Python爬虫实现搭建代理ip池
目录
- 前言
- 一、User-Agent
- 二、发送请求
- 三、解析数据
- 四、构建ip代理池,检测ip是否可用
- 五、完整代码
- 总结
前言
在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试。下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池:
本次爬取免费ip代理的网址:http://www.ip3366.net/free/
提示:以下是本篇文章正文内容,下面案例可供参考
一、User-Agent
在发送请求的时候,通常都会做一个简单的反爬。这时可以用fake_useragent模块来设置一个请求头,用来进行伪装成浏览器,下面两种方法都可以。
from fake_useragent import UserAgent
headers = {
# 'User-Agent': UserAgent().random #常见浏览器的请求头伪装(如:火狐,谷歌)
'User-Agent': UserAgent().Chrome #谷歌浏览器
}
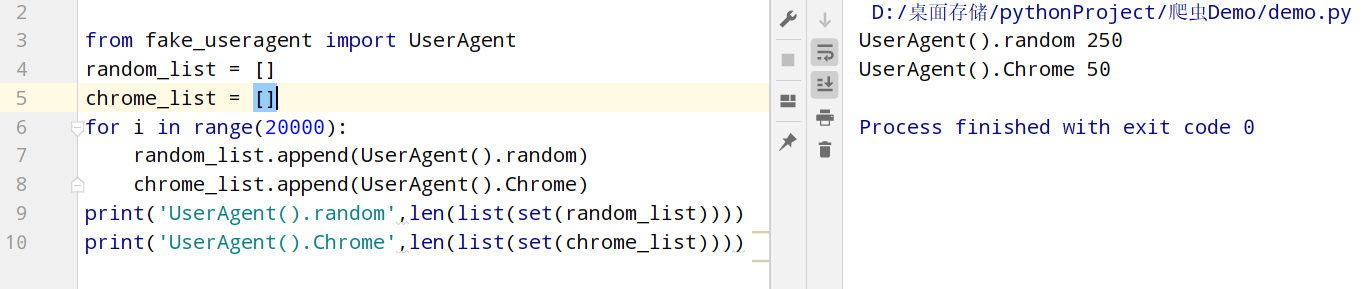
二、发送请求
response = requests.get(url='http://www.ip3366.net/free/', headers=request_header())
# text = response.text.encode('ISO-8859-1')
# print(text.decode('gbk'))
三、解析数据
我们只需要解析出ip、port即可。
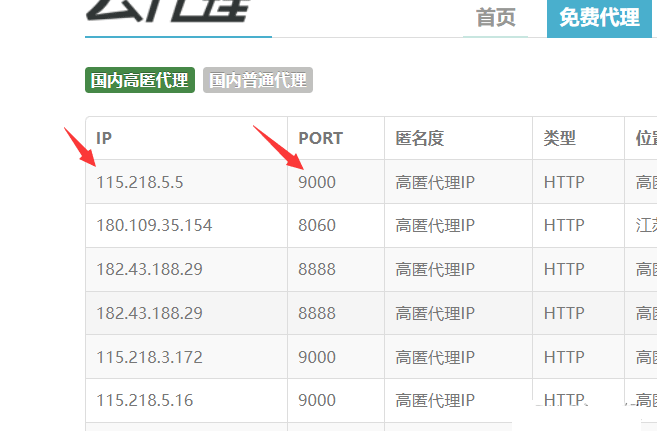

使用xpath解析(个人很喜欢用)(当然还有很多的解析方法,如:正则,css选择器,BeautifulSoup等等)。
#使用xpath解析,提取出数据ip,端口
html = etree.HTML(response.text)
tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')
for td in tr_list:
ip_ = td.xpath('./td[1]/text()')[0] #ip
port_ = td.xpath('./td[2]/text()')[0] #端口
proxy = ip_ + ':' + port_ #115.218.5.5:9000
四、构建ip代理池,检测ip是否可用
#构建代理ip
proxy = ip + ':' + port
proxies = {
"http": "http://" + proxy,
"https": "http://" + proxy,
# "http": proxy,
# "https": proxy,
}
try:
response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #设置timeout,使响应等待1s
response.close()
if response.status_code == 200:
print(proxy, '\033[31m可用\033[0m')
else:
print(proxy, '不可用')
except:
print(proxy,'请求异常')
五、完整代码
import requests #导入模块
from lxml import etree
from fake_useragent import UserAgent
#简单的反爬,设置一个请求头来伪装成浏览器
def request_header():
headers = {
# 'User-Agent': UserAgent().random #常见浏览器的请求头伪装(如:火狐,谷歌)
'User-Agent': UserAgent().Chrome #谷歌浏览器
}
return headers
'''
创建两个列表用来存放代理ip
'''
all_ip_list = [] #用于存放从网站上抓取到的ip
usable_ip_list = [] #用于存放通过检测ip后是否可以使用
#发送请求,获得响应
def send_request():
#爬取7页,可自行修改
for i in range(1,8):
print(f'正在抓取第{i}页……')
response = requests.get(url=f'http://www.ip3366.net/free/?page={i}', headers=request_header())
text = response.text.encode('ISO-8859-1')
# print(text.decode('gbk'))
#使用xpath解析,提取出数据ip,端口
html = etree.HTML(text)
tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')
for td in tr_list:
ip_ = td.xpath('./td[1]/text()')[0] #ip
port_ = td.xpath('./td[2]/text()')[0] #端口
proxy = ip_ + ':' + port_ #115.218.5.5:9000
all_ip_list.append(proxy)
test_ip(proxy) #开始检测获取到的ip是否可以使用
print('抓取完成!')
print(f'抓取到的ip个数为:{len(all_ip_list)}')
print(f'可以使用的ip个数为:{len(usable_ip_list)}')
print('分别有:\n', usable_ip_list)
#检测ip是否可以使用
def test_ip(proxy):
#构建代理ip
proxies = {
"http": "http://" + proxy,
"https": "http://" + proxy,
# "http": proxy,
# "https": proxy,
}
try:
response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #设置timeout,使响应等待1s
response.close()
if response.status_code == 200:
usable_ip_list.append(proxy)
print(proxy, '\033[31m可用\033[0m')
else:
print(proxy, '不可用')
except:
print(proxy,'请求异常')
if __name__ == '__main__':
send_request()
总结
到此这篇关于Python爬虫实现搭建代理ip池的文章就介绍到这了,更多相关Python代理ip池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python搭建代理IP池实现存储IP的方法
上一文写了如何从代理服务网站提取 IP,本文就讲解如何存储 IP,毕竟代理池还是要有一定量的 IP 数量才行.存储的方式有很多,直接一点的可以放在一个文本文件中,但操作起来不太灵活,而我选择的是 MySQL 数据库,因为数据库便于管理而且功能强大,当然你还可以选择其他数据库,比如 MongoDB.Redis 等. 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(三)-
-
Python搭建代理IP池实现获取IP的方法
使用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差,如果需求较高可以购买付费代理,可用性较好. 因此我们可以自己构建代理池,从各种代理服务网站中获取代理 IP,并
-
Python搭建代理IP池实现接口设置与整体调度
接口模块需要用 API 来提供对外服务的接口,当然也可以直接连数据库来取,但是这样就需要知道数据库的连接信息,不太安全,而且需要配置连接,所以一个比较安全和方便的方式就是提供一个 Web API 接口,通过访问接口即可拿到可用代理 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(二)- 存储 IP Python搭建代理IP池(三)- 检测 IP 添加设置 添加模块开关变
-
Python搭建代理IP池实现检测IP的方法
在获取 IP 时,已经成功将各个网站的代理 IP 获取下来了,然后就需要一个检测模块来对所有的代理进行一轮轮的检测,检测可用就设置为满分,不可用分数就减 1,这样就可以实时改变每个代理的可用情况,在获取有效 IP 的时候只需要获取分数高的 IP 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(二)- 存储 IP Python搭建代理IP池(四)- 接口设置与整体调度 由
-
Python爬虫实现搭建代理ip池
目录 前言 一.User-Agent 二.发送请求 三.解析数据 四.构建ip代理池,检测ip是否可用 五.完整代码 总结 前言 在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试.下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池: 本次爬取免费ip代理的网址:http://www.ip3366.net/free/ 提示:以下是本篇文章正文内容,下面案例可供参考
-
Python爬虫抓取代理IP并检验可用性的实例
经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太频繁了,所以被封IP了. 但是,还是可以去IP巴士试试的,条条大路通罗马嘛,不能吊死在一棵树上. 不废话,上代码. #!/usr/bin/env python # -*- coding:utf8 -*- import urllib2 import time
-
python爬虫设置每个代理ip的简单方法
python爬虫设置每个代理ip的方法: 1.添加一段代码,设置代理,每隔一段时间换一个代理. urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy.假如一个网站它会检测某一段时间某个 IP 的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在捣鬼了,这酸爽! 下面一段代码说明了代理的设置用法. import urllib2 enable_proxy = True proxy_h
-
python 爬虫 批量获取代理ip的实例代码
实例如下所示: import urllib.request import os, re,sys,time try: from StringIO import StringIO except ImportError: from io import StringIO loca = re.compile(r"""ion":"\D+", "ti""") #伪装成浏览器 header = {'User-Agent':
-
Python利用selenium建立代理ip池访问网站的全过程
目录 一.使用selenium前? 1.安装selenium 2.安装浏览器驱动 3.配置环境 二.使用selenium 1.引入库 2.完整代码 总结 一.使用selenium前? 1.安装selenium pip install Selenium 2.安装浏览器驱动 Chrome驱动文件下载:点击下载 3.配置环境 1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以 2.然后配置下系统变量:我的电脑–>属性–>系统设置
-
检测python爬虫时是否代理ip伪装成功的方法
有时候我们的爬虫程序添加了代理,但是我们不知道程序是否获取到了ip,尤其是动态转发模式的,这时候就需要进行检测了,以下是一种代理是否伪装成功的检测方式,这里推介使用亿牛云提供的代码示例. Python¶ requests #! -*- encoding:utf-8 -*- import requests import random # 要访问的目标页面 targetUrl = "http://httpbin.org/ip" # 要访问的目标HTTPS页面 # targetUrl = &