PostgreSQL ROW_NUMBER() OVER()的用法说明
语法:
ROW_NUMBER() OVER( [ PRITITION BY col1] ORDER BY col2[ DESC ] )
解释:
ROW_NUMBER()为返回的记录定义个行编号, PARTITION BY col1 是根据col1分组,ORDER BY col2[ DESC ]是根据col2进行排序。
举例:
postgres=# create table student(id serial,name character varying,course character varying,score integer);
CREATE TABLE
postgres=#
postgres=# \d student
Table "public.student"
Column | Type | Modifiers
--------+-------------------+----------------------------------------------
id | integer | not null default nextval('student_id_seq'::regclass)
name | character varying |
course | character varying |
score | integer |
insert into student (name,course,score) values('周润发','语文',89);
insert into student (name,course,score) values('周润发','数学',99);
insert into student (name,course,score) values('周润发','外语',67);
insert into student (name,course,score) values('周润发','物理',77);
insert into student (name,course,score) values('周润发','化学',87);
insert into student (name,course,score) values('周星驰','语文',91);
insert into student (name,course,score) values('周星驰','数学',81);
insert into student (name,course,score) values('周星驰','外语',88);
insert into student (name,course,score) values('周星驰','物理',68);
insert into student (name,course,score) values('周星驰','化学',83);
insert into student (name,course,score) values('黎明','语文',85);
insert into student (name,course,score) values('黎明','数学',65);
insert into student (name,course,score) values('黎明','外语',95);
insert into student (name,course,score) values('黎明','物理',90);
insert into student (name,course,score) values('黎明','化学',78);
1. 根据分数排序
postgres=# select *,row_number() over(order by score desc)rn from student; id | name | course | score | rn ----+--------+--------+-------+---- 2 | 周润发 | 数学 | 99 | 1 13 | 黎明 | 外语 | 95 | 2 6 | 周星驰 | 语文 | 91 | 3 14 | 黎明 | 物理 | 90 | 4 1 | 周润发 | 语文 | 89 | 5 8 | 周星驰 | 外语 | 88 | 6 5 | 周润发 | 化学 | 87 | 7 11 | 黎明 | 语文 | 85 | 8 10 | 周星驰 | 化学 | 83 | 9 7 | 周星驰 | 数学 | 81 | 10 15 | 黎明 | 化学 | 78 | 11 4 | 周润发 | 物理 | 77 | 12 9 | 周星驰 | 物理 | 68 | 13 3 | 周润发 | 外语 | 67 | 14 12 | 黎明 | 数学 | 65 | 15 (15 rows)
rn是给我们的一个排序。
2. 根据科目分组,按分数排序
postgres=# select *,row_number() over(partition by course order by score desc)rn from student; id | name | course | score | rn ----+--------+--------+-------+---- 5 | 周润发 | 化学 | 87 | 1 10 | 周星驰 | 化学 | 83 | 2 15 | 黎明 | 化学 | 78 | 3 13 | 黎明 | 外语 | 95 | 1 8 | 周星驰 | 外语 | 88 | 2 3 | 周润发 | 外语 | 67 | 3 2 | 周润发 | 数学 | 99 | 1 7 | 周星驰 | 数学 | 81 | 2 12 | 黎明 | 数学 | 65 | 3 14 | 黎明 | 物理 | 90 | 1 4 | 周润发 | 物理 | 77 | 2 9 | 周星驰 | 物理 | 68 | 3 6 | 周星驰 | 语文 | 91 | 1 1 | 周润发 | 语文 | 89 | 2 11 | 黎明 | 语文 | 85 | 3 (15 rows)
3. 获取每个科目的最高分
postgres=# select * from(select *,row_number() over(partition by course order by score desc)rn from student)t where rn=1; id | name | course | score | rn ----+--------+--------+-------+---- 5 | 周润发 | 化学 | 87 | 1 13 | 黎明 | 外语 | 95 | 1 2 | 周润发 | 数学 | 99 | 1 14 | 黎明 | 物理 | 90 | 1 6 | 周星驰 | 语文 | 91 | 1 (5 rows)
4. 每个科目的最低分也是一样的
postgres=# select * from(select *,row_number() over(partition by course order by score)rn from student)t where rn=1; id | name | course | score | rn ----+--------+--------+-------+---- 15 | 黎明 | 化学 | 78 | 1 3 | 周润发 | 外语 | 67 | 1 12 | 黎明 | 数学 | 65 | 1 9 | 周星驰 | 物理 | 68 | 1 11 | 黎明 | 语文 | 85 | 1 (5 rows)
只要在根据科目排序的时候按低到高顺序排列就好了。
补充:SQL:postgresql中为查询结果增加一个自增序列之ROW_NUMBER () OVER ()的使用
举例说明:
SELECT ROW_NUMBER () OVER ( ORDER BY starttime DESC ) "id", starttime AS "text", starttime FROM warning_products WHERE pid_model = '结果' AND starttime IS NOT NULL GROUP BY starttime
在这一段代码中:
查询语句就不说了, select …from…where
GROUP BY的作用:
这一段代码执行的结果是:
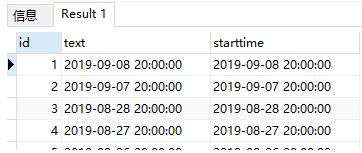
如果将GROUP BY删除,那么执行结果为:

可以看到查询出了两个相同starttime数据.
由此得出:
GROUP BY的作用是分类汇总.也就是说,查询结果中,starttime每一种查询结果只有一个
GROUP BY的作用:
如果将DESC换成
() OVER ( ORDER BY starttime ASC ) "id",
则运行结果为:

相比可以发现,ORDER BY的作用为进行排序.
按照某种要求进行固定的排序
ROW_NUMBER () OVER() “id”
先来看一下,如果把这一段删掉,运行结果:
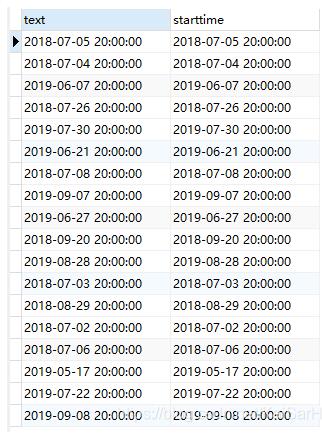
加上呢?

明显的对比,我们为最终的查询结果增加了一列自增的id序列(这里id可以改名,"id"改为其他的即可)
由此得到结论,在执行带有row_number() over() "xx"的SQL语句时候,代码会先执行查询语句,然后执行over中的命令,最后为结果增加一列自增的序列.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

PostgreSQL 实现给查询列表增加序号操作
利用 ROW_NUMBER() over( ) 给查询序列增加排序字段 SELECT ROW_NUMBER() over(ORDER bY biztypename DESC ) AS num,biztypename FROM (SELECT DISTINCT biztypename FROM bizmaptype) t; 效果如下: 补充:PostgreSql 使用自定义序列(Sequence)向表插入数据 id 自增长 按照以往Oracle建表的流程,我们来新建表,并且向表中导入数据. 1.创
-
在PostgreSQL中设置表中某列值自增或循环方式
在postgresql中,设置已存在的某列(num)值自增,可以用以下方法: //将表tb按name排序,利用row_number() over()查询序号并将该列命名为rownum,创建新表tb1并将结果保存到该表中 create table tb1 as (select *, row_number() over(order by name) as rownum from tb); //根据两张表共同的字段name,将tb1中rownum对应值更新到tb中num中 update tb set
-
postgreSQL中的row_number() 与distinct用法说明
我就废话不多说了,大家还是直接看代码吧~ select count(s.*) from ( select *, row_number() over (partition by fee_date order by fee_date) as gr from new_order where news_id='novel' and order_status='2' ) s where s.gr = 1 SELECT count(DISTINCT fee_date) as dis from new_ord
-
PostgreSQL ROW_NUMBER() OVER()的用法说明
语法: ROW_NUMBER() OVER( [ PRITITION BY col1] ORDER BY col2[ DESC ] ) 解释: ROW_NUMBER()为返回的记录定义个行编号, PARTITION BY col1 是根据col1分组,ORDER BY col2[ DESC ]是根据col2进行排序. 举例: postgres=# create table student(id serial,name character varying,course character vary
-
Oracle中ROW_NUMBER()OVER()函数用法实例讲解
目录 1. 说明: 2. 原理: 3.语法: 4.示例一: 5. 示例二 总结 Oracle中ROW_NUMBER() OVER()函数用法 1. 说明: ROW_NUMBER() OVER() 函数的作用:分组排序 2. 原理: row_number() over() 函数,over() 里的分组以及排序的执行晚于 where.group by.order by 的执行. 3.语法: row_number() over( partition by 分组列 order by 排序列 desc )
-
SQL Server 排序函数 ROW_NUMBER和RANK 用法总结
1.ROW_NUMBER()基本用法: SELECT SalesOrderID, CustomerID, ROW_NUMBER() OVER (ORDER BY SalesOrderID) AS RowNumber FROM Sales.SalesOrderHeader结果集:SalesOrderID CustomerID RowNumber--------------- ------------- ---------------43659 676
-
深入探讨:oracle中row_number() over()分析函数用法
row_number()over(partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的). 与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码. row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开始排序). rank()是跳跃排序,有两个第二名
-
PostgreSQL中的COMMENT用法说明
PostgreSQL附带了一个命令 - COMMENT .如果想要记录数据库中的内容,这个命令很有用.本文将介绍如何使用此命令. 随着数据库的不断发展和数据关系变得越来越复杂,跟踪数据库中添加的所有内容会变得非常困难.要记录数据的组织方式以及可能随时间添加或更改的组件,有必要添加某种文档. 例如,文档可以写在外部文件中,但这会产生一种问题,他们很快就会变为过时的文件.PostgreSQL有一个解决这个问题的方法:COMMENT命令.使用它可以向各种数据库对象添加注释,例如在需要时更新的列,索引,
-
postgreSQL中的case用法说明
工具:postgreSQL Navicat Premium 又一次在看代码的时候,发现了不懂的东西! 这次就是case when then SQL CASE表达式是一种通用的条件表达式,类似于其它语言中的if/else语句. CASE WHEN condition THEN result [WHEN ...] [ELSE result] END 解释: condition是一个返回boolean的表达式. 如果为真,那么CASE表达式的结果就是符合条件的result. 如果结果为假,那么以相同方
-
postgresql synchronous_commit参数的用法介绍
synchronous_commit 指定在命令返回"success"指示给客户端之前,一个事务是否需要等待 WAL 记录被写入磁盘. 合法的值是{local,remote_write,remote_apply,on,off} 默认的并且安全的设置是on. 不同于fsync,将这个参数设置为off不会产生数据库不一致性的风险:一个操作系统或数据库崩溃可能会造成一些最近据说已提交的事务丢失,但数据库状态是一致的,就像这些事务已经被干净地中止.因此,当性能比完全确保事务的持久性更重要时,关
-
PostgreSQL中的collations用法详解
与Oracle相比,PostgreSQL对collation的支持依赖于操作系统. 以下是基于Centos7.5的测试结果 $ env | grep LC $ env | grep LANG LANG=en_US.UTF-8 使用initdb初始化集群的时候,就会使用这些操作系统的配置. postgres=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------
-
PostgreSQL的B-tree索引用法详解
结构 B-tree索引适合用于存储排序的数据.对于这种数据类型需要定义大于.大于等于.小于.小于等于操作符. 通常情况下,B-tree的索引记录存储在数据页中.叶子页中的记录包含索引数据(keys)以及指向heap tuple记录(即表的行记录TIDs)的指针.内部页中的记录包含指向索引子页的指针和子页中最小值. B-tree有几点重要的特性: 1.B-tree是平衡树,即每个叶子页到root页中间有相同个数的内部页.因此查询任何一个值的时间是相同的. 2.B-tree中一个节点有多个分支,即每