python 3.5 Django 1.10 ======
-
PHP 数组基本操作方法详解
数组的概念 数组(array)是 PHP 中一个非常重要的概念,我们可以把数组看做一系列类似的数据的集合,实际上数组是一个有序图. PHP 还提供了超过 70 个内建函数来操作数组. 创建数组 使用 array() 语言结构创建数组: <?php $arr_age1 = array(18, 20, 25); // 或者: $arr_age2 = array("wang"=>18, "li"=>20, "zhang"=>25
-
对python pandas 画移动平均线的方法详解
数据文件 66001_.txt 内容格式: date,jz0,jz1,jz2,jz3,jz4,jz5 2012-12-28,0.9326,0.8835,1.0289,1.0027,1.1067,1.0023 2012-12-31,0.9435,0.8945,1.0435,1.0031,1.1229,1.0027 2013-01-04,0.9403,0.8898,1.0385,1.0032,1.1183,1.0030 ... ... pd_roll_mean1.py # -*- coding: u
-
python选取特定列 pandas iloc,loc,icol的使用详解(列切片及行切片)
df是一个dataframe,列名为A B C D 具体值如下: A B C D 0 ss 小红 8 1 aa 小明 d 4 f f 6 ak 小紫 7 dataframe里的属性是不定的,空值默认为NA. 一.选取标签为A和C的列,并且选完类型还是dataframe df = df.loc[:, ['A', 'C']] df = df.iloc[:, [0, 2]] 二.选取标签为C并且只取前两行,选完类型还是dataframe df = df.loc[0:2, ['A', 'C']] df
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
对pandas中Series的map函数详解
Series的map方法可以接受一个函数或含有映射关系的字典型对象. 使用map是一种实现元素级转换以及其他数据清理工作的便捷方式. (DataFrame中对应的是applymap()函数,当然DataFrame还有apply()函数) 1.字典映射 import pandas as pd from pandas import Series, DataFrame data = DataFrame({'food':['bacon','pulled pork','bacon','Pastrami',
-
Pandas时间序列:时期(period)及其算术运算详解
import pandas as pd import numpy as np 一.时间类型及其在python中对应的类型 时间戳–timestamp 时间间隔–timedelta 时期–period 二.时期 时期表示的是时间区间,比如数日.数月.数季.数年等 1.定义一个Period p = pd.Period(2007,freq='A-DEC') #表示以12月作为结束的一整年,这里表示从2007-01-01到2017-12-31的全年 p Period('2007', 'A-DEC') 2