python持久化存储文件操作方法
存储文件的重要
一个程序在运行过程中用了九牛二虎之力终于计算出了结果,试想一下如果不把这些数据存放起来,相比重启电脑之后,。 默认数据是加载到内存中,结果也是保存到内存中, 程序执行结束,所有的数据释放。
要读取二进制文件,比如图片、视频等等,用'rb', ‘wb', 'ab'等模式打开文件即可!
mode:
r:只能读文件
w:只能写入(清空文件内容)
a+:读写(追加)
打开文件:
f = open(‘doc/hello.txt',mode=‘a')
文件的读写操作
f.write('\nhello python')
文件的关闭
f.close()
f = open('C:/Users/Shinelon/PycharmProjects/pythonProject1/python/westos',mode='a+')
f.write('\nxinxiedeo')
结果如下:
本来文件westos里面内容如下:
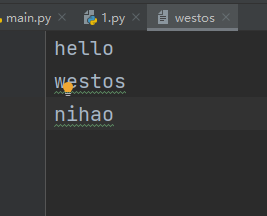
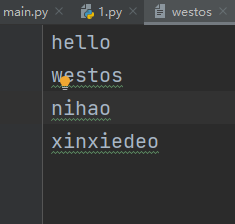
执行命令之后:就添加进去了

指针的概念
对于指针:seek(offset, from)有2个参数: offset:偏移量 from:方向!!
0:表示文件开头;
1:表示当前位置;
2:表示文件末尾
文件的关闭
方法一: 调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,
并且操作系统同一时间能打开的文件数量也是有限的:
方法二: Python引入了with语句来自动帮我们调用close()方法
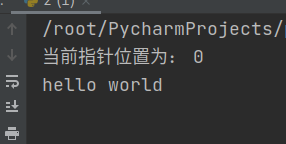
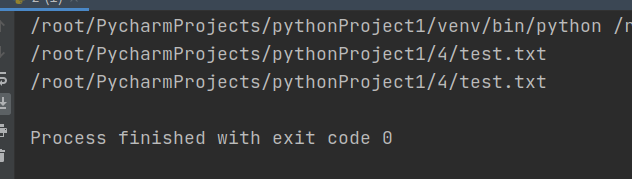
with open('/root/PycharmProjects/pythonProject1/4/test.txt','w+') as f:
f.write('hello world\n')
f.seek(0,0) #移动指针位置到文件最开始
print("当前指针位置为:",f.tell())
print(f.read()) #读取文件内容
执行和结果如下:
若是修改指针位置:
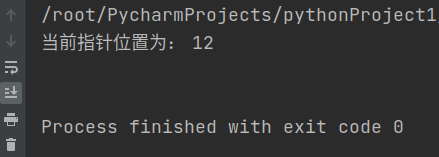
with open('/root/PycharmProjects/pythonProject1/4/test.txt','w+') as f:
f.write('hello world\n')
f.seek(0,2) #移动指针位置到文件末尾
print("当前指针位置为:",f.tell())
print(f.read()) #读取文件内容
那么输出如下:
OS模块
功能:
os,语义为操作系统,处理操作系统相关的功能,可跨平台。 比如显示当前目录下所有文件/删除某个文件/获取文件大小……
获取操作系统的类型
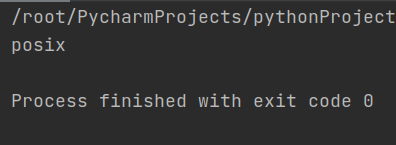
import os #Linux操作系统 import platform #windows操作系统 print(os.name) # 2.获取主机信息,windows系统使用platform模块,如果是linux系统直接使用os模块
结果如下:
我们需要完善代码:
不确定是windows系统,还是linux操作系统!!
用到
try:可能报错的执行内容!
excpt:可能异常的执行内容!
finally:都会执行的内容!
import os import platform try: uname = os.uname() except : uname = platform.uname() finally: print(uname)
结果如下:

获得系统的环境变量!
import os envs = os.environ print(envs)
结果如下:

文件的路径问题也很重要:
先判断是不是就对的路径
import os
print(os.path.isabs('/root/PycharmProjects/pythonProject1/4/test.txt'))
print(os.path.isabs('test.txt'))
结果如下:

生成绝对路径:
import os
print(os.path.abspath('/root/PycharmProjects/pythonProject1/4/test.txt'))
print(os.path.abspath('test.txt'))
结果如下:
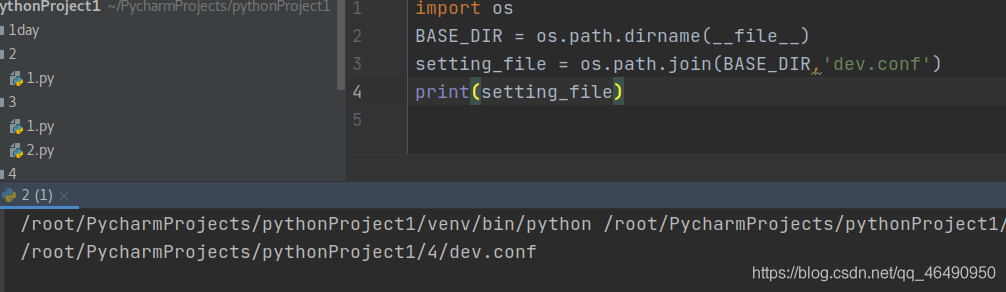
目录名和文件名的拼接
#os.path.dirname获取某个文件对应的目录名
#__file__是指当前文件
#join 拼接,将目录和文件名拼接起来
import os BASE_DIR = os.path.dirname(__file__) setting_file = os.path.join(BASE_DIR,'dev.conf') print(setting_file)
结果如下:
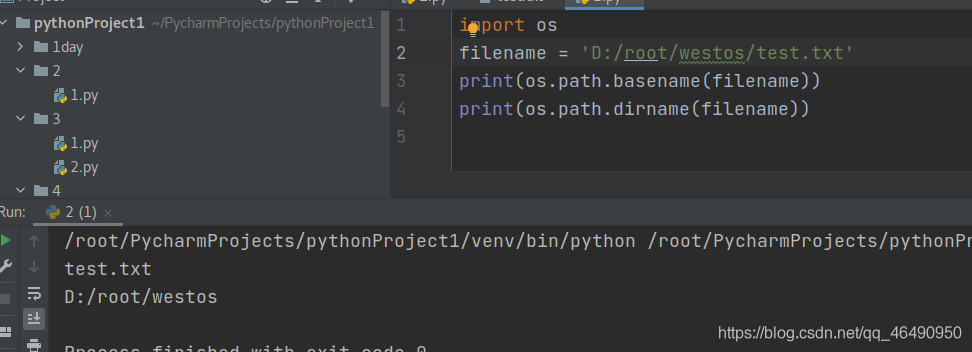
获取目录名或者文件名
import os filename = 'D:/root/westos/test.txt' print(os.path.basename(filename)) #输出文件名 print(os.path.dirname(filename)) #输出文件所在目录
结果如下:
介绍文件的创建和删除
os模块中的rename()可以完成对文件的重命名操作。
rename(需要修改的文件名, 新的文件名)
os模块中的remove()可以完成对文件的删除操作
remove(待删除的文件名)
以上就是python持久化存储文件操作的详细内容,更多关于python存储文件的资料请关注我们其它相关文章!
相关推荐
-
Python如何存储数据到json文件
1 前言 很多程序都要求用户输入某种信息,程序一般将信息存储在列表和字典等数据结构中. 用户关闭程序时,就需要将信息进行保存,一种简单的方式是使用模块json来存储数据. 模块json让你能够将简单的Python数据结构转存到文件中,并在程序再次运行时加载该文件中的数据. 还可以使用json在Python程序之间分享数据,更重要的是,JSON(JavaScript Object Notation,最初由JavaScript开发)格式的数据文件能被很多编程语言兼容. 2 使用json.dump(
-
详解如何在python中读写和存储matlab的数据文件(*.mat)
背景 在做deeplearning过程中,使用caffe的框架,一般使用matlab来处理图片(matlab处理图片相对简单,高效),用python来生成需要的lmdb文件以及做test产生结果.所以某些matlab从图片处理得到的label信息都会以.mat文件供python读取,同时也python产生的结果信息也需要matlab来做进一步的处理(当然也可以使用txt,不嫌麻烦自己处理结构信息). 介绍 matlab和python间的数据传输一般是基于matlab的文件格式.mat,pytho
-
Python把对应格式的csv文件转换成字典类型存储脚本的方法
该脚本是为了结合之前的编写的脚本,来实现数据的比对模块,实现数据的自动化!由于数据格式是定死的,该代码只做参考,有什么问题可以私信我! CSV的数据格式截图如下: readDataToDic.py源代码如下: #coding=utf8 import csv ''' 该模块的主要功能,是根据已有的csv文件, 通过readDataToDicl函数,把csv中对应的部分, 写入字典中,每个字典当当作一条json数据 ''' class GenExceptData(object): def __ini
-
python用pandas数据加载、存储与文件格式的实例
数据加载.存储与文件格式 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数.其中read_csv和read_talbe用得最多 pandas中的解析函数: 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据,默认分隔符为逗号 read_table 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为制表符("\t") read_fwf 读取定宽列格式数据(也就是说,没有分隔符) read_clipboard 读取剪贴板中的数据,
-
python将xml xsl文件生成html文件存储示例讲解
前提:安装libxml2 libxstl 官方网站:http://xmlsoft.org/XSLT/index.html 安装包下载:http://xmlsoft.org/sources/ 下面是windows平台的exe安装文件下载: http://xmlsoft.org/sources/win32/python/这是转载的测试代码: 复制代码 代码如下: # -*- coding: mbcs -*-#!/usr/bin/python import libxml2, libxslt class
-
Python的Django中将文件上传至七牛云存储的代码分享
最近在写的一个django小项目需要实现用户上传图片的功能,使用到了七牛云存储,特此记录下来.这里我使用的七牛python SDK 版本是7.0.3,函数使用上可能会与旧版有些不同. 原本文件上传需要先把文件上传到自己的业务服务器,再从业务服务器上传到云存储.现在七牛的表单上传可以直接把文件上传到七牛,不再需要业务服务器的中转,节省了流量成本,降低了业务服务器的压力.而且通过设置,还可以在文件上传完成后让客户端自动重定向到一个上传成功的结果页面.这里我就是使用了七牛的表单上传. 表单上传 用户上
-
python目录操作之python遍历文件夹后将结果存储为xml
Linux服务器有CentOS.Fedora等,都预先安装了Python,版本从2.4到2.5不等,而Windows类型的服务器也多数安装了Python,因此只要在本机写好一个脚本,上传到对应机器,在运行时修改参数即可. Python操作文件和文件夹使用的是os库,下面的代码中主要用到了几个函数: os.listdir:列出目录下的文件和文件夹os.path.join:拼接得到一个文件/文件夹的全路径os.path.isfile:判断是否是文件os.path.splitext:从名称中取出一个子
-

python持久化存储文件操作方法
存储文件的重要 一个程序在运行过程中用了九牛二虎之力终于计算出了结果,试想一下如果不把这些数据存放起来,相比重启电脑之后,. 默认数据是加载到内存中,结果也是保存到内存中, 程序执行结束,所有的数据释放. 要读取二进制文件,比如图片.视频等等,用'rb', 'wb', 'ab'等模式打开文件即可! mode: r:只能读文件 w:只能写入(清空文件内容) a+:读写(追加) 打开文件: f = open('doc/hello.txt',mode='a') 文件的读写操作 f.write('\nh
-
Python之str操作方法(详解)
1. str.format():使用"{}"占位符格式化字符串(占位符中的索引号形式和键值对形式可以混合使用). >>> string = 'python{}, django{}, tornado{}'.format(2.7, 'web', 'tornado') # 有多少个{}占位符就有多少个值与其对应,按照顺序"填"进字符串中 >>> string 'python2.7, djangoweb, tornadotornado'
-
python win32 简单操作方法
源由 刚开始是帮朋友做一个按键精灵操作旺信的脚本,写完后各种不稳定:后来看到python可以操作win32相关的api,恰好这一段时间正在学习python,感觉练手的时候到了~~~ 下载 要注意Python版本及位数,否则会安装失败 直接到上面的地址去找合适的版本下载安装,已包含其它的工具 下载的已经是可执行文件,直接执行即可 https://sourceforge.net/projects/pywin32/ 获取句柄的方式 VC或VS工具里面自带SPY++,可以获取句柄信息, 这个你没有,请看
-
Python之re操作方法(详解)
一:re.search():search返回的是查找结果的对象,可以使用group()或groups()方法得到匹配成功的字符串. ①group() 默认返回匹配成功的整个字符串(忽略pattern中的括号),也可以指定返回匹配成功的括号中第几个字符串(从1开始计数): ②groups() 以元组的形式返回匹配成功的pattern中括号中的内容,若pattern中没有括号,则返回空元组. 以上这篇Python之re操作方法(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多
-
Python之os操作方法(详解)
1. os.path.driname(path):返回路径的上一级路径字符串. >>> os.path.dirname('D:\Games') 'D:\\' >>> 2. os.path.basename(path):返回路径的最后一级目录名(文件夹名)或文件名(全称). >>> os.path.basename('D:\Games\9yin_632\蜗牛整包\\0x0804.ini') '0x0804.ini' >>> 3. os.
-
详解python持久化文件读写
持久化文件读写: f=open('info.txt','a+') f.seek(0) str1=f.read() if len(str1)==0: f1 = open('info.txt', 'w+') str1 = f.read() # 如果数据没有就写入数据到文件 time_list = ["早上", "中午", "晚上"] character_list = ["小赵","小钱", "小孙&q
-
Anaconda 离线安装 python 包的操作方法
因为有时直接使用pip install在线安装 Python 库下载速度非常慢,所以这里介绍使用 Anaconda 离线安装 Python 库的方法. 这里以安装 pyspark 这个库为例,因为这个库大约有180M,我这里测试的在线安装大约需要用二十多个小时,之后使用离线安装的方法,全程大约用时10分钟. 查看所需的 Python 包 如果不知道具体使用什么版本的 Python 库,可以先尝试在 Aanconda Prompt 中直接使用 pip install pyspark 我这里根据提示
-
python dataframe常见操作方法:实现取行、列、切片、统计特征值
实例如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import * from numpy import * data = DataFrame(np.arange(16).reshape(4,4),index = list("ABCD"),columns=list('wxyz')) print data print data[0:2] #取前两行数据 print'+++++
-
Python插入Elasticsearch操作方法解析
这篇文章主要介绍了Python插入Elasticsearch操作方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在用scrapy做爬虫的时候,需要将数据存入的es中.网上找了两种方法,照葫芦画瓢也能出来,暂记下来: 首先安装了es,版本是5.6.1的较早版本 用pip安装与es版本相对的es相关包 pip install elasticsearch-dsl==5.1.0 方法一: 以下是pipelines.py模块的完整代码 # -*-
-
python时间日期操作方法实例小结
本文实例讲述了python时间日期操作方法.分享给大家供大家参考,具体如下: #coding=utf-8 import time import datetime if __name__ == "__main__": # 今天 now = datetime.datetime.now() print now.strftime('%Y-%m-%d %H:%M:%S') print "%s-%s-%s %s:%s:%s" % (now.year, now.month, no