C++实现Huffman的编解码
Huffman编码主要是通过统计各元素出现的频率,进而生成编码最终达到压缩的目的。
这里是Huffman树中节点的结构。
typedef struct Tree
{
int freq;//频率
int key;//键值
struct Tree *left, *right;
Tree(int fr=0, int k=0,Tree *l=nullptr, Tree *r=nullptr):
freq(fr),key(k),left(l),right(r){};
}Tree,*pTree;
首先用一个名为freq的hashtable来记录各个元素的频率:
void read(){
int a;
std::ios::sync_with_stdio(false);
while(cin>>a){
if(freq.find(a)==freq.end()) {freq[a]=1;}
else {freq[a]++;}
}
}
Huffman树的构建过程如下代码所示:
void huffman()
{
int i;
string c;
int fr;
auto it = freq.begin();
while(it!=freq.end()){
Tree *pt= new Tree;
pt->key = it->first;
pt->freq = it->second;
it++;
th.Insert(pt);//此处的th为一种优先队列
}
while(true)//构建哈夫曼树
{
Tree *proot = new Tree;
pTree pl,pr;
pl = th.findMin();
th.Delete(0);
if(th.isEmpty()){
th.Insert(pl);
break;
}
pr = th.findMin();
th.Delete(0);
//合并节点
proot->freq = pl->freq + pr->freq;
std::ios::sync_with_stdio(false);
proot->left = pl;
proot->right = pr;
th.Insert(proot);
//合并后再插入
}
string s;
print_Code(th.findMin(), s);
del(th.findMin());
}
其中print_Code和del函数如下:
void print_Code(Tree *proot, string st)//从根节点开始打印,左0右1
{
if(proot == NULL)
return ;
if(proot->left)
{
st +='0';
}
print_Code(proot->left, st);
std::ios::sync_with_stdio(false);
if(!proot->left && !proot->right)
{
cout<<proot->key<<" ";
for(size_t i=0; i<st.length(); ++i){
cout<<st[i];ml+=st[i];
}
cout<<endl;encoded[proot->key]=ml;ml="";
}
st.pop_back();
if(proot->right)
st+='1';
print_Code(proot->right, st);
}
void del(Tree *proot)
{
if(proot == nullptr)
return ;
del(proot->left);
del(proot->right);
delete proot;
}
至此就完成了Huffman的编码。
当然,由于huffman的编码都是0或1,因此需要进行位的表示才能完成压缩。注意,位需要以8个为一组进行写入:
while(in>>a){
int x=atoi(a.c_str());
auto m=encoded.find(x);
//encoded是另外一个哈希表用于记录元素及它的编码
if(m==encoded.end()) continue;
else {
string t=m->second;
ss+=t;
}
}
unsigned char buf = 0;
int count = 0;
int i = 0;
while(ss[i] != '\0')//位写入,8个为一组
{
buf = buf | ((ss[i++]-'0') << (7 - count));
count++;
if (count == 8)
{
count = 0;
fout << buf;
buf = 0;
}
}
if(count != 0)
fout << buf;
至此就完成了Huffman的编码以及压缩,效果十分可观:
当对69.6M的txt文件(其中含有大约10000000个数据)进行压缩时,产生的encoded.bin文件仅为24.6MB:Ubuntu测试环境:

下面进行Huffman解码的解说:
Huffman解码首先是根据编码表进行huffman树的重建:
void decode(){
auto it=decoded.begin();
Tree *p=proot;
while(it!=decoded.end()){
string s=it->first;int t=it->second;int i=0;
while(i<s.length()){
if(s[i]=='0') {
if(proot->left==nullptr) proot->left=new Tree(5);
proot=proot->left;
}
else{
if(proot->right==nullptr) proot->right=new Tree(5);
proot=proot->right;
}
i++;
}
proot->data=t;
proot=p;
it++;
}
}
然后读取bin文件的一系列位:
while (f.get(c)){
stringstream a;
for (int i = 7; i > 0; i--)
a<<((c >> i) & 1);
a<<(c&1);
m+=a.str();//将位转为字符串
}
然后用Huffman树根据左0右1进行查找并输出:
int i=0;Tree *p=proot;
while(i<m.length()){
if(m[i]=='0'&&proot->left!=nullptr)
{proot=proot->left;i++;}
else if(m[i]=='1'&&proot->right!=nullptr)
{proot=proot->right;i++;}
else
{cout<<proot->data<<endl;proot=p;}
}
至此就完成了Huffman树的解码:
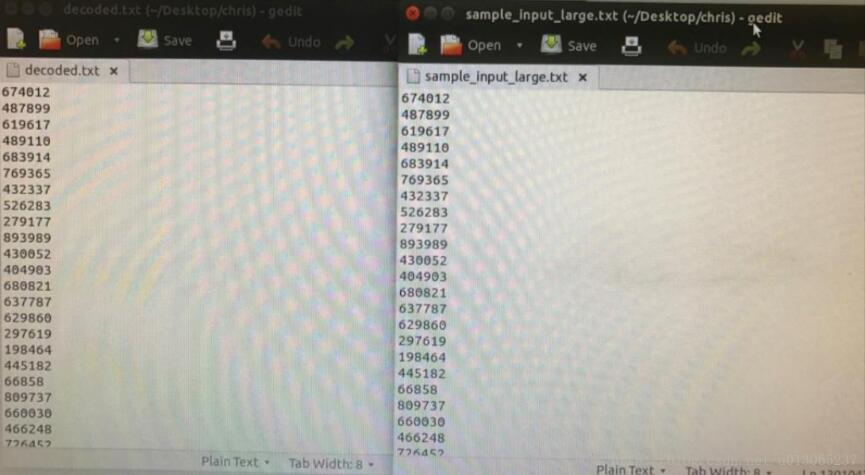
总的来说,Huffman对于大数据的压缩效果是很好的,运行时间也很快,大概需要20s就可以完成对1000000个数据的编码压缩。
难点在于位的写入与读取,花了相当多的精力进行操作。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

解析C++哈夫曼树编码和译码的实现
一.背景介绍: 给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近. 二.实现步骤: 1.构造一棵哈夫曼树 2.根据创建好的哈夫曼树创建一张哈夫曼编码表 3.输入一串哈夫曼序列,输出原始字符 三.设计思想: 1.首先要构造一棵哈夫曼树,哈夫曼树的结点结构包括权值,双亲,左右孩子:假如由n个字符来构造一棵哈夫曼树,则共有结点2n-1个:在构造前,先初始化
-
C++ 哈夫曼树对文件压缩、加密实现代码
在以前写LZW压缩算法的时候,遇到很多难受的问题,基本上都在哈夫曼编码中解决了,虽然写这代码很费神,但还是把代码完整的码出来了,毕竟哈夫曼这个思想确实很牛逼.哈夫曼树很巧妙的解决了当时我在LZW序列化的时候想解决的问题,就是压缩后文本的分割.比如用lzw编码abc,就是1,2,3.但这个在存为文件的时候必须用分割符把1,2,3分割开,非常浪费空间,否则会和12 23 123 产生二义性.而哈夫曼树,将所有char分布在叶节点上,在还原的时候,比如1101110,假设110是叶节点,那么走到110
-
C++实现哈夫曼树算法
如何建立哈夫曼树的,网上搜索一堆,这里就不写了,直接给代码. 1.哈夫曼树结点类:HuffmanNode.h #ifndef HuffmanNode_h #define HuffmanNode_h template <class T> struct HuffmanNode { T weight; // 存储权值 HuffmanNode<T> *leftChild, *rightChild, *parent; // 左.右孩子和父结点 }; #endif /* HuffmanNode
-
基于C++实现的哈夫曼编码解码操作示例
本文实例讲述了基于C++实现的哈夫曼编码解码操作.分享给大家供大家参考,具体如下: 哈夫曼编码是一个通过哈夫曼树进行的一种编码,一般情况下,以字符:'0'与'1'表示.编码的实现过程很简单,只要实现哈夫曼树,通过遍历哈夫曼树,这里我们从每一个叶子结点开始向上遍历,如果该结点为父节点的左孩子,则在字符串后面追加"0",如果为其右孩子,则在字符串后追加"1".结束条件为没有父节点.然后将字符串倒过来存入结点中. C++实现代码如下: #include<iostre
-
C++数据结构之文件压缩(哈夫曼树)实例详解
C++数据结构之文件压缩(哈夫曼树)实例详解 概要: 项目简介:利用哈夫曼编码的方式对文件进行压缩,并且对压缩文件可以解压 开发环境:windows vs2013 项目概述: 1.压缩 a.读取文件,将每个字符,该字符出现的次数和权值构成哈夫曼树 b.哈夫曼树是利用小堆构成,字符出现次数少的节点指针存在堆顶,出现次数多的在堆底 c.每次取堆顶的两个数,再将两个数相加进堆,直到堆被取完,这时哈夫曼树也建成 d.从哈夫曼树中获取哈夫曼编码,然后再根据整个字符数组来获取出现了得字符的编
-
C++实现哈夫曼树编码解码
本文实例为大家分享了C++实现哈夫曼树的编码解码,供大家参考,具体内容如下 代码: #pragma once #include<iostream> #include<stack> using namespace std; #define m 20 stack<int> s; /*哈夫曼树结点类HuffmanNode声明*/ template<class T> class HuffmanNode { private: HuffmanNode<T>
-
C++实现哈夫曼树简单创建与遍历的方法
本文以实例形式讲述了C++实现哈夫曼树简单创建与遍历的方法,比较经典的C++算法. 本例实现的功能为:给定n个带权的节点,如何构造一棵n个带有给定权值的叶节点的二叉树,使其带全路径长度WPL最小. 据此构造出最优树算法如下: 哈夫曼算法: 1. 将n个权值分别为w1,w2,w3,....wn-1,wn的节点按权值递增排序,将每个权值作为一棵二叉树.构成n棵二叉树森林F={T1,T2,T3,T4,...Tn},其中每个二叉树都只有一个权值,其左右字数为空 2. 在森林F中选取根节点权值最小二叉树,
-
C++实现哈夫曼编码
本文实例为大家分享了C++实现哈夫曼编码的具体代码,供大家参考,具体内容如下 #include<iostream> #include<string> #include<vector> #include<algorithm> using namespace std; int Max = 300; class tree{ public: char s; int num; tree *left; tree *right; tree(){ s= '!'; num =
-
C++数据结构与算法之哈夫曼树的实现方法
本文实例讲述了C++数据结构与算法之哈夫曼树的实现方法.分享给大家供大家参考,具体如下: 哈夫曼树又称最优二叉树,是一类带权路径长度最短的树. 对于最优二叉树,权值越大的结点越接近树的根结点,权值越小的结点越远离树的根结点. 前面一篇图文详解JAVA实现哈夫曼树对哈夫曼树的原理与java实现方法做了较为详尽的描述,这里再来看看C++实现方法. 具体代码如下: #include <iostream> using namespace std; #if !defined(_HUFFMANTREE_H
-
C++实现Huffman的编解码
Huffman编码主要是通过统计各元素出现的频率,进而生成编码最终达到压缩的目的. 这里是Huffman树中节点的结构. typedef struct Tree { int freq;//频率 int key;//键值 struct Tree *left, *right; Tree(int fr=0, int k=0,Tree *l=nullptr, Tree *r=nullptr): freq(fr),key(k),left(l),right(r){}; }Tree,*pTree; 首先用一个
-
Java 8实现图片BASE64编解码
前言 Basic编码是标准的BASE64编码,用于处理常规的需求:输出的内容不添加换行符,而且输出的内容由字母加数字组成. 最近做了个Web模版,其中想用Base64背景图.虽然网络上有现成的编码器,但总想自己实现一个.可能很多人不知道,JDK 8新提供的Base64类可以非常方便地处理此项任务:Base64 (Java Platform SE 8 ). 一.先选一张图片 mm.png 二.建立HTML演示文件模版 test.html <!DOCTYPE html> <html>
-
浅谈PHP表单提交(POST&GET&URL编/解码)
POST方法不依赖于URL,不会将传递的参数值显示在地址栏中.另外,POST方法可以没有限制地传递数据到服务器,所有提交的信息在后台传输,用户在浏览器是看不到这一过程的,安全性高. POST方法比较适合用于发送一个保密的或者大量的数据到服务器. GET方法是<form>表单中method属性的默认方法.使用GET方法提交的表单数据被附加到URL上,并作为URL的一部分发送到服务器端. 注意:若要使用GET方法发送表单,URL的长度应限制在1MB字符以内.如果发送的数据量太大,数据将被截断,从而
-
Nodejs进阶之服务端字符编解码和乱码处理
写在前面 在web服务端开发中,字符的编解码几乎每天都要打交道.编解码一旦处理不当,就会出现令人头疼的乱码问题. 不少从事node服务端开发的同学,由于对字符编码码相关知识了解不足,遇到问题时,经常会一筹莫展,花大量的时间在排查.解决问题. 文本先对字符编解码的基础知识进行简单介绍,然后举例说明如何在node中进行编解码,最后是服务端的代码案例.本文相关代码示例可在这里找到. 关于字符编解码 在网络通信的过程中,传输的都是二进制的比特位,不管发送的内容是文本还是图片,采用的语言是中文还是英文.
-
android webp编解码详解
key words:android decode webp sample 当我敲下键盘的时候有种深深的耻辱感,看到android 4.0支持webp格式的图像,于是我狠命的找提供了什么样的api,nnd,硬是没找到,后来抱着试试的心态,用BitmapFactory来读一下,结果没啥问题.得出一个结论,作为一名码农,要敢想敢尝试敢做! webp解码 跟你解码jpg没啥区别,图片放到drawable或者别的地方 然后 Bitmap bmp = BitmapFactory.decodeResource
-
Python3内置模块之json编解码方法小结
Python3内置模块之json编解码方法小结 Python3中我们利用内置模块 json 解码和编码 JSON对象 ,JSON(JavaScript Object Notation)是指定 RFC 7159(废弃了RFC 4627)和 ECMA-404是一种轻量级数据交换格式,受 JavaScript对象文字语法的启发 (虽然它不是JavaScript 1的严格子集).下面为Python对象-->JSON对象的对照关系表. dumps编码 我们利用 dumps 将Python对象编码为 JSO
-
使用Netty进行编解码的操作过程详解
前言 何为编解码,通俗的来说,我们需要将一串文本信息从A发送到B并且将这段文本进行加工处理,如:A将信息文本信息编码为2进制信息进行传输.B接受到的消息是一串2进制信息,需要将其解码为文本信息才能正常进行处理. 上章我们介绍的Netty如何解决拆包和粘包问题,就是运用了解码的这一功能. java默认的序列化机制 使用Netty大多是java程序猿,我们基于一切都是对象的原则,经常会将对象进行网络传输,那么对于序列化操作肯定大家都是非常熟悉的. 一个对象是不能直接进行网络I/O传输的,jdk默认是
-
Python imageio读取视频并进行编解码详解
读视频和写视频一直由于编解码的问题给程序员造成很多麻烦.对此进行了一些探索.用Python读取视频有两种主要方法,分别是基于imageio库和OpenCV,其中OpenCV加上ffmpeg的安装编译很麻烦,推荐大家使用第一种方法,不过大家也可依据自己的需求进行使用. 方法一:使用imageio库 1. 一般imageio库Anconda自带的有,不用我们单独安装,没有安装的可用pip安装或自己下载. imageio使用方法可参考:http://imageio.readthedocs.io/en/
-
Python JSON编解码方式原理详解
这篇文章主要介绍了Python JSON编解码方式原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 概念 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写.在日常的工作中,应用范围极其广泛.这里就介绍python下它的两种编解码方法: 使用json函数 使用 JSON 函数需要导入 json 库:import json.函数含义: 源码解析: # coding= utf-8 #
-
Python3内置模块之json编解码方法小结【推荐】
Python3中我们利用内置模块 json 解码和编码 JSON对象 ,JSON(JavaScript Object Notation)是指定 RFC 7159(废弃了RFC 4627)和 ECMA-404是一种轻量级数据交换格式,受 JavaScript对象文字语法的启发 (虽然它不是JavaScript 1的严格子集).下面为Python对象-->JSON对象的对照关系表. dumps编码 我们利用 dumps 将Python对象编码为 JSON对象 ,当然 dumps 只完成了序列化为st