专门为初学者编写的正则表达式入门教程
这是一篇翻译文章。我学过很多次正则表达式,总是学了忘,忘了学,一到用的时候还是只能靠搜索引擎。
这回看到这个正则教程,感觉非常惊喜。尝试翻译了一遍,译得不好,大家可以看原文,很容易理解。
原文地址:https://refrf.shreyasminocha.me/
1 介绍
正则表达式允许定义一种模式,并通过这种模式针对字符串执行对应的操作。与模式匹配的子字符串称为“匹配”。
正则表达式是定义搜索模式的一串字符。
正则表达式主要用在如下场景:
- 输入验证
- 查找替换操作
- 高级字符串操作
- 文件搜索或重命名
- 白名单和黑名单
正则表达式不太适合用在这些场景:
- XML 或 HTML 解析
- 完全匹配的日期
有许多实现正则匹配的引擎,每种都有自己的特性。这本书将避免讨论(不同引擎之间的)特性差异,而是只讨论在大多数情况下不同引擎都共有的特征。
整本书中的示例使用JavaScript。因此,这本书可能会稍微偏向 JavaScript 的正则引擎。
2 基础
正则表达式通常格式化为 /<rules>/<flags>,通常为了简洁而省略后面的 /<flags>。关于 flag 我们将在下一章详细讨论。
让我们从/p/g 这个正则表达式开始。现在,请将 /g flag 视为固定不变的。
/p/g

如我们所见,/p/g 匹配所有小写的 p 字符。
注意
默认情况下,正则表达式区分大小写。
在输入字符串中找到的正则表达式模式的实例称为“匹配”。
/pp/g

3 字符组
可以从一组字符中匹配一个字符。
/[aeiou]/g

[aeiou]/g 匹配输入字符串中的所有元音。
下面是另一个例子:
/p[aeiou]t/g

我们匹配一个 p,后跟一个元音,然后是一个 t。
有一个更直观的快捷方式,可以在一个连续的范围内匹配一个字符。
/[a-z]/g

警告
表达式
/[a-z]/g只匹配一个字符。在上面的示例中,每个字符都有一个单独的匹配项。不是整个字符串匹配。
我们也可以在正则表达式中组合范围和单个字符。
/[A-Za-z0-9_-]/g

我们的正则表达式 /[A-Za-z0-9_-]/g 匹配一个字符,该字符必须(至少)是以下字符之一:
A-Za-z0-9_或者-
我们也可以“否定”这些规则:
/[^aeiou]/g

/[aeiou]/g与 /[^aeiou]/g 之间的唯一区别是 ^ 紧跟在左括号之后。其目的是"否定"括号中定义的规则。它表示的意思是:
匹配任何不属于a、e、i、o和 u 的字符
3.1 例子
非法的用户名字符
/[^a-zA-Z_0-9-]/g

指定字符
/[A-HJ-NP-Za-kmnp-z2-9]/g

4 字符转义
字符转义是对某些通用字符类的简略表达方式。
4.1 数字字符 \d
转义符 \d 表示匹配数字字符 0-9。等同于 [0-9]。
/\d/g(这里请仔细看)

/\d\d/g

\D是\d 的反面,相当于[^0-9]。
/\D/g

4.2 单词字符 \w
转义符 \w 匹配单词字符。包括:
- 小写字母 a-z
- 大写字母 A-Z
- 数字 0-9
- 下划线 _
等价于 [a-zA-Z0-9_]
/\w/g

/\W/g

4.3 空白字符 \s
转义符 \s匹配空白字符。具体匹配的字符集取决于正则表达式引擎,但大多数至少包括:
- 空格
- tab 制表符
\t - 回车
\r - 换行符
\n - 换页
\f
其他还可能包括垂直制表符(\v)。Unicode自识别引擎通常匹配分隔符类别中的所有字符。然而,技术细节通常并不重要。
/\s/g

/\S/g(大写 s)

4.4 任意字符 .
虽然不是典型的字符转义。. 可以匹配任意1个字符。(除换行符 \n 以外,通过 dotall 修饰符,也可以匹配换行符 \n)
/./g

5 转义
在正则表达式中,有些字符有特殊的含义,我们将在这一章中进行探讨:
|{,}(,)[,]^,$+,*,?\.只在字符类中的字面量。-: 有时是字符类中的特殊字符。
当我们想通过字面意思匹配这些字符时,我们可以再这些字符前面加
\“转义”它们。
/\(paren\)/g

/(paren)/g

/example\.com/g

/example.com/g

/A\+/g

/A+/g

/worth \$5/g

/worth $5/g

5.1 例子
JavaScript 内联注释
/\/\/.*

星号包围的子串
/*[^\*]*\*

第一个和最后一个星号是字面上的,所有他们要用 \* 转义。字符集里面的星号不需要被转义,但为了清楚起见,我还是转义了它。紧跟在字符集后面的星号表示字符集的重复,我们将在后面的章节中对此进行探讨。
6 组
顾名思义,组是用来“组合”正则表达式的组件的。这些组可用于:
- 提取匹配的子集
- 重复分组任意次数
- 参考先前匹配的子字符串
- 增强可读性
- 允许复杂的替换
这一章我们先学组如何工作,之后的章节还会有更多例子。
6.1 捕获组
捕获组用(…)表示。下面是一个解释性的例子:
/a(bcd)e/g
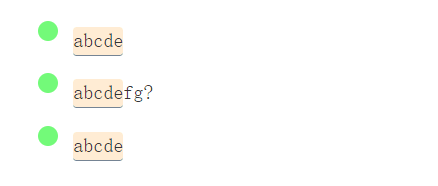
捕获组允许提取部分匹配项。
/\{([^{}]*)\}/g

通过语言的正则函数,您将能够提取括号之间匹配的文本。
捕获组还可以用于对正则表达式进行部分分组,以便于重复。虽然我们将在接下来的章节中详细介绍重复,但这里有一个示例演示了组的实用性。
/a(bcd)+e/g

其他时候,它们用于对正则表达式的逻辑相似部分进行分组,以提高可读性。
/(\d\d\d\d)-W(\d\d)/g

6.2 回溯
回溯允许引用之前捕获的子字符串。
匹配第一组可以使用 \1,匹配第二组可以使用 \2,依此类推…
/([abc])×\1×\1/g

不能使用回溯来减少正则表达式中的重复。它们指的是组的匹配,而不是模式。
/[abc][abc][abc]/g

/[abc]\1\1/g

下面是一个演示常见用例的示例:
/\w+([,|])\w+\1\w+/g

这不能通过重复的字符类来实现。
/\w+[,|]\w+[,|]\w+/g

6.3 非捕获组
非捕获组与捕获组非常相似,只是它们不创建“捕获”。而是采取形式 (?: ...)
非捕获组通常与捕获组一起使用。也许您正在尝试使用捕获组提取匹配的某些部分。而你可能希望使用一个组而不扰乱捕获顺序,这时候你应该使用非捕获组。
6.4 例子
查询字符串参数
/^\?(\w+)=(\w+)(?:&(\w+)=(\w+))*$/g

我们单独匹配第一组键值对,因为这可以让我么使用 & 分隔符, 作为重复组的一部分。
(基础的) HTML 标签
根据经验,不要使用正则表达式来匹配 XML/HTML。不过,我还是提供相关的一个例子:
/<([a-z]+)+>(.*)<\/\1>/gi

姓名
查找:\b(\w+) (\w+)\b
替换:
在替换操作,经常使用 2;捕获使用
\1,\2
替换之前
John Doe
Jane Doe
Sven Svensson
Janez Novak
Janez Kranjski
Tim Joe
替换之后
Doe, John
Doe, Jane
Svensson, Sven
Novak, Janez
Kranjski, Janez
Joe, Tim
回溯和复数
查找: \bword(s?)\b
替换: phrase$1
替换之前
This is a paragraph with some words.
Some instances of the word "word" are in their plural form: "words".
替换之后
This is a paragraph with some phrases.
Yet, some are in their singular form: "phrase".
7 重复
重复是一个强大而普遍的正则表达式特性。在正则表达式中有几种表示重复的方法。
7.1 可选项
我们可以使用 ?将某一部分设置成可选的(0或者1次)。
/a?/g

另一个例子:
/https?/g

我们还可以让捕获组和非捕获组编程可选的。
/url: (www\.)?example\.com/g

7.2 零次或者多次
如果我们希望匹配零个或多个标记,可以用 * 作为后缀。
/a*/g

我们的正则表达式甚至匹配一个空字符串。
7.3 一次或者多次
如果我们希望匹配 1 个或多个标记,可以用 + 作为后缀。
/a+/g

7.4 精确的 x 次
如果我们希望匹配特定的标记正好x次,我们可以添加{x}后缀。这在功能上等同于复制粘贴该标记 x 次。
/a{3}/g

下面是匹配大写的六个字符的十六进制颜色代码的例子。
/#[0-9A-F]{6}/g

这里,标记 {6} 应用于字符集 [0-9A-F]。
7.5 最小次和最大次之间
如果我们希望在最小次和最大次之间匹配一个特定标记,可以在这个标记后添加 {min,max}。
/a{2,4}/g

警告
{min,max}中逗号后面不要有空格。
7.6 最少 x 次
如果我们希望匹配一个特定的标记最少 x 次,可以在标记后添加 {x,}。 和 {min, max} 类似,只是没有上限了。
/a{2,}/g

7.7 贪婪模式的注意事项
正则表达式默认使用贪婪模式。在贪婪模式下,会尽可能多的匹配符合要求的字符。
/a*/g

/".*"/g

在**重复操作符(?,*,+,...)**后面添加 ?,可以让匹配变“懒”。
/".*?"/g

在这里,这也可以通过使用[^"]代替。(这是最好的做法)。
/"[^"]*"/g

懒惰,意味着只要条件满足,就立即停止;但贪婪意味着只有条件不再满足才停止。
-Andrew S on StackOverflow
/<.+>/g

/<.+?>/g

7.8 例子
比特币地址
/([13][a-km-zA-HJ-NP-Z0-9]{26,33})/g(思考: {26,33}?呢)

Youtube 视频
/(?:https?:\/\/)?(?:www\.)?youtube\.com\/watch\?.*?v=([^&\s]+).*/gm

我们可以使用锚点调整表达式不让它匹配最后一个不正确的链接,之后我们会接触到。
8 交替
交替允许匹配几个短语中的一个。这比仅限于单个字符的字符组更加强大。
使用管道符号 | 把多个短语之间分开
/foo|bar|baz/g

匹配 foo, bar, 和 baz 中的一个。
如果正则中只有一部分需要“交替”,可以使用组进行包裹,捕获组和非捕获组都可以。
/Try (foo|bar|baz)/g

Try 后面跟着 foo, bar, 和 baz 中的一个。
匹配 100-250 中间的数字:
/1\d\d|2[0-4]\d|250/g

这个可以使用 Regex Numeric Range Generator 工具生成。
例子
十六进制颜色
让我们改进一下之前十六进制颜色匹配的例子。
/#[0-9A-F]{6}|[0-9A-F]{3}

[0-9A-F]{6} 要放在[0-9A-F]{3}的前面,这一点非常重要。否则:
/#([0-9A-F]{3}|[0-9A-F]{6})/g

小提示
正则表达式引擎是从左边到右边的尝试交替的。
罗马数字
/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/g

9 修饰符
修饰符允许我们把正则表达式分成不同的 "模式"。
修饰符是 /pattern/ 后面的部分。
不同引擎支持不同的修饰符。在这里我们只讨论最常见修饰符。
9.1 全局修饰符(g)
到现在为止,所有的例子都设置了全局修饰符。如果不启用全局修饰符,正则表达式匹配第一个以后将不再匹配其他任何字符。
/[aeiou]/g

/[aeiou]/

9.2 不区分大小写修饰符(i)
顾名思义,启用这个修饰符会使正则在匹配时不区分大小写。
/#[0-9A-F]{6}/i

/#[0-9A-F]{6}/
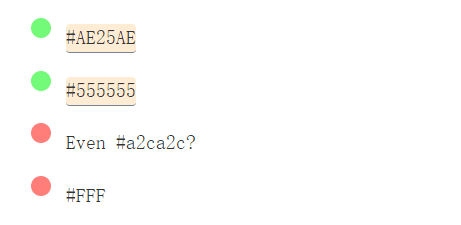
/#[0-9A-Fa-f]{6}/

9.3 多行模式修饰符(m)
有限支持
在 Ruby 中,m 修饰符是执行其他的函数。
多行修饰符与正在在处理包含换行符的“多行”字符串时对锚点的处理有关。默认情况下,/^foo$/只匹配 “foo”。
我们可能希望它在多行字符串中的一行也能匹配 foo。
我们拿 "bar\nfoo\nbaz" 举例子:
bar foo baz
如果没有 m 修饰符,上面的字符串会被当做单行 bar\nfoo\nbaz, 正则表达式 ^foo$ 匹配不到任何字符。
如果有 m 修饰符,上面的字符串会被当做 3 行。 ^foo$ 可以匹配到中间那一行。
9.4 Dot-all修饰符 (s)
有限支持
ES2018 之前的 JavaScript 不支持这个修饰符。 Ruby 也不支持这个修饰,而是用 m 表示。
.通常匹配除换行符以外的任何字符。使用dot all修饰符后,它也可以匹配换行符。
10 锚点
锚点本身不匹配任何东西。但是,他们会限制匹配出现的位置。
你可以把锚点当做是 "不可见的字符"。
10.1 行首 ^
在正则开始时插入^ 号,使正则其余部分必须从字符串开始的地方匹配。你可以把它当成始终要在字符串开头匹配一个不可见的字符。
/^p/g

10.2 行尾
在正则结尾时插入$ 号, 类似于行首符。你可以把它当成始终要在字符串结尾匹配一个不可见的字符。
/p$/g

^和$锚点经常一起使用,以确保正则和字符串整个匹配,而不仅仅是部分匹配。
/^p$/g

让我们回顾一下重复中的一个例子,并在正则的末尾添加两个锚点。
/^https?$/g

如果没有这 2 个锚点, http/2 和 shttp 也会被匹配。
10.3 字边界 \b
字边界是一个字符和非词字符之间的位置。
字边界锚点 \b,匹配字符和非词字符之间存在的假想不可见字符。
/\bp/g

提示
字符包括
a-z,A-Z,0-9, 和_.
/\bp\b/g

/\bcat\b/g

还有一个非字边界锚 \B。
顾名思义,它匹配除字边界之外的所有内容。
/\Bp/g

/\Bp\B/g

小提示
^…$和\b…\b是常见的模式,您几乎总是需要这 2 个防止意外匹配。
10.4 例子
尾部空格
/\s+$/gm

markdown 标题
/^## /gm

没有锚点:
/## /gm

11 零宽断言(lookaround)
零宽断言可用于验证条件,而不匹配任何文本。
你只能看,不能动。
- 先行断言(lookhead)
- 正向
(?=…) - 负向
(?!…)
- 正向
- 先行断言(lookbehind)
- 正向
(?<=…) - 负向
(?<!…)
- 正向
11.1 先行断言(lookhead)
正向(positive)
/_(?=[aeiou])/g

注意后面的字符是如何不匹配的。可以通过正面前看得到证实。
/(.+)_(?=[aeiou])(?=\1)/g

正则引擎在 _ 使用了 (?=[aeiou]) 和 (?=\1) 进行检查。
/(?=.*#).*/g

负向(Negative)
/_(?![aeiou])/g

/^(?!.*#).*$/g

如果没有锚点,将匹配每个示例中没有#的部分。
负向的先行断言常常用于防止匹配特定短语。
/foo(?!bar)/g

/---(?:(?!---).)*---/g

11.2 例子
密码验证
/^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[a-zA-Z]).{8,}$/

零宽断言可用于验证多个条件。
带引号的字符串
/(['"])(?:(?!\1).)*\1/g

如果没有先行断言,我们最多只能做到这样:
/(['"])[^'"]*\1/g

12 进阶例子
JavaScript 注释
/\/\*[\s\S]*?\*\/|\/\/.*/g

[\s\S]是一种匹配任何字符(包括换行符)的技巧。我们避免使用dot-all 修饰符,因为我们需要使用. 表示单行注释。
24小时时间
/^([01]?[0-9]|2[0-3]):[0-5][0-9](:[0-5][0-9])?$/g

IP 地址
/\b(?:(?:2(?:[0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9])\.){3}(?:(?:2([0-4][0-9]|5[0-5])|[0-1]?[0-9]?[0-9]))\b/g

元标签
/<Example source="(.*?)" flags="(.*?)">/gm

替换: <Example regex={/$1/$2}>
浮点数
- 可选符号
- 可选整数部分
- 可选小数部分
- 可选指数部分
/^([+-]?(?=\.\d|\d)(?:\d+)?(?:\.?\d*))(?:[eE]([+-]?\d+))?$/g

正向的先行断言 (?=\.\d|\d) 确保不会匹配 ..
HSL颜色
从0到360的整数
/^0*(?:360|3[0-5]\d|[12]?\d?\d)$/g

百分比
/^(?:100(?:\.0+)?|\d?\d(?:\.\d+)?)%$/g

HSL 和 百分比
/^hsl\(\s*0*(?:360|3[0-5]\d|[12]?\d?\d)\s*(?:,\s*0*(?:100(?:\.0+)?|\d?\d(?:\.\d+)?)%\s*){2}\)$/gi

13 下一步
如果你像进一步学习正则表达式及其工作原理:
- awesome-regex
regextag on StackOverflow- StackOverflow RegEx FAQ
- r/regex
- RexEgg
- Regular-Expressions.info
- Regex Crossword
- Regex Golf
谢谢阅读!添加微信:手边字节
相关推荐
-
专门为初学者编写的正则表达式入门教程
这是一篇翻译文章.我学过很多次正则表达式,总是学了忘,忘了学,一到用的时候还是只能靠搜索引擎. 这回看到这个正则教程,感觉非常惊喜.尝试翻译了一遍,译得不好,大家可以看原文,很容易理解. 原文地址:https://refrf.shreyasminocha.me/ 1 介绍 正则表达式允许定义一种模式,并通过这种模式针对字符串执行对应的操作.与模式匹配的子字符串称为"匹配". 正则表达式是定义搜索模式的一串字符. 正则表达式主要用在如下场景: 输入验证 查找替换操作 高级字符串操作 文件
-

PHP正则表达式入门教程(推荐)
思维导图 点击下图,可以看具体内容! 介绍 正则表达式,大家在开发中应该是经常用到,现在很多开发语言都有正则表达式的应用,比如javascript,java,.net,php等等,我今天就把我对正则表达式的理解跟大家唠唠,不当之处,请多多指教! 定位 我们什么时候使用正则表达式呢?不是所有的字符操作都用正则就好了,php在某些方面用正则反而影响效率.当我们遇到复杂文本数据的解析时候,用正则是比较好的选择. 优点 正则表达式在处理复杂字符操作的时候,可以提高工作效率,也在一定程度节省你的代码量.
-
MySQL正则表达式入门教程
我们知道,在SQL之中,可以用 like 这个谓词(表达式) 来进行模糊检索,并支持 %,?,_等占位符.但是,这个模糊检索的功能有很多限制,简单来说就是太模糊了.在MySQL中提供了 REGEXP 关键字来支持正则表达式,当然,只是一些很简单的正则啦.首先,我们构造一些测试数据. 复制代码 代码如下: -- 建表USE test;DROP TABLE IF EXISTS t_regcustomer;CREATE TABLE t_regcustomer ( id INT(10) AUTO_INC
-
学习正则表达式30分钟入门教程(第二版)
由于本人内容过多排版比较乱,推荐大家浏览单独网页版 http://www.jb51.net/tools/zhengze.html 本文目标 30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以在自己的程序或网页里使用它. 如何使用本教程 最重要的是--请给我30分钟,如果你没有使用正则表达式的经验,请不要试图在30秒内入门--除非你是超人 :) 别被下面那些复杂的表达式吓倒,只要跟着我一步一步来,你会发现正则表达式其实并没有你想像中的那么困难.当然,如果你看完了这篇教程之后,发现
-
正则表达式30分钟入门教程 v2.1版
运行下面的代码就可以看到 正则表达式30分钟入门教程 h1 {text-align:center} p {text-indent:2em; line-height:140%; margin:auto 10px} span {margin:3px} table {margin:auto; border-style:solid; border-width:1px 1px 0 0; border-color:gray} td, th {border-style:solid; border-width:
-
30分钟就入门的正则表达式基础教程
本文目标30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以在自己的程序或网页里使用它. 如何使用本教程 最重要的是--请给我30分钟,如果你没有使用正则表达式的经验,请不要试图在30秒内入门--除非你是超人 :) 别被下面那些复杂的表达式吓倒,只要跟着我一步一步来,你会发现正则表达式其实并没有你想像中的那么困难.当然,如果你看完了这篇教程之后,发现自己明白了很多,却又几乎什么都记不得,那也是很正常的--我认为,没接触过正则表达式的人在看完这篇教程后,能把提到过的语法记住80%以
-
PHP入门教程之正则表达式基本用法实例详解(正则匹配,搜索,分割等)
本文实例讲述了PHP正则表达式基本用法.分享给大家供大家参考,具体如下: Demo1.php <?php //尝试着写第一个正则表达式 //第一个参数,表示模式(就是和字符串去比较,匹配) //第二个参数,表示字符串 //如果整个函数模式和字符串比较后匹配了,那么返回真(true)1,否则返回假(false)0 //什么叫匹配,就是一个一个的比较过去 //按照什么规则??按照模式来匹配 //只要模式全部通过,那么就通过 //匹配和相等是两个概念 //因为目前的模式是一个整体,php //所以,字
-
Python入门教程(二十九)Python的RegEx正则表达式
RegEx 或正则表达式是形成搜索模式的字符序列. RegEx 可用于检查字符串是否包含指定的搜索模式. RegEx 模块 Python 提供名为 re 的内置包,可用于处理正则表达式. 导入 re 模块: import re Python 中的 RegEx 导入 re 模块后,就可以开始使用正则表达式了: 实例 检索字符串以查看它是否以 “China” 开头并以 “country” 结尾: import re txt = "China is a great country" x =
-
零基础易语言入门教程(二)之编程思路
易语言简介: 易语言是一门以中文作为程序代码编程语言.以"易"著称.创始人为吴涛.早期版本的名字为E语言.易语言最早的版本的发布可追溯至2000年9月11日.创造易语言的初衷是进行用中文来编写程序的实践.从2000年至今,易语言已经发展到一定的规模,功能上.用户数量上都十分可观. 上一篇跟大家讲了零基础易语言入门教程(一)编写第一个程序,然后接下来大家应该自己把支持库和易语言组件里面的控件全部认真的看一下,下面我直接跟大家分享下易语言简单编程思路. 方法和步骤如下所示: 1.易语言程序
-
Bootstrap零基础入门教程(三)
什么是 Bootstrap? Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架.Bootstrap 是基于 HTML.CSS.JAVASCRIPT 的. 历史 Bootstrap 是由 Twitter 的 Mark Otto 和 Jacob Thornton 开发的.Bootstrap 是 2011 年八月在 GitHub 上发布的开源产品. 写到这里,这篇从零开始学Bootstrap(3)我想写以下几个内容: 1. 基于我对Bootstrap的理解,做一个小小的总结.