使用Keras建立模型并训练等一系列操作方式
由于Keras是一种建立在已有深度学习框架上的二次框架,其使用起来非常方便,其后端实现有两种方法,theano和tensorflow。由于自己平时用tensorflow,所以选择后端用tensorflow的Keras,代码写起来更加方便。
1、建立模型
Keras分为两种不同的建模方式,
Sequential models:这种方法用于实现一些简单的模型。你只需要向一些存在的模型中添加层就行了。
Functional API:Keras的API是非常强大的,你可以利用这些API来构造更加复杂的模型,比如多输出模型,有向无环图等等。
这里采用sequential models方法。
构建序列模型。
def define_model():
model = Sequential()
# setup first conv layer
model.add(Conv2D(32, (3, 3), activation="relu",
input_shape=(120, 120, 3), padding='same')) # [10, 120, 120, 32]
# setup first maxpooling layer
model.add(MaxPooling2D(pool_size=(2, 2))) # [10, 60, 60, 32]
# setup second conv layer
model.add(Conv2D(8, kernel_size=(3, 3), activation="relu",
padding='same')) # [10, 60, 60, 8]
# setup second maxpooling layer
model.add(MaxPooling2D(pool_size=(3, 3))) # [10, 20, 20, 8]
# add bianping layer, 3200 = 20 * 20 * 8
model.add(Flatten()) # [10, 3200]
# add first full connection layer
model.add(Dense(512, activation='sigmoid')) # [10, 512]
# add dropout layer
model.add(Dropout(0.5))
# add second full connection layer
model.add(Dense(4, activation='softmax')) # [10, 4]
return model
可以看到定义模型时输出的网络结构。
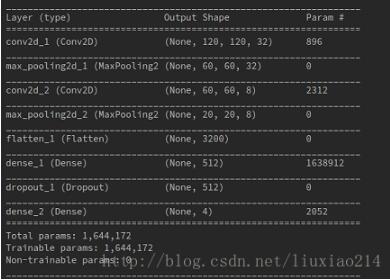
2、准备数据
def load_data(resultpath):
datapath = os.path.join(resultpath, "data10_4.npz")
if os.path.exists(datapath):
data = np.load(datapath)
X, Y = data["X"], data["Y"]
else:
X = np.array(np.arange(432000)).reshape(10, 120, 120, 3)
Y = [0, 0, 1, 1, 2, 2, 3, 3, 2, 0]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
np.savez(datapath, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
return X, Y

3、训练模型
def train_model(resultpath):
model = define_model()
# if want to use SGD, first define sgd, then set optimizer=sgd
sgd = SGD(lr=0.001, decay=1e-6, momentum=0, nesterov=True)
# select loss\optimizer\
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
model.summary()
# draw the model structure
plot_model(model, show_shapes=True,
to_file=os.path.join(resultpath, 'model.png'))
# load data
X, Y = load_data(resultpath)
# split train and test data
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=2)
# input data to model and train
history = model.fit(X_train, Y_train, batch_size=2, epochs=10,
validation_data=(X_test, Y_test), verbose=1, shuffle=True)
# evaluate the model
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', acc)
可以看到训练时输出的日志。因为是随机数据,没有意义,这里训练的结果不必计较,只是练习而已。

保存下来的模型结构:
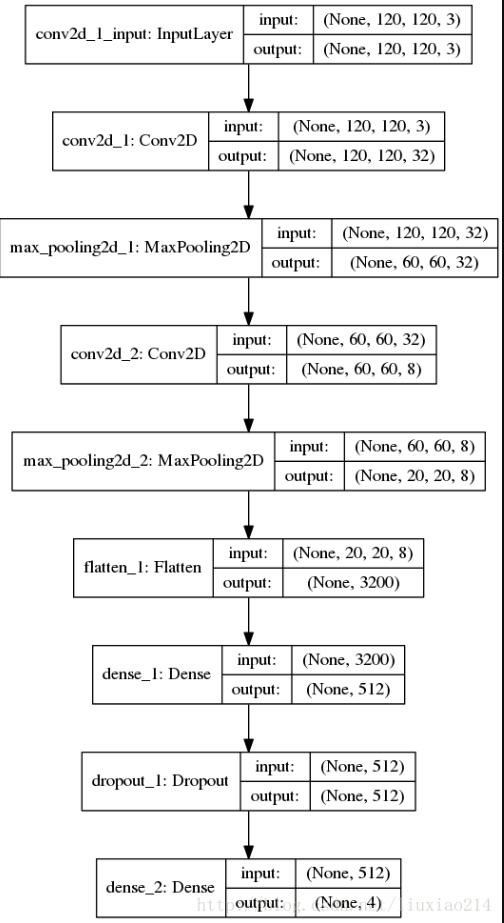
4、保存与加载模型并测试
有两种保存方式
4.1 直接保存模型h5
保存:
def my_save_model(resultpath): model = train_model(resultpath) # the first way to save model model.save(os.path.join(resultpath, 'my_model.h5'))
加载:
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the first way of load model
model2 = load_model(os.path.join(resultpath, 'my_model.h5'))
model2.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
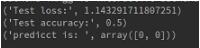
test_loss, test_acc = model2.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model2.predict_classes(X)
print("predicct is: ", y)
4.2 分别保存网络结构和权重
保存:
def my_save_model(resultpath): model = train_model(resultpath) # the secon way : save trained network structure and weights model_json = model.to_json() open(os.path.join(resultpath, 'my_model_structure.json'), 'w').write(model_json) model.save_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
加载:
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the second way : load model structure and weights
model = model_from_json(open(os.path.join(resultpath, 'my_model_structure.json')).read())
model.load_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model.predict_classes(X)
print("predicct is: ", y)

可以看到,两次的结果是一样的。
5、完整代码
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.losses import categorical_crossentropy
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
from keras.optimizers import SGD
from keras.models import model_from_json
from keras.models import load_model
from keras.utils import np_utils
import numpy as np
import os
from sklearn.model_selection import train_test_split
def load_data(resultpath):
datapath = os.path.join(resultpath, "data10_4.npz")
if os.path.exists(datapath):
data = np.load(datapath)
X, Y = data["X"], data["Y"]
else:
X = np.array(np.arange(432000)).reshape(10, 120, 120, 3)
Y = [0, 0, 1, 1, 2, 2, 3, 3, 2, 0]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
np.savez(datapath, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
return X, Y
def define_model():
model = Sequential()
# setup first conv layer
model.add(Conv2D(32, (3, 3), activation="relu",
input_shape=(120, 120, 3), padding='same')) # [10, 120, 120, 32]
# setup first maxpooling layer
model.add(MaxPooling2D(pool_size=(2, 2))) # [10, 60, 60, 32]
# setup second conv layer
model.add(Conv2D(8, kernel_size=(3, 3), activation="relu",
padding='same')) # [10, 60, 60, 8]
# setup second maxpooling layer
model.add(MaxPooling2D(pool_size=(3, 3))) # [10, 20, 20, 8]
# add bianping layer, 3200 = 20 * 20 * 8
model.add(Flatten()) # [10, 3200]
# add first full connection layer
model.add(Dense(512, activation='sigmoid')) # [10, 512]
# add dropout layer
model.add(Dropout(0.5))
# add second full connection layer
model.add(Dense(4, activation='softmax')) # [10, 4]
return model
def train_model(resultpath):
model = define_model()
# if want to use SGD, first define sgd, then set optimizer=sgd
sgd = SGD(lr=0.001, decay=1e-6, momentum=0, nesterov=True)
# select loss\optimizer\
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
model.summary()
# draw the model structure
plot_model(model, show_shapes=True,
to_file=os.path.join(resultpath, 'model.png'))
# load data
X, Y = load_data(resultpath)
# split train and test data
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=2)
# input data to model and train
history = model.fit(X_train, Y_train, batch_size=2, epochs=10,
validation_data=(X_test, Y_test), verbose=1, shuffle=True)
# evaluate the model
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', acc)
return model
def my_save_model(resultpath):
model = train_model(resultpath)
# the first way to save model
model.save(os.path.join(resultpath, 'my_model.h5'))
# the secon way : save trained network structure and weights
model_json = model.to_json()
open(os.path.join(resultpath, 'my_model_structure.json'), 'w').write(model_json)
model.save_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
def my_load_model(resultpath):
# test data
X = np.array(np.arange(86400)).reshape(2, 120, 120, 3)
Y = [0, 1]
X = X.astype('float32')
Y = np_utils.to_categorical(Y, 4)
# the first way of load model
model2 = load_model(os.path.join(resultpath, 'my_model.h5'))
model2.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model2.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model2.predict_classes(X)
print("predicct is: ", y)
# the second way : load model structure and weights
model = model_from_json(open(os.path.join(resultpath, 'my_model_structure.json')).read())
model.load_weights(os.path.join(resultpath, 'my_model_weights.hd5'))
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
test_loss, test_acc = model.evaluate(X, Y, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
y = model.predict_classes(X)
print("predicct is: ", y)
def main():
resultpath = "result"
#train_model(resultpath)
#my_save_model(resultpath)
my_load_model(resultpath)
if __name__ == "__main__":
main()
以上这篇使用Keras建立模型并训练等一系列操作方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Keras实现简单线性回归模型操作
神经网络可以用来模拟回归问题 (regression),实质上是单输入单输出神经网络模型,例如给下面一组数据,用一条线来对数据进行拟合,并可以预测新输入 x 的输出值. 一.详细解读 我们通过这个简单的例子来熟悉Keras构建神经网络的步骤: 1.导入模块并生成数据 首先导入本例子需要的模块,numpy.Matplotlib.和keras.models.keras.layers模块.Sequential是多个网络层的线性堆叠,可以通过向Sequential模型传递一个layer的list来构造该
-
使用Keras预训练好的模型进行目标类别预测详解
前言 最近开始学习深度学习相关的内容,各种书籍.教程下来到目前也有了一些基本的理解.参考Keras的官方文档自己做一个使用application的小例子,能够对图片进行识别,并给出可能性最大的分类. 闲言少叙,开始写代码 环境搭建相关就此省去,网上非常多.我觉得没啥难度 from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image from keras.applications.res
-
Keras 加载已经训练好的模型进行预测操作
使用Keras训练好的模型用来直接进行预测,这个时候我们该怎么做呢?[我这里使用的就是一个图片分类网络] 现在让我来说说怎么样使用已经训练好的模型来进行预测判定把 首先,我们已经又有了model模型,这个模型被保存为model.h5文件 然后我们需要在代码里面进行加载 model = load_model("model.h5") 假设我们自己已经写好了一个load_data函数[load_data最好是返回已经通过了把图片转成numpy的data,以及图片对应的label] 然后我们先
-
使用Keras预训练模型ResNet50进行图像分类方式
Keras提供了一些用ImageNet训练过的模型:Xception,VGG16,VGG19,ResNet50,InceptionV3.在使用这些模型的时候,有一个参数include_top表示是否包含模型顶部的全连接层,如果包含,则可以将图像分为ImageNet中的1000类,如果不包含,则可以利用这些参数来做一些定制的事情. 在运行时自动下载有可能会失败,需要去网站中手动下载,放在"~/.keras/models/"中,使用WinPython则在"settings/.ke
-
使用Keras建立模型并训练等一系列操作方式
由于Keras是一种建立在已有深度学习框架上的二次框架,其使用起来非常方便,其后端实现有两种方法,theano和tensorflow.由于自己平时用tensorflow,所以选择后端用tensorflow的Keras,代码写起来更加方便. 1.建立模型 Keras分为两种不同的建模方式, Sequential models:这种方法用于实现一些简单的模型.你只需要向一些存在的模型中添加层就行了. Functional API:Keras的API是非常强大的,你可以利用这些API来构造更加复杂的模
-
keras中模型训练class_weight,sample_weight区别说明
keras 中fit(self, x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None) 官方文档
-
keras实现调用自己训练的模型,并去掉全连接层
其实很简单 from keras.models import load_model base_model = load_model('model_resenet.h5')#加载指定的模型 print(base_model.summary())#输出网络的结构图 这是我的网络模型的输出,其实就是它的结构图 _________________________________________________________________________________________________
-

Keras保存模型并载入模型继续训练的实现
我们以MNIST手写数字识别为例 import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD # 载入数据 (x_train,y_train),(x_test,y_test) = mnist
-
Keras使用tensorboard显示训练过程的实例
众所周知tensorflow造势虽大却很难用,因此推荐使用Keras,它缺省是基于tensorflow的,但通过修改keras.json也可以用于theano.但是为了能用tensorflow提供的tensorboard,因此建议仍基于tensorflow. 那么问题来了,由于Keras隐藏了tensorflow那令人诟病.可笑至极的graph构建方法,那么如何使用tensorboard呢?一般网站上会告诉你是这样的: 方法一(标准调用方法): 采用keras特有的fit()进行训练,只要在fi
-
Python搭建Keras CNN模型破解网站验证码的实现
在本项目中,将会用Keras来搭建一个稍微复杂的CNN模型来破解以上的验证码.验证码如下: 利用Keras可以快速方便地搭建CNN模型,本项目搭建的CNN模型如下: 将数据集分为训练集和测试集,占比为8:2,该模型训练的代码如下: # -*- coding: utf-8 -*- import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from matplotlib im
-
浅谈keras保存模型中的save()和save_weights()区别
今天做了一个关于keras保存模型的实验,希望有助于大家了解keras保存模型的区别. 我们知道keras的模型一般保存为后缀名为h5的文件,比如final_model.h5.同样是h5文件用save()和save_weight()保存效果是不一样的. 我们用宇宙最通用的数据集MNIST来做这个实验,首先设计一个两层全连接网络: inputs = Input(shape=(784, )) x = Dense(64, activation='relu')(inputs) x = Dense(64,
-
keras做CNN的训练误差loss的下降操作
采用二值判断如果确认是噪声,用该点上面一个灰度进行替换. 噪声点处理:对原点周围的八个点进行扫描,比较.当该点像素值与周围8个点的值小于N时,此点为噪点 . 处理后的文件大小只有原文件小的三分之一,前后的图片内容肉眼几乎无法察觉. 但是这样处理后图片放入CNN中在其他条件不变的情况下,模型loss无法下降,二分类图片,loss一直在8-9之间.准确率维持在0.5,同时,测试集的训练误差持续下降,但是准确率也在0.5徘徊.大概真是需要误差,让优化方法从局部最优跳出来. 使用的activation
-
keras分类模型中的输入数据与标签的维度实例
在<python深度学习>这本书中. 一.21页mnist十分类 导入数据集 from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() 初始数据维度: >>> train_images.shape (60000, 28, 28) >>> len(train_labels) 60000 >>