python scrapy项目下spiders内多个爬虫同时运行的实现
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做?
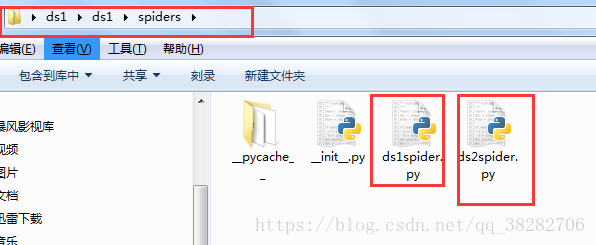
a、在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可!
import os
from scrapy.commands import ScrapyCommand
from scrapy.utils.conf import arglist_to_dict
from scrapy.utils.python import without_none_values
from scrapy.exceptions import UsageError
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] <spider>"
def short_desc(self):
return "Run all spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
#获取爬虫列表
spd_loader_list=self.crawler_process.spider_loader.list()#获取所有的爬虫文件。
print(spd_loader_list)
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print ('此时启动的爬虫为:'+spname)
self.crawler_process.start()
b、还得在里面加个_init_.py文件
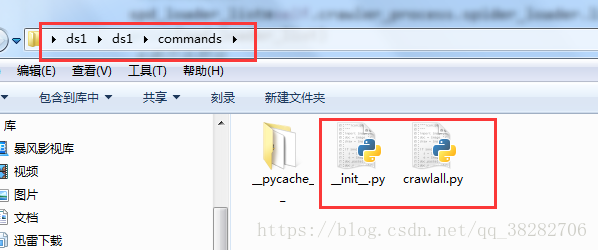
c、到这里还没完,settings.py配置文件还需要加一条。
COMMANDS_MODULE = ‘项目名称.目录名称'
COMMANDS_MODULE = 'ds1.commands'
d、最后启动crawlall即可!
当然,安全起见,可以先在命令行中进入该项目所在目录,并输入scrapy -h,可以查看是否有命令crawlall 。如果有,那就成功了,可以启动了
我是写了个启动文件,放在第一级即可
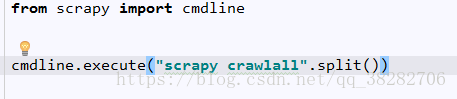
要不直接在命令台cmd里输入 scrapy crawlall 就行了
##注意的是,爬虫好像是2个同时运行,而且运行时是交叉的?
还有settings里的文件,只针对其中一个?
到此这篇关于python scrapy项目下spiders内多个爬虫同时运行的文章就介绍到这了,更多相关python scrapy项目下spiders内多个爬虫同时运行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Scrapy爬虫文件批量运行的实现
Scrapy批量运行爬虫文件的两种方法: 1.使用CrawProcess实现 https://doc.scrapy.org/en/latest/topics/practices.html 2.修改craw源码+自定义命令的方式实现 (1)我们打开scrapy.commands.crawl.py 文件可以看到: def run(self, args, opts): if len(args) < 1: raise UsageError() elif len(args) > 1: raise Usa
-

python scrapy项目下spiders内多个爬虫同时运行的实现
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做? a.在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可! import os from scrapy.commands import ScrapyCommand from scrapy.utils.conf import arglist
-
Python scrapy增量爬取实例及实现过程解析
这篇文章主要介绍了Python scrapy增量爬取实例及实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的文章,所以又把scrapy捡起来.趁着这次机会做一个记录. 目录如下: 环境 本地窗口调试命令 工程目录 xpath选择器 一个简单
-
python Scrapy框架原理解析
Python 爬虫包含两个重要的部分:正则表达式和Scrapy框架的运用, 正则表达式对于所有语言都是通用的,网络上可以找到各种资源. 如下是手绘Scrapy框架原理图,帮助理解 如下是一段运用Scrapy创建的spider:使用了内置的crawl模板,以利用Scrapy库的CrawlSpider.相对于简单的爬取爬虫来说,Scrapy的CrawlSpider拥有一些网络爬取时可用的特殊属性和方法: $ scrapy genspider country_or_district example.p
-
一文读懂python Scrapy爬虫框架
Scrapy是什么? 先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. S
-
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: import scrapy class UiSpider(scrapy.Spider): name = 'ui' allowed_domains = ['www.uisdc.com'] start_urls =
-
Python Scrapy实战之古诗文网的爬取
目录 需求 1. Scrapy项目创建 2. 全局配置 settings.py 3. 爬虫程序.py 4. 数据结构 items.py 5. 管道 pipelines.py 6. 程序执行 start.py 需求 通过python,Scrapy框架,爬取古诗文网上的诗词数据,具体包括诗词的标题信息,作者,朝代,诗词内容,及译文.爬取过程需要逐页爬取,共4页.第一页的url为(https://www.gushiwen.cn/default_1.aspx). 1. Scrapy项目创建 首先创建Sc
-
Python的爬虫框架scrapy用21行代码写一个爬虫
开发说明 开发环境:Pycharm 2017.1(目前最新) 开发框架:Scrapy 1.3.3(目前最新) 目标 爬取线报网站,并把内容保存到items.json里 页面分析 根据上图我们可以发现内容都在类为post这个div里 下面放出post的代码 <div class="post"> <!-- baidu_tc block_begin: {"action": "DELETE"} --> <div class=
-
python scrapy重复执行实现代码详解
这篇文章主要介绍了python scrapy重复执行实现代码详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取 Scrapy模块: 1.scheduler:用来存放url队列 2.downloader:发送请求 3.spiders:提取数据和url 4.itemPipeline:数据保存 from twisted.internet i
-
Python Scrapy框架:通用爬虫之CrawlSpider用法简单示例
本文实例讲述了Python Scrapy框架:通用爬虫之CrawlSpider用法.分享给大家供大家参考,具体如下: 步骤01: 创建爬虫项目 scrapy startproject quotes 步骤02: 创建爬虫模版 scrapy genspider -t quotes quotes.toscrape.com 步骤03: 配置爬虫文件quotes.py import scrapy from scrapy.spiders import CrawlSpider, Rule from scrap
-
python Scrapy爬虫框架的使用
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy 注意:不要使用commandlinetools自带的python进行安装,不然可能报架构错误:用brew下载的python进行安装. Scrapy实现爬虫 新建爬虫 scrapy startproject demoSpider,demoSpide