Mysql树形结构的数据库表设计方案
目录
- 前言
- 一、基本数据
- 二、继承关系驱动的设计
- 三、基于左右值编码的设计
- 四、树形结构CRUD算法
- (1)获取某节点的子孙节点
- (2)获取某节点的族谱路径
- (3)为某节点添加子孙节点
- (4)删除某节点
- 五、总结
- 参考文献
前言
最近研究树形菜单网上找了很多例子看了。一下是网上找的一些资料,然后自己重新实践,记录下免得下次又忘记了。
程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化。然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将Tree存入DBMS,设计合适的Schema及其对应的CRUD算法是实现关系型数据库中存储树形结构的关键。
理想中树形结构应该具备如下特征:数据存储冗余度小、直观性强;检索遍历过程简单高效;节点增删改查CRUD操作高效。无意中在网上搜索到一种很巧妙的设计,原文是英文,看过后感觉有点意思,于是便整理了一下。本文将介绍两种树形结构的Schema设计方案:一种是直观而简单的设计思路,另一种是基于左右值编码的改进方案。
一、基本数据
本文列举了一个食品族谱的例子进行讲解,通过类别、颜色和品种组织食品,树形结构图如下:
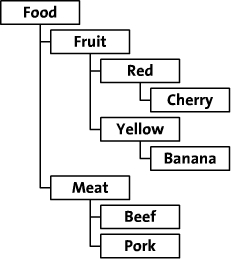
二、继承关系驱动的设计
对树形结构最直观的分析莫过于节点之间的继承关系上,通过显示地描述某一节点的父节点,从而能够建立二维的关系表,则这种方案的Tree表结构通常设计为:{Node_id,Parent_id},上述数据可以描述为如下图所示:

这种方案的优点很明显:设计和实现自然而然,非常直观和方便。缺点当然也是非 常的突出:由于直接地记录了节点之间的继承关系,因此对Tree的任何CRUD操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。当然,这种方案并非没有用武之地,在Tree规模相对较小的情况下,我们可以借助于缓存机制来做优化,将Tree的信息载入内存进行处理,避免直接对数据库IO操作的性能开销。
三、基于左右值编码的设计
在基于数据库的一般应用中,查询的需求总要大于删除和修改。为了避免对于树形结构查询时的“递归”过程,基于Tree的前序遍历设计一种全新的无递归查询、无限分组的左右值编码方案,来保存该树的数据。

第一次看见这种表结构,相信大部分人都不清楚左值(Lft)和右值(Rgt)是如何计算出来的,而且这种表设计似乎并没有保存父子节点的继承关系。但当你用手指指着表中的数字从1数到18,你应该会发现点什么吧。对,你手指移动的顺序就是对这棵树进行前序遍历的顺序,如下图所示。当我们从根节点Food左侧开始,标记为1,并沿前序遍历的方向,依次在遍历的路径上标注数字,最后我们回到了根节点Food,并在右边写上了18。

依据此设计,我们可以推断出所有左值大于2,并且右值小于11的节点都是Fruit的后续节点,整棵树的结构通过左值和右值存储了下来。然而,这还不够,我们的目的是能够对树进行CRUD操作,即需要构造出与之配套的相关算法。
四、树形结构CRUD算法
(1)获取某节点的子孙节点
只需要一条SQL语句,即可返回该节点子孙节点的前序遍历列表,以Fruit为例:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC
查询结果如下所示:

那么某个节点到底有多少的子孙节点呢?通过该节点的左、右值我们可以将其子孙节点圈进来,则子孙总数 = (右值 – 左值– 1) / 2,以Fruit为例,其子孙总数为:(11 –2 – 1) / 2 = 4。同时,为了更为直观地展现树形结构,我们需要知道节点在树中所处的层次,通过左、右值的SQL查询即可实现,以Fruit为例:SELECTCOUNT(*) FROM tree WHERE lft <= 2 AND rgt >=11。为了方便描述,我们可以为Tree建立一个视图,添加一个层次数列,该列数值可以写一个自定义函数来计算,函数定义如下:
创建表
CREATE TABLE `tree` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `lft` int(255) DEFAULT NULL, `rgt` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('1', 'Food', '1', '18');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('2', 'Fruit', '2', '11');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('3', 'Red', '3', '6');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('4', 'Cherry', '4', '5');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('5', 'Yellow', '7', '10');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('6', 'Banana', '8', '9');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('7', 'Meat', '12', '17');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('8', 'Beef', '13', '14');
INSERT INTO `jpa`.`tree` (`id`, `name`, `lft`, `rgt`) VALUES ('9', 'Pork', '15', '16');
CREATE VIEW `treeview` AS SELECT `a`.`id` AS `id`, `a`.`name` AS `name`, `a`.`lft` AS `lft`, `a`.`rgt` AS `rgt`, `CountLayer` (`a`.`id`) AS `layer` FROM `tree` `a`
基于层次计算函数,我们创建一个视图,添加了新的记录节点层次的数列:
> CREATE FUNCTION `CountLayer` (`node_id` INT) RETURNS INT (11)
BEGIN
DECLARE result INT (10) DEFAULT 0 ;
DECLARE lftid INT;
DECLARE rgtid INT;
SELECT lft,rgt INTO lftid, rgtid FROM tree WHERE id = node_id;
SELECT COUNT(*) INTO result FROM tree WHERE lft <= lftid AND rgt >= rgtid;
RETURN (result);
END
创建存储过程,用于计算给定节点的所有子孙节点及相应的层次:
CREATE PROCEDURE `GetChildrenNodeList`(IN `node_id` INT) BEGIN DECLARE lftid INT; DECLARE rgtid INT; SELECT lft,rgt INTO lftid,rgtid FROM tree WHERE id= node_id; SELECT * FROM treeview WHERE lft BETWEEN lftid AND rgtid ORDER BY lft ASC; END
现在,我们使用上面的存储过程来计算节点Fruit所有子孙节点及对应层次,查询结果如下:

从上面的实现中,我们可以看出采用左右值编码的设计方案,在进行树的查询遍历时,只需要进行2次数据库查询,消除了递归,再加上查询条件都是数字的比较,查询的效率是极高的,随着树规模的不断扩大,基于左右值编码的设计方案将比传统的递归方案查询效率提高更多。当然,前面我们只给出了一个简单的获取节点子孙的算法,真正地使用这棵树我们需要实现插入、删除同层平移节点等功能。
(2)获取某节点的族谱路径
假定我们要获得某节点的族谱路径,则根据左、右值分析只需要一条SQL语句即可完成,以Fruit为例:SELECT* FROM tree WHERE lft < 2 AND rgt > 11 ORDER BY lft ASC ,相对完整的存储过程:
CREATE PROCEDURE `GetParentNodePath`(IN `node_id` INT) BEGIN DECLARE lftid INT; DECLARE rgtid INT; SELECT lft,rgt INTO lftid,rgtid FROM tree WHERE id= node_id; SELECT * FROM treeview WHERE lft < lftid AND rgt > rgtid ORDER BY lft ASC; END
(3)为某节点添加子孙节点
假定我们要在节点“Red”下添加一个新的子节点“Apple”,该树将变成如下图所示,其中红色节点为新增节点。

CREATE PROCEDURE `AddSubNode`(IN `node_id` INT,IN `node_name` VARCHAR(64))
BEGIN
DECLARE rgtid INT;
DECLARE t_error INT DEFAULT 0;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error=1; -- 出错处理
SELECT rgt INTO rgtid FROM tree WHERE id= node_id;
START TRANSACTION;
UPDATE tree SET rgt = rgt + 2 WHERE rgt >= rgtid;
UPDATE tree SET lft = lft + 2 WHERE lft >= rgtid;
INSERT INTO tree (NAME,lft,rgt) VALUES(node_name,rgtid,rgtid+1);
IF t_error =1 THEN
ROLLBACK;
ELSE
COMMIT;
END IF;
END
(4)删除某节点
如果我们想要删除某个节点,会同时删除该节点的所有子孙节点,而这些被删除的节点的个数为:(被删除节点的右值 – 被删除节点的左值+ 1) / 2,而剩下的节点左、右值在大于被删除节点左、右值的情况下会进行调整。来看看树会发生什么变化,以Beef为例,删除效果如下图所示。

则我们可以构造出相应的存储过程:
CREATE PROCEDURE `DelNode`(IN `node_id` INT)
BEGIN
DECLARE lftid INT;
DECLARE rgtid INT;
DECLARE t_error INT DEFAULT 0;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error=1; -- 出错处理
SELECT lft,rgt INTO lftid,rgtid FROM tree WHERE id= node_id;
START TRANSACTION;
DELETE FROM tree WHERE lft >= lftid AND rgt <= rgtid;
UPDATE tree SET lft = lft -(rgtid - lftid + 1) WHERE lft > lftid;
UPDATE tree SET rgt = rgt -(rgtid - lftid + 1) WHERE rgt >rgtid;
IF t_error =1 THEN
ROLLBACK;
ELSE
COMMIT;
END IF;
END
五、总结
我们可以对这种通过左右值编码实现无限分组的树形结构Schema设计方案做一个总结:
(1)优点:在消除了递归操作的前提下实现了无限分组,而且查询条件是基于整形数字的比较,效率很高。
(2)缺点:节点的添加、删除及修改代价较大,将会涉及到表中多方面数据的改动。
参考文献
https://www.jb51.net/article/223579.htm
相关推荐
-
Mysql通过Adjacency List(邻接表)存储树形结构
以下内容给大家介绍了MYSQL通过Adjacency List (邻接表)来存储树形结构的过程介绍和解决办法,并把存储后的图例做了分析. 今天来看看一个比较头疼的问题,如何在数据库中存储树形结构呢? 像mysql这样的关系型数据库,比较适合存储一些类似表格的扁平化数据,但是遇到像树形结构这样有深度的人,就很难驾驭了. 举个栗子:现在有一个要存储一下公司的人员结构,大致层次结构如下: (画个图真不容易..) 那么怎么存储这个结构?并且要获取以下信息: 1.查询小天的直接上司. 2.查询老宋管理下的
-

Mysql树形结构的数据库表设计方案
目录 前言 一.基本数据 二.继承关系驱动的设计 三.基于左右值编码的设计 四.树形结构CRUD算法 (1)获取某节点的子孙节点 (2)获取某节点的族谱路径 (3)为某节点添加子孙节点 (4)删除某节点 五.总结 参考文献 前言 最近研究树形菜单网上找了很多例子看了.一下是网上找的一些资料,然后自己重新实践,记录下免得下次又忘记了. 程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门.栏目结构.商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化.然而目前的各
-
浅谈mysql 树形结构表设计与优化
前言 在诸多的管理类,办公类等系统中,树形结构展示随处可见,以"部门"或"机构"来说,接触过的同学应该都知道,最终展示到页面的效果就是层级结构的那种,下图随机列举了一个部门的树型结构展示图 设计考虑因素 1.表结构设计 稍稍有点开发和表结构设计经验的同学,设计出这样一张表,应该很容易,只需要在depart表中,添加一个pid/字段即可满足要求,参考下表: CREATE TABLE `depart` ( `depart_id` varchar(32) NOT NULL
-
sqlserver 树形结构查询单表实例代码
--树形sql查询 WITH TREE AS( --创建一个虚拟表 SELECT * FROM sys_organiz --指定需要查询的表 WHERE organize_code = '100000' -- 指定父节点条件 UNION ALL --联合查询 SELECT sys_organiz.* FROM sys_organiz,TREE WHERE TREE.organize_code = sys_organiz.organize_parent_code ) SELECT * FROM T
-
浅谈MYSQL中树形结构表3种设计优劣分析与分享
目录 简介 问题 设计1:邻接表 表设计 SQL示例 设计2:路径枚举 表设计 SQL示例 设计3:闭包表 表设计 SQL示例 结合使用 表设计 总结 简介 在开发中经常遇到树形结构的场景,本文将以部门表为例对比几种设计的优缺点: 问题 需求背景:根据部门检索人员, 问题:选择一个顶级部门情况下,跨级展示当前部门以及子部门下的所有人员,表怎么设计更合理 ? 递归吗 ?递归可以解决,但是势必消耗性能 设计1:邻接表 注:(常见父Id设计) 表设计 CREATE TABLE `dept_info01
-
详细聊一聊mysql的树形结构存储以及查询
目录 序 存储parent 存储path MPTT(Modified Preorder Tree Traversal) 小结 doc 序 本文主要研究一下mysql的树形结构存储及查询 存储parent 这种方式就是每个节点存储自己的parent_id信息 建表及数据准备 CREATE TABLE `menu` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL, `parent_id` int(11) NOT
-
树形结构数据库表Schema设计的两种方案
目录 前言 一.基本数据 二.继承关系驱动的Schema设计 三.基于左右值编码的Schema设计 四.树形结构CRUD算法 (1)获取某节点的子孙节点 (2)获取某节点的族谱路径 (3)为某节点添加子孙节点 (4)删除某节点 五.总结 前言 程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门.栏目结构.商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化.然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将Tree存入DBMS
-
mysql如何比对两个数据库表结构的方法
在开发及调试的过程中,需要比对新旧代码的差异,我们可以使用git/svn等版本控制工具进行比对.而不同版本的数据库表结构也存在差异,我们同样需要比对差异及获取更新结构的sql语句. 例如同一套代码,在开发环境正常,在测试环境出现问题,这时除了检查服务器设置,还需要比对开发环境与测试环境的数据库表结构是否存在差异.找到差异后需要更新测试环境数据库表结构直到开发与测试环境的数据库表结构一致. 我们可以使用mysqldiff工具来实现比对数据库表结构及获取更新结构的sql语句. 1.mysqldiff
-
MYSQL数据库表结构优化方法详解
本文实例讲述了MYSQL数据库表结构优化方法.分享给大家供大家参考,具体如下: 选择合适的数据类型 1.使用可以存下你的数据的最小的数据类型 2.使用简单的数据类型.Int要比varchar类型在mysql处理上简单 3.尽可能的使用not null定义字段 4.尽量少用text类型,非用不可时最好考虑分表 使用int来存储日期时间,利用FROM_UNIXTIME()[将int类型时间戳转换成日期时间格式],UNIX_TIMESTAMP()[将日期时间格式转换成int类型]两个函数进行转换 使用
-
利用Python批量导出mysql数据库表结构的操作实例
目录 前言 解决方法 1. mysql 数据库 表信息查询 2.连接数据库代码 3.数据查询处理代码 3.0 配置信息 3.1查询数据库表 3.2 查询对应表结构 3.3 pandas进行数据保存导出excel 补充:python脚本快速生成mysql数据库结构文档 总结 前言 最近在公司售前售后同事遇到一些奇怪的需求找到我,需要提供公司一些项目数据库所有表的结构信息(字段名.类型.长度.是否主键.***.备注),虽然不是本职工作,但是作为python技能的拥有者看到这种需求还是觉得很容易的,但