python机器学习Logistic回归原理推导
目录
- 前言
- Logistic回归原理与推导
- sigmoid函数
- 目标函数
- 梯度上升法
- Logistic回归实践
- 数据情况
- 训练算法
- 算法优缺点
前言
Logistic回归涉及到高等数学,线性代数,概率论,优化问题。本文尽量以最简单易懂的叙述方式,以少讲公式原理,多讲形象化案例为原则,给读者讲懂Logistic回归。如对数学公式过敏,引发不适,后果自负。
Logistic回归原理与推导
Logistic回归中虽然有回归的字样,但该算法是一个分类算法,如图所示,有两类数据(红点和绿点)分布如下,如果需要对两类数据进行分类,我们可以通过一条直线进行划分(w0 * x0 + w1 * x1+w2 * x2)。当新的样本(x1,x2)需要预测时,带入直线函数中,函数值大于0,则为绿色样本(正样本),否则为红样本(负样本)。
推广到高维空间中,我们需要得到一个超平面(在二维是直线,在三维是平面,在n维是n-1的超平面)切分我们的样本数据,实际上也就是求该超平面的W参数,这很类似于回归,所以取名为Logistic回归。

sigmoid函数
当然,我们不直接使用z函数,我们需要把z值转换到区间[0-1]之间,转换的z值就是判断新样本属于正样本的概率大小。 我们使用sigmoid函数完成这个转换过程,公式如下。通过观察sigmoid函数图,如图所示,当z值大于0时,σ值大于0.5,当z值小于0时,σ值小于于0.5。利用sigmoid函数,使得Logistic回归本质上是一个基于条件概率的判别模型。
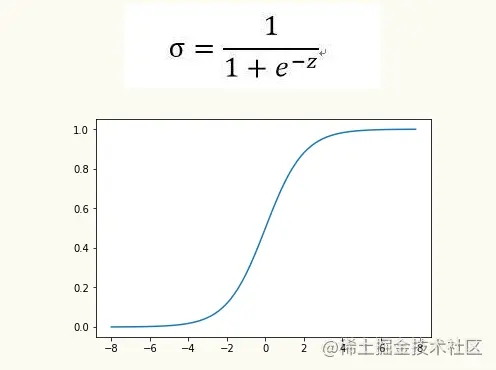
目标函数
其实,我们现在就是求W,如何求W呢,我们先看下图,我们都能看出第二个图的直线切分的最好,换句话说,能让这些样本点离直线越远越好,这样对于新样本的到来,也具有很好的划分,那如何用公式表示并计算这个目标函数呢?

这时就需要这个目标函数的值最大,以此求出θ。
梯度上升法
在介绍梯度上升法之前,我们看一个中学知识:求下面函数在x等于多少时,取最大值。
解:求f(x)的导数:2x,令其为0,求得x=0时,取最大值为0。但在函数复杂时,求出导数也很难计算函数的极值,这时就需要使用梯度上升法,通过迭代,一步步逼近极值,公式如下,我们顺着导数的方向(梯度)一步步逼近。
利用梯度算法计算该函数的x值:
def f(x_old):
return -2*x_old
def cal():
x_old = 0
x_new = -6
eps = 0.01
presision = 0.00001
while abs(x_new-x_old)>presision:
x_old=x_new
x_new=x_old+eps*f(x_old)
return x_new
-0.0004892181072978443
Logistic回归实践
数据情况
读入数据,并绘图显示:
def loadDataSet():
dataMat = [];labelMat = []
fr = open('数据/Logistic/TestSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
训练算法
利用梯度迭代公式,计算W:
def sigmoid(inX):
return 1.0/(1 + np.exp(-inX))
def gradAscent(dataMatIn, labelMatIn):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(labelMatIn).transpose()
m,n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights)
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights
通过计算的weights绘图,查看分类结果
算法优缺点
- 优点:易于理解和计算
- 缺点:精度不高
以上就是python机器学习Logistic回归原理推导的详细内容,更多关于python机器学习Logistic回归的资料请关注我们其它相关文章!
相关推荐
-

Python语言描述机器学习之Logistic回归算法
本文介绍机器学习中的Logistic回归算法,我们使用这个算法来给数据进行分类.Logistic回归算法同样是需要通过样本空间学习的监督学习算法,并且适用于数值型和标称型数据,例如,我们需要根据输入数据的特征值(数值型)的大小来判断数据是某种分类或者不是某种分类. 一.样本数据 在我们的例子中,我们有这样一些样本数据: 样本数据有3个特征值:X0X0,X1X1,X2X2 我们通过这3个特征值中的X1X1和X2X2来判断数据是否符合要求,即符合要求的为1,不符合要求的为0. 样本数据分类存放在一个
-
Python基于Logistic回归建模计算某银行在降低贷款拖欠率的数据示例
本文实例讲述了Python基于Logistic回归建模计算某银行在降低贷款拖欠率的数据.分享给大家供大家参考,具体如下: 一.Logistic回归模型: 二.Logistic回归建模步骤 1.根据分析目的设置指标变量(因变量和自变量),根据收集到的数据进行筛选 2.用ln(p/1-p)和自变量x1...xp列出线性回归方程,估计出模型中的回归系数 3.进行模型检验.模型有效性检验的函数有很多,比如正确率.混淆矩阵.ROC曲线.KS值 4.模型应用. 三.对某银行在降低贷款拖欠率的数据进行建模 源
-
python代码实现逻辑回归logistic原理
Logistic Regression Classifier逻辑回归主要思想就是用最大似然概率方法构建出方程,为最大化方程,利用牛顿梯度上升求解方程参数. 优点:计算代价不高,易于理解和实现. 缺点:容易欠拟合,分类精度可能不高. 使用数据类型:数值型和标称型数据. 介绍逻辑回归之前,我们先看一问题,有个黑箱,里面有白球和黑球,如何判断它们的比例. 我们从里面抓3个球,2个黑球,1个白球.这时候,有人就直接得出了黑球67%,白球占比33%.这个时候,其实这个人使用了最大似然概率的思想,通俗来讲,
-
python 牛顿法实现逻辑回归(Logistic Regression)
本文采用的训练方法是牛顿法(Newton Method). 代码 import numpy as np class LogisticRegression(object): """ Logistic Regression Classifier training by Newton Method """ def __init__(self, error: float = 0.7, max_epoch: int = 100): ""
-
Python机器学习logistic回归代码解析
本文主要研究的是Python机器学习logistic回归的相关内容,同时介绍了一些机器学习中的概念,具体如下. Logistic回归的主要目的:寻找一个非线性函数sigmod最佳的拟合参数 拟合.插值和逼近是数值分析的三大工具 回归:对一直公式的位置参数进行估计 拟合:把平面上的一些系列点,用一条光滑曲线连接起来 logistic主要思想:根据现有数据对分类边界线建立回归公式.以此进行分类 sigmoid函数:在神经网络中它是所谓的激励函数.当输入大于0时,输出趋向于1,输入小于0时,输出趋向0
-
python机器学习Logistic回归原理推导
目录 前言 Logistic回归原理与推导 sigmoid函数 目标函数 梯度上升法 Logistic回归实践 数据情况 训练算法 算法优缺点 前言 Logistic回归涉及到高等数学,线性代数,概率论,优化问题.本文尽量以最简单易懂的叙述方式,以少讲公式原理,多讲形象化案例为原则,给读者讲懂Logistic回归.如对数学公式过敏,引发不适,后果自负. Logistic回归原理与推导 Logistic回归中虽然有回归的字样,但该算法是一个分类算法,如图所示,有两类数据(红点和绿点)分布如下,如果
-
Python机器学习多层感知机原理解析
目录 隐藏层 从线性到非线性 激活函数 ReLU函数 sigmoid函数 tanh函数 隐藏层 我们在前面描述了仿射变换,它是一个带有偏置项的线性变换.首先,回想下之前下图中所示的softmax回归的模型结构.该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作.如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了.但是,仿射变换中的线性是一个很强的假设. 我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用.在此表示的基础上建立
-
python机器学习逻辑回归随机梯度下降法
目录 写在前面 随机梯度下降法 参考文献 写在前面 随机梯度下降法就在随机梯度上.意思就是说当我们在初始点时想找到下一点的梯度,这个点是随机的.全批量梯度下降是从一个点接着一点是有顺序的,全部数据点都要求梯度且有顺序. 全批量梯度下降虽然稳定,但速度较慢: SGD虽然快,但是不够稳定 随机梯度下降法 随机梯度下降法(Stochastic Gradient Decent, SGD)是对全批量梯度下降法计算效率的改进算法.本质上来说,我们预期随机梯度下降法得到的结果和全批量梯度下降法相接近:SGD的
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并
-
机器学习经典算法-logistic回归代码详解
一.算法简要 我们希望有这么一种函数:接受输入然后预测出类别,这样用于分类.这里,用到了数学中的sigmoid函数,sigmoid函数的具体表达式和函数图象如下: 可以较为清楚的看到,当输入的x小于0时,函数值<0.5,将分类预测为0:当输入的x大于0时,函数值>0.5,将分类预测为1. 1.1 预测函数的表示 1.2参数的求解 二.代码实现 函数sigmoid计算相应的函数值:gradAscent实现的batch-梯度上升,意思就是在每次迭代中所有数据集都考虑到了:而stoGradAscen
-
Python机器学习之逻辑回归
一.题目 1.主题:逻辑回归 2.描述:假设你是某大学招生主管,你想根据两次考试的结果决定每个申请者的录取 机会.现有以往申请者的历史数据,可以此作为训练集建立逻辑回归模型,并用 其预测某学生能否被大学录取. 3.数据集:文件 ex2data1.txt ,第一列.第二列分别表示申请者两次 考试的成绩,第三列表示录取结果(1 表示录取,0 表示不录取). 二.目的 1.理解逻辑回归模型 2.掌握逻辑回归模型的参数估计算法 三.平台 1.硬件:计算机 2.操作系统:WINDOWS 3.编程软件:Py
-
python机器学习基础线性回归与岭回归算法详解
目录 一.什么是线性回归 1.线性回归简述 2.数组和矩阵 数组 矩阵 3.线性回归的算法 二.权重的求解 1.正规方程 2.梯度下降 三.线性回归案例 1.案例概述 2.数据获取 3.数据分割 4.数据标准化 5.模型训练 6.回归性能评估 7.梯度下降与正规方程区别 四.岭回归Ridge 1.过拟合与欠拟合 2.正则化 一.什么是线性回归 1.线性回归简述 线性回归,是一种趋势,通过这个趋势,我们能预测所需要得到的大致目标值.线性关系在二维中是直线关系,三维中是平面关系. 我们可以使用如下模