pandas针对excel处理的实现
本文主要介绍了pandas针对excel处理的实现,分享给大家,具体如下:

读取文件
import padas
df = pd.read_csv("") #读取文件
pd.read_clipboard() #读取粘贴板的内容
#解决数据显示不完全的问题
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
#获取指定单元格的值
datefirst = config.iloc[0,1]
datename = config.iloc[0,2]
#新建一列two,筛选料号一列的前俩个
sheet["two"] = sheet["料号"].apply(lambda x:x[:2])
数值处理
df["dog"] = df["dog"].replace(-1,0) #数值替换 #apply理解函数作为一个对象,可以作为参数传递给其它参数,并且能作为函数的返回值 df["price_new"] = df["price"].apply(lambda pri:pyi.lower()) #新列对老列处理 df["pricee"] = df["price"] *2 #新列
获取数据
data = df.head() #默认读取前行
df = pd.read_excel("lemon.xlsx",sheet_name=["python","student"]) #可以通过表单名同时读取多个
df = pd.read_excel("lemon.clsx",sheet_name=0)
data = df.values #获取所有的数据
print("获取到所有的值:\n{0}".format(data)) #格式化输出
df = pd.read_excel("lemon.xlsx")
data = df.ix[0].values #表示第一行,不包含表头
print("获取到所有的值:\n{0}".format(data)) #格式化输出
loc和iloc详解
loc[row,cloumn] 先行后列 : 是全部行或列,一般多行可以用中括号,连续的可以用a:c等 iloc[index,columns] 行索引,列索引,索引都是从0开始,用法是一样的
多行
多行嵌套
df = pd.read_excel("lemon.xlsx")
data = df.loc[1,2] #读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("获取到所有的值:\n{0}".format(data)) #格式化输出
多行
df=pd.read_excel('lemon.xlsx')
data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
多行多列嵌套
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2],['title','data']].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
获取所有行和指定列
df=pd.read_excel('lemon.xlsx')
data=df.ix[:,['title','data']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
输出行号和列号
输出行号并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出行号列表",df.index.values)
输出结果是:
输出行号列表 [0 1 2 3]
输出列名并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出列标题",df.columns.values)
运行结果如下所示:
输出列标题 ['case_id' 'title' 'data']
获取指定行数的值
df=pd.read_excel('lemon.xlsx')
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
输出值
[[2 '输入错误的密码' '{"mobilephone":"18688773467","pwd":"12345678"}']
[3 '正常充值' '{"mobilephone":"18688773467","amount":"1000"}']
[1 '正常登录' '{"mobilephone":"18688773467","pwd":"123456"}']]
获取指定值
获取指定列的值
df=pd.read_excel('lemon.xlsx')
print("输出值\n",df['data'].values)
excel数据转字典
df=pd.read_excel('lemon.xlsx')
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['case_id','module','title','http_method','url','data','expected']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
基本格式化
把带有空值的行全部去除
df.dropna()
对空置进行填充
df.fillna(value=0)
df["price"].fillna(df["price".mean()])
去除字符串两边的空格
df["city"] = df["city"].map(str.strip)
大小写转换
df["city"] = df["city"].map(str.lower)
更改数据格式
df["price"].fillna(0).astype("int")
更改列的名称
df.rename(columns={"category":"category_size"})
删除重复项
df["city"].drop_duplicates()
df["city"].drop_duplicates(keep="last")
数字修改和替换
df["city"].replace("sh","shanghai")
前3行数据
df.tail(3)
给出行数和列数
data.describe()
打印出第八行
data.loc[8]
打印出第八行[column_1]的列
data.loc[8,column_1]
第四到第六行(左闭右开)的数据子集
data.loc[range(4,6)]
统计出现的次数
data[column_1].value_counts()
len()函数被应用在column_1列中的每一个元素上
map()运算给每一个元素应用一个的函数
data[column_1].map(len).map(lambda x : x/100).plot() plot是绘图
apply() 给一个列应用一个函数
applymap() 会给dataframe中的所有单元格应用一个函数
遍历行和列
for i,row in data.iterrows():
print(i,row)
选择指定数据的行
important_dates = ['1/20/14', '1/30/14']
data_frame_value_in_set = data_frame.loc[data_frame['Purchase Date']\
.isin(important_dates), :]
选择0-3列
import pandas as pd
import sys
input_file = r"supplier_data.csv"
output_file = r"output_files\6output.csv"
data_frame = pd.read_csv(input_file)
data_frame_column_by_index = data_frame.iloc[:, [0, 3]]
data_frame_column_by_index.to_csv(output_file, index=False)
添加行头
import pandas as pd
input_file = r"supplier_data_no_header_row.csv"
output_file = r"output_files\11output.csv"
header_list = ['Supplier Name', 'Invoice Number', \
'Part Number', 'Cost', 'Purchase Date']
data_frame = pd.read_csv(input_file, header=None, names=header_list)
data_frame.to_csv(output_file, index=False)
数据多表合并
数据合并 1.将表格通过concat()方法进行合并 参数如下: objs(必须参数):参与连接的pandas对象的列表或字典 axis:指明连接的轴向,默认为0 join:选中inner或outer(默认),其它轴向上索引是按交集(inner)还是并集(outer)进行合并 join_axes:指明用于其他N-1条轴的索引,不执行并集/交集运算 keys:与连接对象有关的值,用于形成连接轴向上的层次化索引 verify_integrity:是否去重 ignore_index:是否忽略索引 合并: eg: frames = [df1,df2,df3] result = pd.concat(frames) result = pd.concat(frames,keys=["x","y","z"]) #把每张表来个定义

新增df4表,横向连接到df1表的第2367列,空置补nan index:是新增的行 axis=1是指列 df4 = pd.DataFrame(["B":["sf"],"D":["'sf],index=[2,3,6,7]]) result = pd.concat([df1,df4],axis=1)

将df1和df4横向进行交集合并
result = pd.concat([df1,df4],axis=1,join="inner") 列是增加,行是交集
按照df1的索引进行df1表和df4表的横向索引
pd.concat([df1,df4],axis=1,join_axes=[df1.index]) 列是增加,行以df1为准,空的为NaN
通过append()方法连接表格
result = df1.append(df2)
result = df1.append(df4,ignore_index=True) 空格Nan补充
新增一列s1表,并且跟df1进行横向合并
s1 = pd.Series(["1","2","3","4"],name="x")
result = pd.concat([df1,s1],axis=1) name是列,serise是一维列表,没有name,他会用索引0开始继续填充
pd.concat([df1,s1],axis=1,ignore_index=True) 表格合并后不保留原来的索引列名
将key作为两张表连接的中介
result = pd.merge(left,right,on="key")
result = pd.merge(right,left,on=["key1","key2"])
key1和key2,只要有相同值就行,最后的排列是大的值为key1,小的key2
通过左表索引连接右表
right = pd.DataFrame({"key1":["K0","K2","K1","K2"],
"key2":["K0","K1","K0","K0"],
"C":["C0","C1","C2","C3"],
"D":["D0","D1","D2","D3"]},
index = ["k0","k1","k2"])
result = left.join(right) 以做索引为基准,right没有左索引的用Nan填充
result = left.join(right,how='outer') how:连接方式
on属性在merge中,以k为中心拼接,有相同的就拼
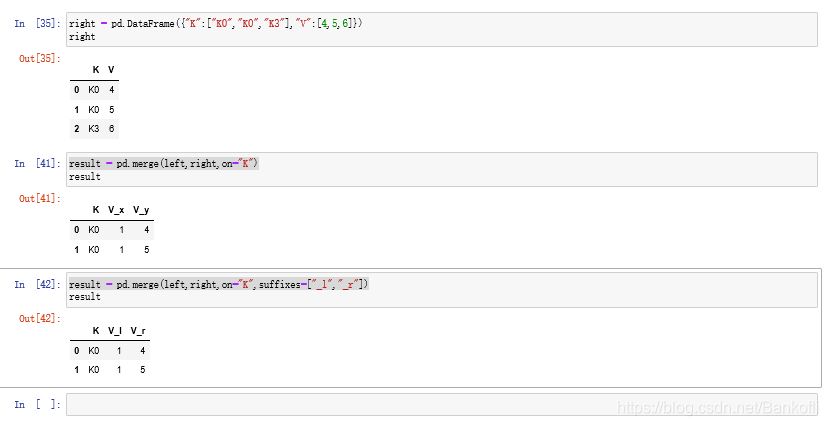
result = pd.merge(left,right,on="K")
result = pd.merge(left,right,on="K",suffixes=["_l","_r"]) 更改拼接后的neme属性



# 解决显示不完全的问题
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
config = pd.read_excel("C:\\Users\\Administrator\\Desktop\\数据\\文件名配置.xlsx", dtype=object)
datefirst = config.iloc[0, 1]
datename = config.iloc[0, 2]
dateall = datefirst + r"\\" + datename
textfile = config.iloc[1, 1]
textname = config.iloc[1, 2]
textall = textfile + r"\\" + textname
sheet = pd.read_excel(dateall, sheet_name="Sheet2", dtype=object)
sheet["two"] = sheet["料号"].apply(lambda x: x[:2])
# 取出不包含的数据
df = sheet[~sheet["two"].isin(["41", "48"])]
df1 = df[~df["检验结果"].isin(["未验", "试产验证允收"])]
# 删除不需要的列
result = df1.iloc[:, :len(df1.columns) - 1]
# 取出包含的数据
DTR561 = result[result["机种"].isin(["DTR561"])]
DTR562 = result[result["机种"].isin(["DTR562"])]
HPS322 = result[result["机种"].isin(["HPS322"])]
HPS829 = result[result["机种"].isin(["HPS829"])]
writer = pd.ExcelWriter("C:\\Users\\Administrator\\Desktop\\数据\\数据筛选.xlsx")
result.to_excel(writer, sheet_name="全部机种", index=False)
DTR561.to_excel(writer, sheet_name="DTR561", index=False)
DTR562.to_excel(writer, sheet_name="DTR562", index=False)
HPS322.to_excel(writer, sheet_name="HPS322", index=False)
HPS829.to_excel(writer, sheet_name="HPS829", index=False)
writer.save()
print("Data filtering completed")
到此这篇关于pandas针对excel处理的实现的文章就介绍到这了,更多相关pandas excel处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用Pandas读写Excel实例解析
这篇文章主要介绍了Python使用Pandas读写Excel实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pandas是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. Pandas提供了大量能使我们快速便捷地处理数据的函数和方法. Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/ Pandas中文文档:https:/
-

用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
解决Python pandas df 写入excel 出现的问题
学习Python数据分析挖掘实战一书时,在数据预处理阶段,有一节要使用拉格朗日插值法对缺失值补充,代码如下: #-*- coding:utf-8 -*- import pandas as pd import matplotlib.pyplot as plt from scipy.interpolate import lagrange#导入拉格朗日插值函数 inputfile="catering_sale.xls" outputfile="H:\python\file\pyth
-
利用pandas将numpy数组导出生成excel的实例
上图 代码 # -*- coding: utf-8 -*- """ Created on Sun Jun 18 20:57:34 2017 @author: Bruce Lau """ import numpy as np import pandas as pd # prepare for data data = np.arange(1,101).reshape((10,10)) data_df = pd.DataFrame(data) # ch
-
pandas分别写入excel的不同sheet方法
pandas可以非常方便的写数据到excel,那么如何写多个dataframe到不同的sheet呢? 使用pandas.ExcelWriter import pandas as pd writer = pd.ExcelFile('your_path.xlsx') df1 = pd.DataFrame() df2 = pd.DataFrame() df1.to_excel(writer, sheet_name='df_1') df2.to_excel(writer, sheet_name='df_
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
Python pandas如何向excel添加数据
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
解决pandas .to_excel不覆盖已有sheet的问题
直接to_excel会被覆盖,借助ExcelWriter可以实现写多个sheet. from openpyxl import load_workbook excelWriter = pd.ExcelWriter(os.path.join(output_dir, 'datapoint_statistic.xlsx'), engine='openpyxl') pd.DataFrame().to_excel(os.path.join( output_dir,'datapoint_statistic.x
-
python pandas写入excel文件的方法示例
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
pandas read_excel()和to_excel()函数解析
前言 数据分析时候,需要将数据进行加载和存储,本文主要介绍和excel的交互. read_excel() 加载函数为read_excel(),其具体参数如下. read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None,names=None, parse_cols=None, parse_dates=False,date_parser=None,na_values=None,thousand
-
Pandas读取并修改excel的示例代码
一.前言 最近总是和excel打交道,由于数据量较大,人工来修改某些数据可能会有点浪费时间,这时候就使用到了Python数据处理的神器-–Pandas库,话不多说,直接上Pandas. 二.安装 这次使用的python版本是python2.7,安装python可以去python的官网进行下载,这里不多说了. 安装完成后使用Python自带的包管理工具pip可以很快的安装pandas. pip install pandas 如果使用的是Anaconda安装的Python,会自带pandas. 三.