高考要来啦!用Python爬取历年高考数据并分析
开发工具
**Python版本:**3.6.4
相关模块:
pyecharts模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
pyecharts模块的安装可参考:
Python简单分析微信好友
“一本正经的分析”
首先让我们来看看从恢复高考(1977年)开始高考报名、最终录取的总人数走势吧:
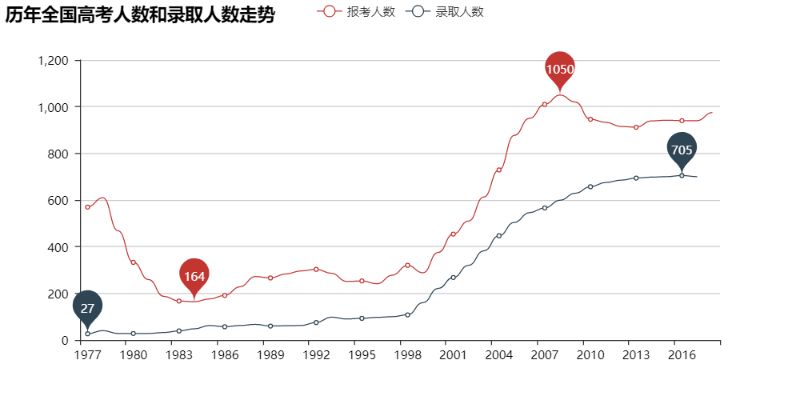
T_T看来学生党确实是越来越多了。
不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧:


看来上大学越来越“容易”之说不是空穴来风的,总录取比例高的可怕~~~
那么各省的情况呢?
由于各省高考最终录取人数的统计标准不一样,有些是只统计本科,有些是都统计的,为了避免统计标准不一而带来的不公平对比,我们只分析各省的高考报考人数。
那么985&211高校的分布又如何呢?
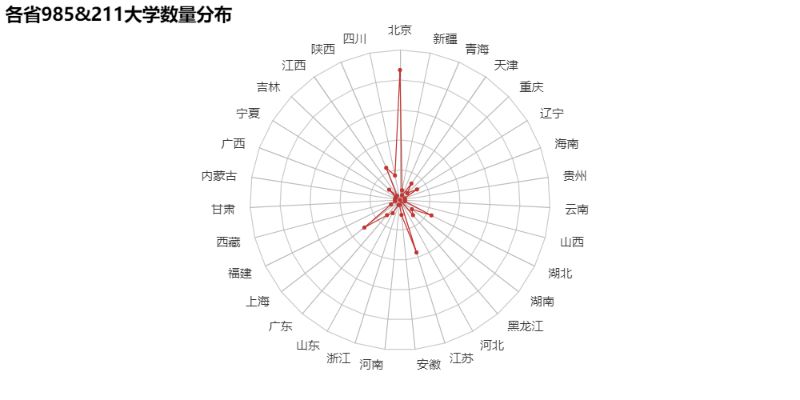
“那就这样吧,再爱都曲终人散了。”看到这个默默不说话了。
以省份为x轴,年份为y轴,该年该省报考的考生人数为z轴来更直观地看看各省每年的高考考生数量变化情况吧:

上图中省份的顺序是这样的:
北京、四川、陕西、江西、吉林、宁夏、广西、内蒙古、甘肃、西藏、福建、上海、广东、山东、浙江、河南、安徽、江苏、河北、黑龙江、湖南、湖北、山西、云南、贵州、海南、辽宁、重庆、天津、青海、新疆,台湾因为没有数据,所以没有加入。
T_T河南的高考考生数量真的恐怖。
Emmm,因为可用的数据不多,再分析下去大概就是花式的做图游戏了,想想还是算了吧。至于个人观点,还是不发表为好。毕竟,大家的“哈姆雷特”都不一样。
到此这篇关于Python数据分析之爬取历年高考数据并分析的文章就介绍到这了,更多相关Python爬取高考数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之pandas比较操作
一.比较运算符和比较方法 比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==.!=.<.>.<=.>=六个,Pandas中也一样. 在Pandas中,DataFrame和Series还支持6个比较方法,详见下表. 方法 英文全称 用途 eq equal to 等于 ne not equal to 不等于 lt less than 小于 gt greater than 大于 le less than or equal to 小于等于 ge greater than
-
python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
python学习之panda数据分析核心支持库
前言 Python是一门实现数据可视化很好的语言,他们里面的很多库可以很好的画出图形,形象明了. 今天我们就来说说:Pandas数据分析核心支持库 初识Pandas: Pandas 是 Python 语言的一个扩展程序库,用于数据分析. Pandas 是一个开放源码.BSD 许可的库,提供高性能.易于使用的数据结构和数据分析工具. Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
Python数据分析之绘图和可视化详解
一.前言 matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面).该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图.matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG
-
Python数据分析入门之教你怎么搭建环境
一.Anaconda Anaconda(水蟒)是一个捆绑了Python.conda.其他相关依赖包的一个软件.包含了180多个可学计算包及其依赖.Anaconda3是集成了Python3的环境,Anaconda2是集成了Python2的环境.Anaconda默认集成的包,是属于内置的Python的包.并且支持绝大部分操作系统(比如:Windows.Mac.Linux等).下载地址如下:https://www.anaconda.com/distribution/(如果官网下载太慢,可以在清华大学开
-
Python数据分析入门之数据读取与存储
一.图示 二.csv文件 1.读取csv文件read_csv(file_path or buf,usecols,encoding):file_path:文件路径,usecols:指定读取的列名,encoding:编码 data = pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8') data.head() name num 0 酥油茶 219.0 1 青稞酒 95.0 2 酸奶 62.0 3 糌粑 16.0 4 琵琶肉 2.0 #指
-
高考要来啦!用Python爬取历年高考数据并分析
开发工具 **Python版本:**3.6.4 相关模块: pyecharts模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. pyecharts模块的安装可参考: Python简单分析微信好友 "一本正经的分析" 首先让我们来看看从恢复高考(1977年)开始高考报名.最终录取的总人数走势吧: T_T看来学生党确实是越来越多了. 不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧: 看来上大学越来越
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
利用Python 爬取股票实时数据详情
东方财富网地址如下: http://quote.eastmoney.com/center/gridlist.html#hs_a_board 我们通过点击该网站的下一页发现,网页内容有变化,但是网站的 URL 却不变,也就是说这里使用了 Ajax 技术,动态从服务器拉取数据,这种方式的好处是可以在不重新加载整幅网页的情况下更新部分数据,减轻网络负荷,加快页面加载速度. 我们通过 F12 来查看网络请求情况,可以很容易的发现,网页上的数据都是通过如下地址请求的 http://38.push2.eas
-
用python爬取历史天气数据的方法示例
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进. 准备爬的历史天气 爬之前先分析url.左上有年份.月份的下拉选择框,按F12,进去看看能否找到真正的url: 很容易就找到了,左边是储存月度数据的js文件,右边是文件源代码,貌似json格式. 双击左边js文件,地址栏内出现了url:http://tianqi.数字.com/t/wea_history/js/54511_20161.js url中的"54511&qu
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
用Python爬取618当天某东热门商品销量数据,看看大家喜欢什么!
前言 本文结构如下: 1.爬取某东畅销商品数据 2.清洗数据并并进行简单分析 3.将数据进行可视化展示 数据的字段如下: 一共爬取了243条某东畅销商品数据 一.获取数据 1. 分析网页 在编写代码之前,先来分析一波网页. 上面是某东的畅销商品,通过辰哥分析分析,该网页有异步加载(前面10个商品是静态加载,剩下的是动态异步加载),因此我们需要写了个请求去获取数据. 2. 获取静态网页商品链接 商品的销售.评论等数据在商品详情页,这里先获取商品详情页链接 结果如下: 3. 获取动态网页商品链接 通
-
利用python爬取城市公交站点
目录 页面分析 爬虫 数据清洗 Excel PQ 数据清洗 python数据清洗 QGIS坐标纠偏 导入csv文件 坐标纠偏 总结 利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得到我们的公交站点以后,我们利用高德api来获取站点的经纬度坐标,利用pandas解析json文件.接下来开干,我推荐使用面向对象的方法来写代码. import requ