Go语言学习之链表的使用详解
目录
- 1. 什么是链表
- 2. 单项链表的基本操作
- 3. 使用 struct 定义单链表
- 4. 尾部添加节点
- 5. 头部插入节点
- 6. 指定节点后添加新节点
- 7. 删除节点
1. 什么是链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
使用链表结构可以避免在使用数组时需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
链表允许插入和移除表上任意位置上的结点,但是不允许随机存取。
链表有三种类型:单向链表、双向链表、循环链表。
2. 单项链表的基本操作
单向链表中每个结点包含两部分,分别是数据域和指针域,上一个结点的指针指向下一结点,依次相连,形成链表。
链表通过指针将一组零散的内存块串联在一起,这里的内存块称为链表的结点。为了将这些节点给串起来,每个链表的结点除了存储数据之外,还会记录下一个结点的指针(即下一个结点的地址),这个指针称为:后继指针

3. 使用 struct 定义单链表
利用 Struct 可以包容多种数据类型的特性
一个结构体内可以包含若干成员,这些成员可以是基本类型、自定义类型、数组类型,也可以是指针类型。
struct 定义的三种形式,其中2和3都是返回结构体的指针
//定义
var stu Student
var stu *Student = new(Student)
var stu *Student = &Student {}
//调用
stu.Name stu.Age stu.Score
或
(*stu).Name (*stu).Age (*stu).Score
定义一个单项链表
next 是指针类型的属性,指向 Student struct 类型数据,也就是下一个节点的数据类型
type Student struct {
Name string
Age int
Score float32
next *Student
}
为链表赋值,并遍历链表中的每个节点
package main
import "fmt"
type Student struct {
Name string
Age int
Score float32
next *Student //存放下一个结构体的地址,用*直接指向下一个结构体
}
func main() {
//头部结构体
var head Student
head.Name = "张三"
head.Age = 28
head.Score = 88
//第二个结构体节点
var stu1 Student
stu1.Name = "李四"
stu1.Age = 25
stu1.Score = 100
head.next = &stu1
//第三个结构体节点
var stu2 Student
stu2.Name = "王五"
stu2.Age = 18
stu2.Score = 60
stu1.next = &stu2
Req(&head)
}
func Req(tmp *Student) { //tmp指针是指向下一个结构体的地址,加*就是下一个结构体
for tmp != nil { //遍历输出链表中每个结构体,判断是否为空
fmt.Println(*tmp)
tmp = tmp.next //tmp变更为下一个结构体地址
}
}
//输出结果如下
{张三 28 88 0xc000114480}
{李四 25 100 0xc0001144b0}
{王五 18 60 <nil>}
4. 尾部添加节点
方法一
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head Student
head.Name = "head"
head.Age = 28
head.Score = 88
//第二个结构体节点
var stu1 Student
stu1.Name = "stu1"
stu1.Age = 25
stu1.Score = 100
head.next = &stu1 //头部指向第一个结构体
//第三个结构体节点
var stu2 Student
stu2.Name = "stu2"
stu2.Age = 18
stu2.Score = 60
stu1.next = &stu2 //第一个结构体指向第二个结构体
//第四个结构体节点
var stu3 Student
stu3.Name = "stu3"
stu3.Age = 18
stu3.Score = 80
stu2.next = &stu3 //第二个结构体指向第三个结构体
//声明变量
var tail = &stu3
for i := 4; i < 10; i++ {
//定义节点
var stu Student = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//生产结构体串联
tail.next = &stu
tail = &stu
}
Req(&head)
}
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
//输出结果如下
{head 28 88 0xc0001144b0}
{stu1 25 100 0xc0001144e0}
{stu2 18 60 0xc000114510}
{stu3 18 80 0xc000114540}
{stu4 81 94.05091 0xc000114570}
{stu5 47 43.77142 0xc0001145a0}
{stu6 81 68.682304 0xc0001145d0}
{stu7 25 15.651925 0xc000114600}
{stu8 56 30.091187 0xc000114630}
{stu9 94 81.36399 <nil>}
方法二,使用函数进行优化
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head Student
head.Name = "head"
head.Age = 28
head.Score = 88
TailInsert(&head)
Req(&head)
}
//循环遍历
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
//添加结构体节点
func TailInsert(tail *Student) {
for i := 0; i < 10; i++ {
//定义节点
var stu Student = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//生产结构体串联
tail.next = &stu //指向下一个结构体
tail = &stu //把当前的结构体给tail,让其继续循环
}
}
//输出结果如下
{head 28 88 0xc0001144b0}
{stu0 81 94.05091 0xc0001144e0}
{stu1 47 43.77142 0xc000114510}
{stu2 81 68.682304 0xc000114540}
{stu3 25 15.651925 0xc000114570}
{stu4 56 30.091187 0xc0001145a0}
{stu5 94 81.36399 0xc0001145d0}
{stu6 62 38.06572 0xc000114600}
{stu7 28 46.888985 0xc000114630}
{stu8 11 29.310184 0xc000114660}
{stu9 37 21.855305 <nil>}
5. 头部插入节点
方法一
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head Student
head.Name = "head"
head.Age = 28
head.Score = 88
//调用头部插入函数
HeadInsert(&head)
Req(HeadInsert(&head))
}
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
func HeadInsert(p *Student) *Student {
for i := 0; i < 10; i++ {
var stu = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//当前新节点指向head,因为head是下一个节点
stu.next = p //指向下一个节点
p = &stu //把当前的结构体给tail,让其继续循环
}
return p
}
//输出结果如下
{stu9 85 30.152267 0xc000094840}
{stu8 37 5.912065 0xc000094810}
{stu7 29 7.9453626 0xc0000947e0}
{stu6 87 60.72534 0xc0000947b0}
{stu5 41 2.8303082 0xc000094780}
{stu4 90 69.67192 0xc000094750}
{stu3 87 20.658266 0xc000094720}
{stu2 47 29.708258 0xc0000946f0}
{stu1 28 86.249146 0xc0000946c0}
{stu0 95 36.08714 0xc0000944b0}
{head 28 88 <nil>}
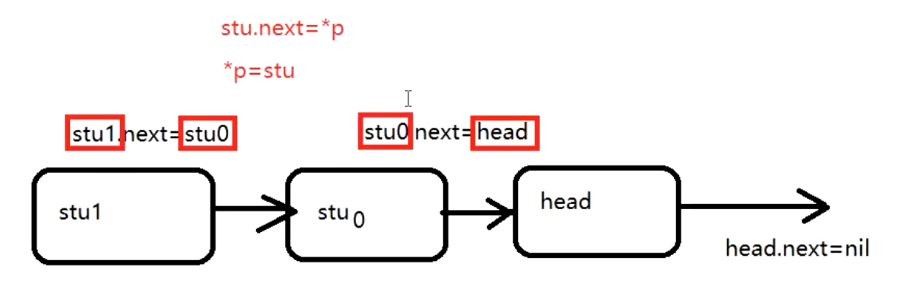
方法二
使用指针的指针
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head *Student = &Student{}
head.Name = "head"
head.Age = 28
head.Score = 88
//调用头部插入函数
HeadInsert(&head)
Req(head)
}
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
func HeadInsert(p **Student) {
for i := 0; i < 10; i++ {
var stu = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//当前新节点指向head,因为head是下一个节点
stu.next = *p //指向下一个节点
*p = &stu //把当前的结构体给tail,让其继续循环
}
}
//输出结果如下
{stu9 37 21.855305 0xc000114660}
{stu8 11 29.310184 0xc000114630}
{stu7 28 46.888985 0xc000114600}
{stu6 62 38.06572 0xc0001145d0}
{stu5 94 81.36399 0xc0001145a0}
{stu4 56 30.091187 0xc000114570}
{stu3 25 15.651925 0xc000114540}
{stu2 81 68.682304 0xc000114510}
{stu1 47 43.77142 0xc0001144e0}
{stu0 81 94.05091 0xc0001144b0}
{head 28 88 <nil>}
总结
如果想要外部的数据和函数处理结果进行同步,两种方法:
① 传参,传递指针
② return 进行值的返回
6. 指定节点后添加新节点
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head *Student = &Student{} //定义指针类型
head.Name = "head"
head.Age = 28
head.Score = 88
//定义新的节点
var newNode *Student = &Student{} //定义指针类型
newNode.Name = "newNode"
newNode.Age = 19
newNode.Score = 78
HeadInsert(&head)
//指定位置插入函数
Add(head, newNode)
Req(head)
}
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
func HeadInsert(p **Student) { //传入指针的指针
for i := 0; i < 10; i++ {
var stu = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//当前新节点指向head,因为head是下一个节点
stu.next = *p //指向下一个节点
*p = &stu //把当前的结构体给tail,让其继续循环
}
}
//p为当前节点,newnode为插入的节点
func Add(p *Student, newNode *Student) {
for p != nil {
if p.Name == "stu6" {
//对接下一个节点
newNode.next = p.next
p.next = newNode
}
//插入节点指向下一个节点
p = p.next //p.next赋予给p,继续进行循环遍历
}
}
//输出结果如下
{stu9 37 21.855305 0xc0000c0660}
{stu8 11 29.310184 0xc0000c0630}
{stu7 28 46.888985 0xc0000c0600}
{stu6 62 38.06572 0xc0000c04b0}
{newNode 19 78 0xc0000c05d0}
{stu5 94 81.36399 0xc0000c05a0}
{stu4 56 30.091187 0xc0000c0570}
{stu3 25 15.651925 0xc0000c0540}
{stu2 81 68.682304 0xc0000c0510}
{stu1 47 43.77142 0xc0000c04e0}
{stu0 81 94.05091 0xc0000c0480}
{head 28 88 <nil>}
7. 删除节点
package main
import (
"fmt"
"math/rand"
)
type Student struct {
Name string
Age int
Score float32
next *Student
}
func main() {
//头部结构体
var head *Student = &Student{} //定义指针类型
head.Name = "head"
head.Age = 28
head.Score = 88
//定义新的节点
var newNode *Student = &Student{} //定义指针类型
newNode.Name = "newNode"
newNode.Age = 19
newNode.Score = 78
HeadInsert(&head)
//指定位置插入函数
Add(head, newNode)
//删除节点
del(head)
Req(head)
}
func Req(tmp *Student) {
for tmp != nil {
fmt.Println(*tmp)
tmp = tmp.next
}
}
func HeadInsert(p **Student) { //传入指针的指针
for i := 0; i < 10; i++ {
var stu = Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//当前新节点指向head,因为head是下一个节点
stu.next = *p //指向下一个节点
*p = &stu //把当前的结构体给tail,让其继续循环
}
}
//p为当前节点,newnode为插入的节点
func Add(p *Student, newNode *Student) {
for p != nil {
if p.Name == "stu6" {
//对接下一个节点
newNode.next = p.next
p.next = newNode
}
//插入节点指向下一个节点
p = p.next //p.next赋予给p,继续进行循环遍历
}
}
//删除节点
func del(p *Student) {
var prev *Student = p //p=head prev=head ——》prev=p
for p != nil {
if p.Name == "newNode" {
prev.next = p.next
break
}
prev = p //进行平移,前节点赋值
p = p.next //后节点赋值
}
}
//输出结果如下
{stu9 37 21.855305 0xc0000c0660}
{stu8 11 29.310184 0xc0000c0630}
{stu7 28 46.888985 0xc0000c0600}
{stu6 62 38.06572 0xc0000c05d0}
{stu5 94 81.36399 0xc0000c05a0}
{stu4 56 30.091187 0xc0000c0570}
{stu3 25 15.651925 0xc0000c0540}
{stu2 81 68.682304 0xc0000c0510}
{stu1 47 43.77142 0xc0000c04e0}
{stu0 81 94.05091 0xc0000c0480}
{head 28 88 <nil>}
以上就是Go语言学习之链表的使用详解的详细内容,更多关于Go语言链表的资料请关注我们其它相关文章!
相关推荐
-
python/golang实现循环链表的示例代码
循环链表就是将单链表的末尾指向其头部,形成一个环.循环链表的增删操作和单链表的增删操作 区别不大.只是增加时,需要考虑空链表增加第一个节点的特殊情况:删除时需考虑删除节点是头/尾节点,和链表中只有一个节点的特殊情况. golang实现: type Node struct { value int next *Node } type Circle struct { tail *Node lenth int } // 增加节点: func (c *Circle) add(value int) { ne
-
Go实现双向链表的示例代码
本文介绍什么是链表,常见的链表有哪些,然后介绍链表这种数据结构会在哪些地方可以用到,以及 Redis 队列是底层的实现,通过一个小实例来演示 Redis 队列有哪些功能,最后通过 Go 实现一个双向链表. 目录 1.链表 1.1 说明 1.2 单向链表 1.3 循环链表 1.4 双向链表 2.redis队列 2.1 说明 2.2 应用场景 2.3 演示 3.Go双向链表 3.1 说明 3.2 实现 4.总结 5.参考文献 1.链表 1.1 说明 链表(Linked list)是一种常见的基础数据
-

go实现反转链表
反转链表首先讨论特殊节点 如果节点在首位,则反转之后,首位节点的next值为nil. func reverse(head *ListNode) *ListNode { bnode := head//设置默认遍历的前节点,为head temp := head.Next//从head.next节点开始遍历链表 flage := 0//设置一个标记,用于判断是否为第一个节点 var lnext *ListNode//用于临时保存下一个节点 for temp != nil {//遍历当 lnext =
-
golang双链表的实现代码示例
双链表的实现 基本概念 每一个节点都存储上一个和下一个节点的指针 实现思路 创建一个节点结构体 每个节点都有上节点指针与下节点指针 每个节点都有一个key => value 创建一个链表结构体 链表容量大小属性 链表大小属性 链表锁, 实现并发安全 链表头节点 链表尾节点 实现链表操作方法 添加头部节点操作AppendHead 添加尾部节点操作AppendTail 追加尾部节点操作Append 插入任意节点操作Insert 删除任意节点操作Remove 删除头部节点操作RemoveHead 删除
-
python/golang 删除链表中的元素
先用使用常规方法,两个指针: golang实现: type Node struct { value int next *Node } type Link struct { head *Node tail *Node lenth int } // 向链表中添加元素 func (link *Link) add(v int) { if link.lenth == 0 { // 当前链表是空链表 link.head = &Node{v, nil} link.tail = link.head link.l
-
Go语言单链表实现方法
本文实例讲述了Go语言单链表实现方法.分享给大家供大家参考.具体如下: 1. singlechain.go代码如下: 复制代码 代码如下: ////////// //单链表 -- 线性表 package singlechain //定义节点 type Node struct { Data int Next *Node } /* * 返回第一个节点 * h 头结点 */ func GetFirst(h *Node) *Node { if h.Next == nil {
-
详解go语言单链表及其常用方法的实现
目的 在刷算法题中经常遇到关于链表的操作,在使用go语言去操作链表时不熟悉其实现原理,目的是为了重温链表这一基础且关键的数据结构. 1.链表的特点和初始化 1.1.链表的特点 用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的) 1.2.结点 结点(node) 数据域 => 存储元素信息 指针域 => 存储结点的直接后继,也称作指针或链 首元结点 是指链表中存储的第一个数据元素的结点 头结点 是在首元结点之前附设的一个结点,其指针域指向首元结点(非必须) 头指
-
Go语言学习之链表的使用详解
目录 1. 什么是链表 2. 单项链表的基本操作 3. 使用 struct 定义单链表 4. 尾部添加节点 5. 头部插入节点 6. 指定节点后添加新节点 7. 删除节点 1. 什么是链表 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的. 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域. 使用链表结构可以避免在使用数组时需要预先知
-
R语言学习笔记之lm函数详解
在使用lm函数做一元线性回归时,发现lm(y~x+1)和lm(y~x)的结果是一致的,一直没找到两者之间的区别,经过大神们的讨论和测试,才发现其中的差别,测试如下: ------------------------------------------------------------- ------------------------------------------------------------- 结果可以发现,两者的结果是一样的,并无区别,但是若改为lm(y~x-1)就能看出+1和
-
Go语言学习之数组的用法详解
目录 引言 一.数组的定义 1. 语法 2. 示例 二.数组的初始化 1. 未初始化的数组 2. 使用初始化列表 3. 省略数组长度 4. 指定索引值的方式来初始化 5. 访问数组元素 6. 根据数组长度遍历数组 三. 访问数组元素 1. 访问数组元素 2. 根据数组长度遍历数组 四.冒泡排序 五.多维数组 1. 二维数组 2. 初始化二维数组 3. 访问二维数组 六.向函数传递数组 1. 形参设定数组大小 2. 形参未设定数组大小 3. 示例 总结 引言 数组是相同数据类型的一组数据的集合,数
-
Go语言学习之条件语句使用详解
目录 1.if...else判断语法 2.if嵌套语法 3.switch语句 4.类型switch语句 5.fallthrough关键字使用 小结 1.if...else判断语法 语法的使用和其他语言没啥区别. 样例代码如下: // 判断语句 func panduan(a int) { if a > 50 { fmt.Println("a > 50") } else if a < 30 { fmt.Println("a < 30") } el
-
Go语言学习之反射的用法详解
目录 1. reflect 包 1.1 获取变量类型 1.2 断言处理类型转换 2. ValueOf 2.1 获取变量值 2.2 类型转换 3. Value.Set 3.1 设置变量值 3.2 示例 4. 结构体反射 4.1 查看结构体字段数量和方法数量 4.2 获取结构体属性 4.3 更改属性值 4.4 Tag原信息处理 5. 函数反射 6. 方法反射 6.1 使用 MethodByName 名称调用方法 6.2 使用 method 索引调用方法 反射指的是运行时动态的获取变量的相关信息 1.
-
Go语言学习之循环语句使用详解
目录 1.for循环 2.for-each语法 3.break的使用 4.continue的使用 5.goto的使用 1.for循环 写法基本和其他语言一致,只是没有了while循环,用for代替while. 样例代码如下 // for循环 func loop1() { sum := 0 for i := 0; i < 100; i++ { sum += i } fmt.Printf("sum = %d\n", sum) // 和while循环一样 sum1 := 3 for s
-
Go语言学习之时间函数使用详解
目录 引言 1. 时间格式化 2. 示例 引言 1946年2月14日,人类历史上公认的第一台现代电子计算机“埃尼阿克”(ENIAC)诞生. 计算机语言时间戳是以1970年1月1日0点为计时起点时间的.计算机诞生为1946年2月14日,而赋予生命力时间是从1970年1月1日0点开始. Hour 1小时=60分钟 Minute 1分钟=60秒 Second 1秒=1000毫秒 Millsecond 1毫秒=1000微秒 Microsecond 1微秒=1000纳秒 Nanoseco 1纳秒 1. 时
-
Go语言学习之指针的用法详解
目录 引言 一.定义结构体 1. 语法格式 2. 示例 二.访问结构体成员 三.结构体作为函数参数 四.结构体指针 总结 引言 Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型 结构体是由一系列具有相同类型或不同类型的数据构成的数据集合 结构体表示一项记录,比如保存图书馆的书籍记录,每本书有以下属性: Title :标题 Author : 作者 Subject:学科 ID:书籍ID 一.定义结构体 1. 语法格式 结构体定义需要使用 type 和 struc
-
C语言学习进阶篇之万字详解指针与qsort函数
目录 前言 函数指针 代码一 代码二 函数指针数组 函数指针数组的用途 计算器的基本代码 函数指针实现简单的计算机 函数指针数组实现简单计算机 指向函数指针数组的指针 回调函数 简单的冒泡排序 冒泡排序的优化 qsort函数 qsort函数介绍 qsort实现冒泡排序 qsort排序结构数据 模拟实现qsort函数 写在最后 前言 前面学到了字符指针,指针数组是一个存储指针的数组,数组指针是一个指向函数的指针,数组参数和指针参数.其中不乏有很多需要注意的知识点,例如:&数组名和数组名表示的含义,
-
C语言学习之关键字的示例详解
目录 1. 前言 2. 什么是关键字 3. extern-声明外部符号 4. auto-自动 5. typedef-类型重定义(类型重命名) 6. register-寄存器 6.1 存储器 6.2 register关键字的作用 7. static-静态 7.1 static修饰局部变量 7.2 static修饰全局变量 7.3 static修饰函数 1. 前言 大家好,我是努力学习游泳的鱼.关键字,这名字一听,就很关键.而有些关键字,你可能不是很了解,更别谈使用.所以,这篇文章将带你见识常见的关