Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录
- 一、条件筛选
- 二、Dataframe数据遍历
- for...in...语句
- iteritems()方法
- iterrows()方法
- itertuples()方法
一、条件筛选
查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式。
示例Dataframe如下:
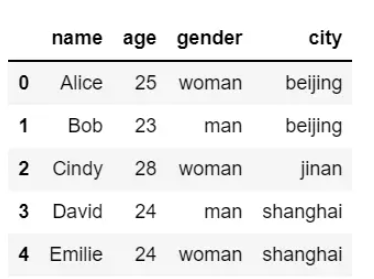
单条件筛选,例如查询gender为woman的数据:
df[df["gender"]=="woman"] # 或 df.loc[df["gender"]=="woman"]

使用isin()函数筛选,例如查询age为24、28的数据:
df[df["age"].isin([24,28])]

当有多个过滤条件时,可以使用逻辑操作符&和|,如下。
例如:查询gender为“woman”并且city为“shanghai”的数据:
df[(df["gender"]=="woman") & (df["city"]=="shanghai")]
查询age大于25或者gender为“woman”的数据:
df[(df["age"]>25) | (df["gender"]=="woman")]
注意:逻辑操作符两边的过滤条件必须使用小括号()括起来,否则会报错或者不起作用。
波浪线符~可以取指定条件相反的数据,例如查询city不为“beijing”的数据:
df[~(df["city"]=="beijing")]
二、Dataframe数据遍历
for...in...语句
因为 Dataframe 对象属于可迭代对象,所以可以使用for...in...语句进行遍历,遍历结果是列的名称,如下:
for i in df:
print(i)
结果输出如下:

如果要遍历 DataFrame 的行数据,需要使用以下方法:
iteritems()方法
iteritems()方法是按列进行遍历,遍历结果为为(列名, value)键值对:
for column, value in df.iteritems():
print(column)
print(value)
iterrows()方法
iterrows()方法是按行进行遍历,遍历结果为(index, value)键值对:
for index, row in df.iterrows():
print(index)
print(row)

itertuples()方法
itertuples()是以namedtuples(命名元组)形式遍历行,遍历每一行为一个命名元组:
for row in df.itertuples():
print(row)

到此这篇关于Python数据分析之 Pandas Dataframe条件筛选遍历详情的文章就介绍到这了,更多相关 Pandas Dataframe遍历内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
Python数据分析之 Pandas Dataframe应用自定义
目录 前言: 应用函数 apply 方法 applymap 方法 前言: 在进行数据分析时,难免需要对数据集应用一些我们自定义的一些函数,或者其他库的函数,得到我们想要的数据,这种情况下,可能大家第一时间想到的是使用for循环遍历Dataframe对象,取到指定行/列的数据再进行自定义函数的应用,当然这种方法完全可以实现,但是效率不高,接下来就来介绍一下在Pandas中如何对数据集高效的进行自定义函数的应用. 应用函数 apply 方法 apply()函数是一个自定义函数作用于某一行或几行,或者
-
Python pandas.DataFrame 找出有空值的行
0.摘要 pandas中DataFrame类型中,找出所有有空值的行,可以使用.isnull()方法和.any()方法. 1.找出含有空值的行 方法:DataFrame[DataFrame.isnull().T.any()] 其中,isnull()能够判断数据中元素是否为空值:T为转置:any()判断该行是否有空值. import pandas as pd import numpy as np n = np.arange(20, dtype=float).reshape(5,4) n[2,3]
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
python pandas dataframe 去重函数的具体使用
今天笔者想对pandas中的行进行去重操作,找了好久,才找到相关的函数 先看一个小例子 from pandas import Series, DataFrame data = DataFrame({'k': [1, 1, 2, 2]}) print data IsDuplicated = data.duplicated() print IsDuplicated print type(IsDuplicated) data = data.drop_duplicates() print data 执行
-
python pandas分割DataFrame中的字符串及元组的方法实现
目录 1.使用str.split()方法 2.使用join()与split()方法结合 3.使用apply方法分割元组 1.使用str.split()方法 可以使用pandas 内置的 str.split() 方法实现分割字符串类型的数据,并将分割结果写入DataFrame中,以表格形式呈现. 语法: Series.str.split(pat=None, n=-1, expand=False) 其中,pat是字符串或正则表达式,n是一个整数数字,默认为-1.为0或-1时即为最大次数的分割.其他数
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender
-
python实现在pandas.DataFrame添加一行
实例如下所示: from pandas import * from random import * df = DataFrame(columns=('lib', 'qty1', 'qty2'))#生成空的pandas表 for i in range(5):#插入一行<span id="transmark" style="display:none;"></span> df.loc[i] = [randint(-1,1) for n in ran
-
Python数据分析模块pandas用法详解
本文实例讲述了Python数据分析模块pandas用法.分享给大家供大家参考,具体如下: 一 介绍 pandas(Python Data Analysis Library)是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一. pandas主要提供了3种数据结构: 1)Series,带标签的一维数组. 2)DataFrame,带标签且大小可变的二维表格结构. 3)Panel,带标
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
pandas按条件筛选数据的实现
pandas中对DataFrame筛选数据的方法有很多的,以后会后续进行补充,这里只整理遇到错误的情况. 1.使用布尔型DataFrame对数据进行筛选 使用一个条件对数据进行筛选,代码类似如下: num_red=flags[flags['red']==1] 使用多个条件对数据进行筛选,代码类似如下: stripes_or_bars=flags[(flags['stripes']>=1) | (flags['bars']>=1)] 常见的错误代码如下: 代码一: stripes_or_bars
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406