java8中Stream的使用以及分割list案例
一、Steam的优势
java8中Stream配合Lambda表达式极大提高了编程效率,代码简洁易懂(可能刚接触的人会觉得晦涩难懂),不需要写传统的多线程代码就能写出高性能的并发程序
二、项目中遇到的问题
由于微信接口限制,每次导入code只能100个,所以需要分割list。但是由于code数量可能很大,这样执行效率就会很低。
1.首先想到是用多线程写传统并行程序,但是博主不是很熟练,写出代码可能会出现不可预料的结果,容易出错也难以维护。
2.然后就想到Steam中的parallel,能提高性能又能利用java8的特性,何乐而不为。
三、废话不多说,直接先贴代码,然后再解释(java8分割list代码在标题四)。

1.该方法是根据传入数量生成codes,private String getGeneratorCode(int tenantId)是我根据编码规则生成唯一code这个不需要管,我们要看的是Stream.iterate
2.iterate()第一个参数为起始值,第二个函数表达式(看自己想要生成什么样的流关键在这里),http://write.blog.csdn.net/postedit然后必须要通过limit方法来限制自己生成的Stream大小。parallel()是开启并行处理。map()就是一对一的把Stream中的元素映射成ouput Steam中的 元素。最后用collect收集,
2.1 构造流的方法还有Stream.of(),结合或者数组可直接list.stream();
String[] array = new String[]{"1","2","3"} ;
stream = Stream.of(array)或者Arrays.Stream(array);
2.2 数值流IntStream
int[] array = new int[]{1,2,3};
IntStream.of(array)或者IntStream.ranage(0,3)
3.以上构造流的方法都是已经知道大小,对于通过入参确定的应该图中方法自己生成流。
四、java8分割list,利用StreamApi实现。
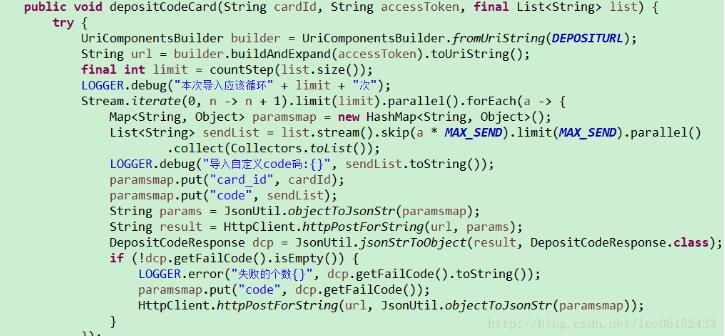
没用java8前代码,做个鲜明对比():
1.list是我的编码集合(codes)。MAX_SEND为100(即每次100的大小去分割list),limit为按编码集合大小算出的本次需要分割多少次。
2.我们可以看到其实就是多了个skip跟limit方法。skip就是舍弃stream前多少个元素,那么limit就是返回流前面多少个元素(如果流里元素少于该值,则返回全部)。然后开启并行处理。通过循环我们的分割list的目标就达到了,每次取到的sendList就是100,100这样子的。
3.因为我这里业务就只需要到这里,如果我们分割之后需要收集之后再做处理,那只需要改写一下就ok;如:
List<List<String>> splitList = Stream.iterate(0,n->n+1).limit(limit).parallel().map(a->{
List<String> sendList = list.stream().skip(a*MAX_SEND).limit(MAX_SEND).parallel().collect(Collectors.toList());
}).collect(Collectors.toList());
五、java8流里好像拿不到下标,所以我才用到构造一个递增数列当下标用,这就是我用java8分割list的过程,比以前的for循环看的爽心悦目,优雅些,性能功也提高了。
如果各位有更好的实现方式,欢迎留言指教。
补充知识:聊聊flink DataStream的split操作
序
本文主要研究一下flink DataStream的split操作
实例
SplitStream<Integer> split = someDataStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});
本实例将dataStream split为两个dataStream,一个outputName为even,另一个outputName为odd
DataStream.split
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/datastream/DataStream.java
@Public
public class DataStream<T> {
//......
public SplitStream<T> split(OutputSelector<T> outputSelector) {
return new SplitStream<>(this, clean(outputSelector));
}
//......
}
DataStream的split操作接收OutputSelector参数,然后创建并返回SplitStream
OutputSelector
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/collector/selector/OutputSelector.java
@PublicEvolving
public interface OutputSelector<OUT> extends Serializable {
Iterable<String> select(OUT value);
}
OutputSelector定义了select方法用于给element打上outputNames
SplitStream
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/datastream/SplitStream.java
@PublicEvolving
public class SplitStream<OUT> extends DataStream<OUT> {
protected SplitStream(DataStream<OUT> dataStream, OutputSelector<OUT> outputSelector) {
super(dataStream.getExecutionEnvironment(), new SplitTransformation<OUT>(dataStream.getTransformation(), outputSelector));
}
public DataStream<OUT> select(String... outputNames) {
return selectOutput(outputNames);
}
private DataStream<OUT> selectOutput(String[] outputNames) {
for (String outName : outputNames) {
if (outName == null) {
throw new RuntimeException("Selected names must not be null");
}
}
SelectTransformation<OUT> selectTransform = new SelectTransformation<OUT>(this.getTransformation(), Lists.newArrayList(outputNames));
return new DataStream<OUT>(this.getExecutionEnvironment(), selectTransform);
}
}
SplitStream继承了DataStream,它定义了select方法,可以用来根据outputNames选择split出来的dataStream;select方法创建了SelectTransformation
StreamGraphGenerator
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/graph/StreamGraphGenerator.java
@Internal
public class StreamGraphGenerator {
//......
private Collection<Integer> transform(StreamTransformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from theExecutionConfig.
int globalMaxParallelismFromConfig = env.getConfig().getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
transform.getOutputType();
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
if (transform.getBufferTimeout() >= 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
}
if (transform.getUid() != null) {
streamGraph.setTransformationUID(transform.getId(), transform.getUid());
}
if (transform.getUserProvidedNodeHash() != null) {
streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());
}
if (transform.getMinResources() != null && transform.getPreferredResources() != null) {
streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());
}
return transformedIds;
}
private <T> Collection<Integer> transformSelect(SelectTransformation<T> select) {
StreamTransformation<T> input = select.getInput();
Collection<Integer> resultIds = transform(input);
// the recursive transform might have already transformed this
if (alreadyTransformed.containsKey(select)) {
return alreadyTransformed.get(select);
}
List<Integer> virtualResultIds = new ArrayList<>();
for (int inputId : resultIds) {
int virtualId = StreamTransformation.getNewNodeId();
streamGraph.addVirtualSelectNode(inputId, virtualId, select.getSelectedNames());
virtualResultIds.add(virtualId);
}
return virtualResultIds;
}
private <T> Collection<Integer> transformSplit(SplitTransformation<T> split) {
StreamTransformation<T> input = split.getInput();
Collection<Integer> resultIds = transform(input);
// the recursive transform call might have transformed this already
if (alreadyTransformed.containsKey(split)) {
return alreadyTransformed.get(split);
}
for (int inputId : resultIds) {
streamGraph.addOutputSelector(inputId, split.getOutputSelector());
}
return resultIds;
}
//......
}
StreamGraphGenerator里头的transform会对SelectTransformation以及SplitTransformation进行相应的处理
transformSelect方法会根据select.getSelectedNames()来addVirtualSelectNode
transformSplit方法则根据split.getOutputSelector()来addOutputSelector
小结
DataStream的split操作接收OutputSelector参数,然后创建并返回SplitStream
OutputSelector定义了select方法用于给element打上outputNames
SplitStream继承了DataStream,它定义了select方法,可以用来根据outputNames选择split出来的dataStream
doc
以上这篇java8中Stream的使用以及分割list案例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
java8从list集合中取出某一属性的值的集合案例
我就废话不多说了,大家还是直接看代码吧~ List<Order> list = new ArrayList<User>(); Order o1 = new Order("1","MCS-2019-1123"); list.add(o1 ); Order o2= new Order("2","MCS-2019-1124"); list.add(o2); Order o3= new Order("
-
详解Java8新特性Stream之list转map及问题解决
List集合转Map,用到的是Stream中Collectors的toMap方法:Collectors.toMap 具体用法实例如下: //声明一个List集合 List<Person> list = new ArrayList(); list.add(new Person("1001", "小A")); list.add(new Person("1002", "小B")); list.add(new Person
-
java8 streamList转换使用详解
一.java8 stream 操作 List<Map<String, Object>> maps 转 Map<String, Object>的两种方法 第一种,实用于数据查询返回的是List<Map<String, Object>> maps 方法一. Map<String, Object>; resultMap = lists .stream() .flatMap(map ->map.entrySet().stream())
-
java8新特性 stream流的方式遍历集合和数组操作
前言: 在没有接触java8的时候,我们遍历一个集合都是用循环的方式,从第一条数据遍历到最后一条数据,现在思考一个问题,为什么要使用循环,因为要进行遍历,但是遍历不是唯一的方式,遍历是指每一个元素逐一进行处理(目的),而并不是从第一个到最后一个顺次处理的循环,前者是目的,后者是方式. 所以为了让遍历的方式更加优雅,出现了流(stream)! 1.流的目的在于强掉做什么 假设一个案例:将集合A根据条件1过滤为子集B,然后根据条件2过滤为子集C 在没有引入流之前我们的做法可能为: public cl
-
java8中Stream的使用以及分割list案例
一.Steam的优势 java8中Stream配合Lambda表达式极大提高了编程效率,代码简洁易懂(可能刚接触的人会觉得晦涩难懂),不需要写传统的多线程代码就能写出高性能的并发程序 二.项目中遇到的问题 由于微信接口限制,每次导入code只能100个,所以需要分割list.但是由于code数量可能很大,这样执行效率就会很低. 1.首先想到是用多线程写传统并行程序,但是博主不是很熟练,写出代码可能会出现不可预料的结果,容易出错也难以维护. 2.然后就想到Steam中的parallel,能提高性能
-

Java8中Stream的一些神操作
Java8对集合提供了一种流式计算的方式,这种风格将要处理的元素集合看 作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如 筛选, 排序,聚合等. Stream API 基本都是返回Stream本身,这样多个操作可以串联成一个管 道, 如同流式风格(fluent style). 这样做可以对操作进行优化, 比 如延迟执行(laziness)和短路( short-circuiting) stream() 为集合创建串行流 parallelStream() 为集合创建并行流 pri
-
Java8中Stream流式操作指南之入门篇
目录 简介 正文 1. 流是什么 2. 老板,上栗子 3. 流的操作步骤 4. 流的特点 5. 流式操作和集合操作的区别: 总结 简介 流式操作也叫做函数式操作,是Java8新出的功能 流式操作主要用来处理数据(比如集合),就像泛型也大多用在集合中一样(看来集合这个小东西还是很关键的啊,哪哪都有它) 下面我们主要用例子来介绍下,流的基操(建议先看下lambda表达式篇,里面介绍的lambda表达式.函数式接口.方法引用等,下面会用到) 正文 1. 流是什么 流是一种以声明性的方式来处理数据的AP
-
Java8中Stream的使用方式
目录 前言: 1. 为什么有经验的老手更倾向于使用Stream 2. Stream 的使用方式 3. Stream 的创建 4. Stream 中间操作 5. Stream 终止操作 6. Stream 特性 前言: 相信有很多刚刚入坑程序员的小伙伴被一些代码搞的很头疼,这些代码让我们既感觉到很熟悉,又很陌生的感觉.我们很多刚入行的朋友更习惯于使用for循环或是迭代器去解决一些遍历的问题,但公司里很多老油子喜欢使用Java8新特性Stream流去做,这样可以用更短的代码实现需求,但是对于不熟悉的
-
Java8中Stream的详细使用方法大全
目录 一.概述 1.使用流的好处 2.流是什么? 二.分类 三.Stream的创建 1.通过 java.util.Collection.stream() 方法用集合创建流 2.使用 java.util.Arrays.stream(T[]array)方法用数组创建流 3.使用 Stream的静态方法:of().iterate().generate() 四.Stream API简介 1.遍历/匹配(foreach/find/match) 2.按条件匹配filter 3.聚合max.min.count
-
java8中Stream的使用示例教程
前言 Java8中提供了Stream对集合操作作出了极大的简化,学习了Stream之后,我们以后不用使用for循环就能对集合作出很好的操作. 本文将给大家详细介绍关于java8 Stream使用的相关内容,下面话不多说了,来一起看看详细的介绍吧 1. 原理 Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator. 原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作: 高级版本的 Stream,用户只要给出需
-
Java8中stream和functional interface的配合使用详解
前言 Java 8 提供了一组称为 stream 的 API,用于处理可遍历的流式数据.stream API 的设计,充分融合了函数式编程的理念,极大简化了代码量. 大家其实可以把Stream当成一个高级版本的Iterator.原始版本的Iterator,用户只能一个一个的遍历元素并对其执行某些操作:高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如"过滤掉长度大于10的字符串"."获取每个字符串的首字母"等,具体这些操作如何应用到每个元素上,
-
Java8中Stream使用的一个注意事项
Stream简介 我们先来看看Java里面是怎么定义Stream的: A sequence of elements supporting sequential and parallel aggregate operations. 我们来解读一下上面的那句话: Stream是元素的集合,这点让Stream看起来用些类似Iterator: 可以支持顺序和并行的对原Stream进行汇聚的操作: 大家可以把Stream当成一个高级版本的Iterator.原始版本的Iterator,用户只能一个一个的遍历
-
Java8中的Stream 流实践操作
目录 1 前言 2 Stream 的分类 3 Stream 的操作 3.1 创建流的方式 3.2 流的中间操作 3.3 流的终止操作 总结 1 前言 Stream 是 java8 中处理集合的抽象概念,可以执行非常复杂的查询.过滤和映射数据等操作.Stream API 提供了一种高效的处理数据方式,Stream 对集合数据的操作可以说是非常的方便.Stream 是流,不是一种数据结构,也不会保存数据,只是一种数据处理方式,从一种数据组织结构到另外一种数据结构. 2 Stream 的分类 按照 S
-
详解java8中的Stream数据流
Stream是java8引入的一个重度使用lambda表达式的API.Stream使用一种类似用SQL语句从数据库查询数据的直观方式来提供一种对Java集合运算和表达的高阶抽象.直观意味着开发者在写代码时只需关注他们想要的结果是什么而无需关注实现结果的具体方式.这一章节中,我们将介绍为什么我们需要一种新的数据处理API.Collection和Stream的不同之处以及如何将StreamAPI应用到我们的编码中. 筛选重复的元素 Stream 接口支持 distinct 的方法, 它会返回一个元素