Python使用MapReduce编程模型统计销量
目录
- 1、生成模拟数据
- 2、mapper实现
- 3、reducer实现
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
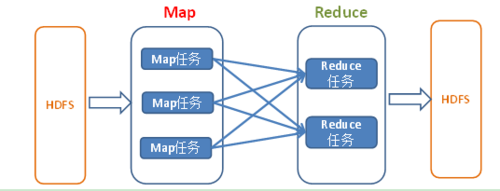
下面就通过手动实现MapReduce编码统计销售数量的例子来模拟。
打开Python3在线编程网址:
http://www.dooccn.com/python3/
1、生成模拟数据
#!/usr/bin/python
# -*- coding: utf-8 -*-
import random
# 模拟商品
stocks = ["HUAWEI Mate40","Apple iphone13","Apple MacBook Pro 14","ThinkBook 14p","RedmiBook Pro14","飞鹤星飞帆幼儿奶粉","爱他美 幼儿奶粉","李宁运动男卫裤","小米踏步机椭圆机","欧莱雅面膜","御泥坊面膜","欧莱雅男士套装","金六福白酒","牛栏山42度","茅台飞天"]
# 销售订单
sales_list = list()
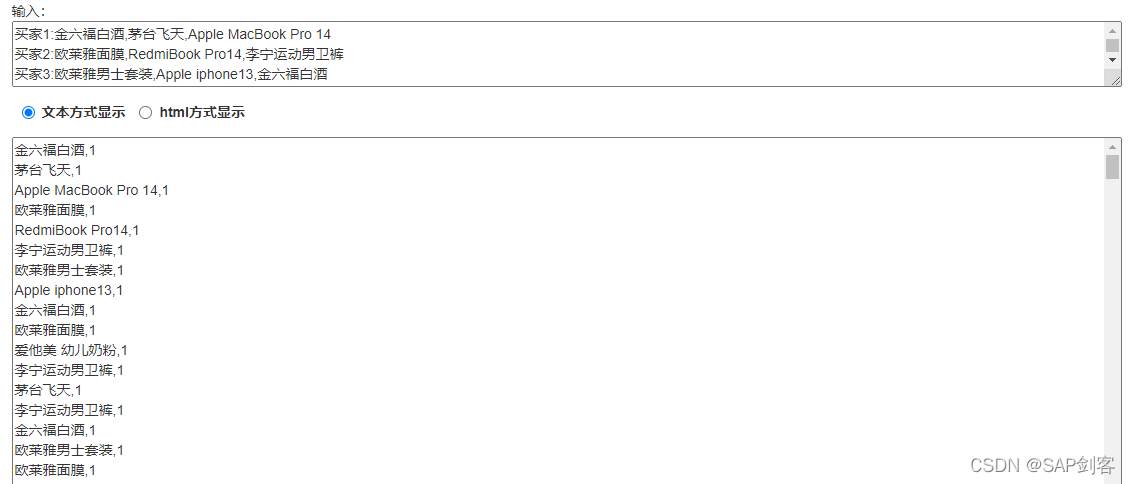
# 生成100个买家订单,每个订单三个商品
for i in range(100):
sstocks = list()
for j in range(3):
sstocks.append(stocks[random.randint(0,14)])
a = "买家" + str(i+1) + ":" + ",".join(sstocks)
print(a)

2、mapper实现
将第一步的结果作为第二步的输入。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#从控制台中读取数据,循环发送每行数据
for line in sys.stdin:
#对订单进行拆分
orders = line.strip().split(":")
if len(orders) == 2:
#对订单中的商品进行拆分
stocks = orders[1].split(",")
for stock in stocks:
#将每一个商品作为key,value进行输出
print('%s,%s' % (stock,1))
3、reducer实现
将第二步的结果作为第三步的输入。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
# 创建一个空的字典用来每一个商品的销售数据
stock_dict = dict()
for line in sys.stdin:
if len(line.strip()) >= 1:
# 拆分每一行的商品,销量
stock, sales = line.split(',')
# 判断当前商品是否在字典中有存放
if stock in stock_dict:
# 如果有,把字典中的商品和销量取出来,追加当前销量再放入
stock_dict[stock] = stock_dict[stock] + int(sales)
else:
# 如果没有,直接把商品和销量数据放入字典中
stock_dict[stock] = int(sales)
# 遍历字典列表,获取每一个商品的销量
for stock, sales in stock_dict.items():
print('%s\t%s' % (stock, sales))

这样就实现了简单的销售统计。
到此这篇关于Python使用MapReduce编程模型统计销量的文章就介绍到这了,更多相关Python MapReduce内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python多线程抽象编程模型详解
最近需要完成一个多线程下载的工具,对其中的多线程下载进行了一个抽象,可以对所有需要使用到多线程编程的地方统一使用这个模型来进行编写. 主要结构: 1.基于Queue标准库实现了一个类似线程池的工具,用户指定提交任务线程submitter与工作线程worker数目,所有线程分别设置为后台运行,提供等待线程运行完成的接口. 2.所有需要完成的任务抽象成task,提供单独的无参数调用方式,供worker线程调用:task以生成器的方式作为参数提供,供submitter调用. 3.所有需要进行线程交互的
-

Python使用MapReduce编程模型统计销量
目录 1.生成模拟数据 2.mapper实现 3.reducer实现 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性.它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上. 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归
-
MongoDB中MapReduce编程模型使用实例
注:作者使用的MongoDB为2.4.7版本. 单词计数示例: 插入用于单词计数的数据: 复制代码 代码如下: db.data.insert({sentence:'Consider the following map-reduce operations on a collection orders that contains documents of the following prototype'})db.data.insert({sentence:'I get the following e
-
基于python yield机制的异步操作同步化编程模型
本文总结下如何在编写python代码时对异步操作进行同步化模拟,从而提高代码的可读性和可扩展性. 游戏引擎一般都采用分布式框架,通过一定的策略来均衡服务器集群的资源负载,从而保证服务器运算的高并发性和CPU高利用率,最终提高游戏的性能和负载.由于引擎的逻辑层调用是非抢占式的,服务器之间都是通过异步调用来进行通讯,导致游戏逻辑无法同步执行,所以在代码层不得不人为地添加很多回调函数,使一个原本完整的功能碎片化地分布在各个回调函数中. 异步逻辑 以游戏中的副本评分逻辑为例,在副本结束时副本管理进程需要
-
用Python的SimPy库简化复杂的编程模型的介绍
在我遇到 SimPy 包的其中一位创始人 Klaus Miller 时,从他那里知道了这个包.Miller 博士阅读过几篇提出使用 Python 2.2+ 生成器实现半协同例程和"轻便"线程的技术的 可爱的 Python专栏文章.特别是(使我很高兴的是),他发现在用 Python 实现 Simula-67 样式模拟时,这些技术很有用. 结果表明 Tony Vignaux 和 Chang Chui 以前曾创建了另一个 Python 库,它在概念上更接近于 Simscript,而且该库使用
-
详解Python Socket网络编程
Socket 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于 Socket 来完成通信的,例如我们每天浏览网页.QQ 聊天.收发 email 等等.要解决网络上两台主机之间的进程通信问题,首先要唯一标识该进程,在 TCP/IP 网络协议中,就是通过 (IP地址,协议,端口号) 三元组来标识进程的,解决了进程标识问题,就有了通信的基础了. 本文主要介绍使用Python 进行TCP Socket 网络编程,假设你已经具
-
Python中利用LSTM模型进行时间序列预测分析的实现
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的. 举个栗子:根据过去两年某股票的每天的股价数据推测之后一周的股价变化:根据过去2年某店铺每周想消费人数预测下周来店消费的人数等等 RNN 和 LSTM 模型 时间序列模型最常用最强大的的工具就是递归神经网络(recurrent neural n
-
关于Python的GPU编程实例近邻表计算的讲解
目录 技术背景 加速场景 基于Numba的GPU加速 总结概要 技术背景 GPU加速是现代工业各种场景中非常常用的一种技术,这得益于GPU计算的高度并行化.在Python中存在有多种GPU并行优化的解决方案,包括之前的博客中提到的cupy.pycuda和numba.cuda,都是GPU加速的标志性Python库.这里我们重点推numba.cuda这一解决方案,因为cupy的优势在于实现好了的众多的函数,在算法实现的灵活性上还比较欠缺:而pycuda虽然提供了很好的灵活性和相当高的性能,但是这要求
-
浅谈Python的元编程
目录 一.装饰器 二.装饰器的执行顺序 三.元类 四.descriptor 类(描述符类) 五.总结 相应的元编程就是描述代码本身的代码,元编程就是关于创建操作源代码(比如修改.生成或包装原来的代码)的函数和类.主要技术是使用装饰器.元类.描述符类. 一.装饰器 装饰器就是函数的函数,它接受一个函数作为参数并返回一个新的函数,在不改变原来函数代码的情况下为其增加新的功能,比如最常用的计时装饰器: from functools import wraps def timeit(logger=None
-
Python数学建模库StatsModels统计回归简介初识
目录 1.关于 StatsModels 2.文档 3.主要功能 4.获取和安装 1.关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化. 2.文档 最新版本的文档位于: https://www.statsmodels.org/stable/ 3.主要功能 1.线性回归模型: 普通最小二乘法 广义最小二乘法 加权最小二乘法 具有自回归误差的最小二乘法 分位数回归 递