Mysql InnoDB引擎中的数据页结构详解
目录
- Mysql InnoDB引擎数据页结构
- 一、页的简介
- 二、数据页的结构
- 三、记录在页中的存储结构
- 四、记录头信息
- 1. deleted_flag
- 2. min_rec_flag
- 3. n_owned
- 4. heap_no
- 5. record_type
- 6. next_record
Mysql InnoDB引擎数据页结构
InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构。而学习页结构,是为了更好的学习索引。
一、页的简介
页是 InnoDB 管理存储空间的基本单位,一个页的大小一般是 16kb。
为了达成不同的目的,作者设计了多种类型的页,比如:
- 存放表空间头部信息的页
- 存放 change buffer 信息的页
- 存放 inode 信息的页
- 存放 undo 日志信息的页
- ... ...
然而我们最关心的,还是那些存放进表中那些数据记录是在哪种页上,官方称这种存放记录的页为索引(INDEX)页,但是为了便于理解,本篇暂把它称为数据页。
二、数据页的结构
这数据页也有 16kb 的存储空间,可以大致划分为 7 个部分。

从结构图中可以看到,有些部分的占用字节数是确定的,有的是不确定的。我们最关心的用户存储的记录,在 User Records部分。
不过,在一开始生成页的时候,并没有 User Records 部分。当有新的记录插入时,就会从 Free Space部分申请一个记录大小的空间,然后划分到 User Records 部分,直到 Free Space 全部被 User Records 替代,表示这个页已经用完。如果还有新的记录插入,需要申请新的页。
我觉得这里可以把这个数据页当作是书本的页,书页上的内容通常是一行行的呈现,当整个页都用完了,就得翻到下一页(新页)去继续写了。
三、记录在页中的存储结构
那么,User Records 部分里的这些记录,是如何管理的呢?
先来建一张表:
CREATE TABLE pingguo_demo( c1 INT, c2 INT, c3 VARCHAR(10000), PRIMARY KEY (c1) ) CHARSET = ASCII ROW_FORMAT = COMPACT;
这里的指定使用行格式为 COMPACT(引擎中还存在其他的行格式),暂且知道 COMPACT 即可。
当我们在数据库的插入了一条记录后,其实背后的行格式是这样的:

注意这里橙色标识的记录头信息,它又包含了很多重要信息:

- 预留位1:占用 1 比特,没有使用。
- 预留位2:占用 1 比特,没有使用。
- deleted_flag:占用 1 比特,标记该记录是否被删除。
- min_rec_flag:占用 1 比特,在 B+ 树(后面索引会讲到)中每层非 叶子节点中的最小的目录项,都会添加此标记。
- n_owned:一个页面中的记录被分为若干个组,每个组里有一个记录是“大哥”,其他记录都是“小弟”。而这位“大哥”记录的 n_owned 就是所在组的所有记录条数,而小弟们的 n_owned 都是 0
- heap_no:占用 13 比特,表示当前记录在页面堆中的相对位置。
- record_type:占用 3 比特,表示当前记录的类型,0是普通记录,1是 B+树非叶节点的目录项记录,2是 Infimum 记录,3是 Suprememum 记录。
- next_record:占用 16 比特,表示下一条记录的相对位置。
四、记录头信息
现在,向上面新建的表中插入 4 条记录:
INSERT INTO pingguo_demo VALUES (1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');
那么,对应这4条记录的行格式应该为:

注意,这里为了便于记忆,作了简化。另外,记录中的信息实际是二进制位数据,这里为了理解写的是十进制。而且,各条记录在 User Records 中存储是没有空隙的,这里抽象表示。
1. deleted_flag
这个属性用来标记当前记录是否被删除,1 表示被删除,0 表示没有被删除。
嗯?我表里删除了数据居然还在页里。
是的,你以为被删除了,其实还在磁盘上。为什么呢?
因为如果在磁盘上移除这些记录,还要再重新排列其他记录,会带来性能消耗,所以只打了一个删除的标记。
然后,所有的删除的记录会组成一个垃圾链表。而记录在这个链表中所占用的空间称为可重用空间,当后面有新记录插入到表中,它们就可能覆盖掉这些空间。
2. min_rec_flag
在 B+ 树中每层非叶子节点中的最小的目录项,都会添加此标记。这里说的目录项,要后续讲解。
这里4条记录的 min_rec_flag 都是 0,表示都不是 B+ 树非叶子节点中的最小的目录项记录。
3. n_owned
要下一章讲解。
4. heap_no
表示当前记录在页面堆中的相对位置。
上面的4条记录是抽象的描述,实际上这些记录都是一条一条紧密无缝排列在一起的,这就是堆(heap)。

为了方便管理,把一条记录在堆中的相对位置称为 heap_no。
- 在页面前面的记录 heap_no 相对较小
- 在页面后面的记录 heap_no 相对较大
- 每申请一条记录的存储空间时,该记录比物理位置在它之前的那条记录的 heap_no 值大 1
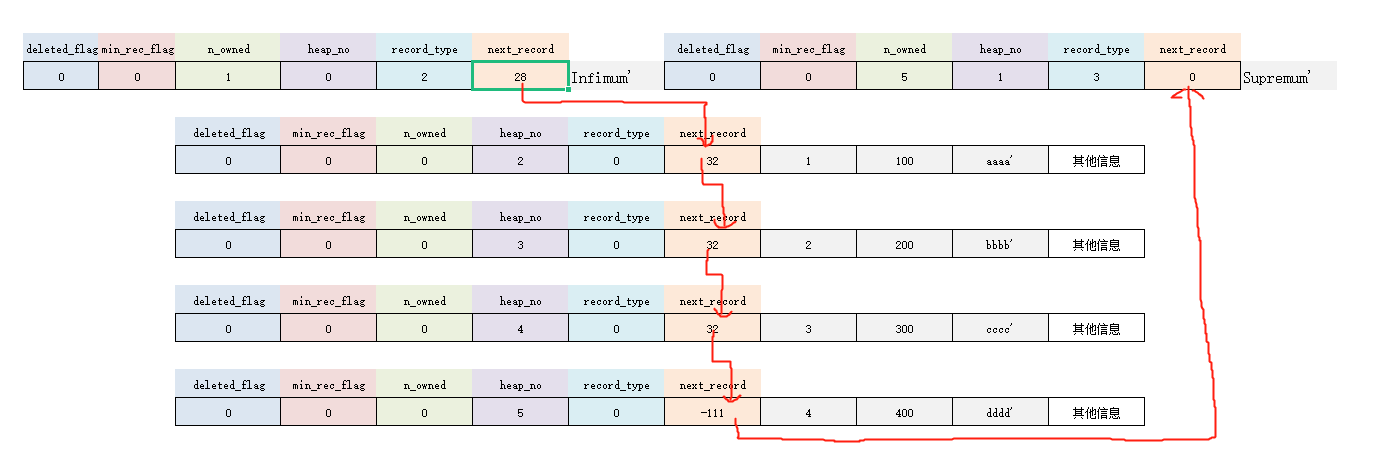
上述 4 条记录的 heap_no 分别为 2、3、4、5,嗯?怎么没有 0 和 1?
虚拟记录-Infimum 和 Supremum
这个在本文第二部分有提到过。其实这2条记录是页里自动添加的:
Infimum:代表页面中的最小记录
Supremum:代表页面中的最大记录
作者规定,无论向页中插入了多少条记录,任何用户记录都比 Infimum 记录大,都比 Supremum 记录小。
这 2 条虚拟记录的结构也很简单。

所以,对于上面插入的 4 条用户记录,还应该加上这2个默认记录,而且位置最靠前。

另外,还需要注意,当堆中记录的 heap_no 值分配后,就不会发生改动。即使删除了堆中的某条记录,这条被删记录的 heap_no 值也仍然不变。
5. record_type
这个属性表示当前记录的类型,共 4 种:
0:表示普通记录1:表示 B+ 树非叶节点的目录项记录2:表示 Infimum 记录3:表示 Supremum 记录
6. next_record
这个属性很重要,表示从当前记录的真实数据到下一条记录的真实数据之间的距离。
- 属性值为正数:说明当前记录的下一条记录在当前记录的后面。
- 属性值为负数:说明当前记录的下一条记录在当前记录的前面。
比如,第 1 条记录的 next_record 值为 32,那么从此记录的真实数据地址向后找 32 字节就是下一条记录的真实数据。再比如,当值为 -111,那么就代表从此记录向前找 111 字节。
很熟悉?没错,就是链表。
- 下一条记录,是指按照主键从小到大排列的下一条。
- Infrimum 记录的下一条记录,就是本页中主键值最小的用户记录。
- 本页主键值最大的用户记录的下一条记录,就是 Supremum 记录。
所以,现在再来重新看下记录之间的示意图,可以用单向链表来描述了:
如果这时候,删掉其中的某条记录,改变的是指针。
本文参考书籍:《mysql是怎样运行的》
以上就是Mysql InnoDB引擎中的数据页结构详解的详细内容,更多关于Mysql InnoDB引擎数据页结构的资料请关注我们其它相关文章!
相关推荐
-

MySQL的InnoDB存储引擎的数据页结构详解
目录 1InnoDB页的概念 2数据页的结构 3记录在页中的存储 4PageDirectory页目录 5FileHeader文件头部 6InnoDB页和记录的关系 7没有索引时查找记录 总结 1 InnoDB页的概念 InnoDB是一个将表中的数据存储在磁盘上的存储引擎,即使我们关闭并重启服务器,数据还是存在.而真正处理数据的过程发生在内存中,所以需要把磁盘中的数据加载到内存中,所以需要把磁盘中的数据加载到内存中.如果处理写入和修改请求,还需要将内存中的内容刷新到磁盘上.而我们知道读写磁盘的速度
-
Mysql InnoDB引擎中页目录和槽的查找过程
目录 Mysql InnoDB引擎页目录 一.页目录和槽 二.页目录的规定 三.页目录查找记录的过程 总结 Mysql InnoDB引擎页目录 一.页目录和槽 接上一篇,现在知道记录在页中按照主键大小顺序串成了单链表. 那么我使用主键查询的时候,最顺其自然的办法肯定是从第一条记录,也就是 Infrimum 记录开始,一直向后找,只要存在总会找到.这种在数据量少的时候还好说,一旦数据多了,遍历耗时一定非常长. 于是,作者又想到了一个好办法,灵感来自于书本中的目录.我们翻书的时候想查找一些内容,就会
-
Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎. MySQL主要存储引擎的区别 MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE.MEMORY(HEAP)等. 主要的几个存储引擎 MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力. MyISAM是Mysql的
-
详解MySql中InnoDB存储引擎中的各种锁
目录 什么是锁 InnoDB存储引擎中的锁 锁的算法 行锁的3种算法 幻像问题 锁的问题 脏读 不可重复读 丢失更新 死锁 什么是锁 现实生活中的锁是为了保护你的私有物品,在数据库中锁是为了解决资源争抢的问题,锁是数据库系统区别于文件系统的一个关键特性.锁机制用于管理对共享资源的并发访. 数据库系统使用锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性 InnoDB存储引擎区别于MyISAM的两个重要特征就是:InnoDB存储引擎支持事务和行级别的锁,MyISAM只支持表级别的锁 In
-
MySQL的存储引擎InnoDB和MyISAM
目录 1.MyISAM底层存储 1.1MyISAM底层存储(非聚集索引方式) 1.2InnoDB底层存储(聚集索引方式) 2.InnoDB与MyISAM简介 3.MyISAM与InnoDB的比较 4.什么时候用MyISAM数据存储引擎?什么时候用InnoDB数据存储引擎? 1.MyISAM底层存储 (非聚集索引方式)与InnoDB底层存储(聚集索引方式) 1.1MyISAM底层存储(非聚集索引方式) Myisam 创建表后生成的文件有三个: frm:创建表的语句 MYD:表里面的数据文件(myi
-
Mysql InnoDB引擎中的数据页结构详解
目录 Mysql InnoDB引擎数据页结构 一.页的简介 二.数据页的结构 三.记录在页中的存储结构 四.记录头信息 1. deleted_flag 2. min_rec_flag 3. n_owned 4. heap_no 5. record_type 6. next_record Mysql InnoDB引擎数据页结构 InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理
-
Android通过json向MySQL中读写数据的方法详解【读取篇】
本文实例讲述了Android通过json向MySQL中读取数据的方法.分享给大家供大家参考,具体如下: 首先 要定义几个解析json的方法parseJsonMulti,代码如下: private void parseJsonMulti(String strResult) { try { Log.v("strResult11","strResult11="+strResult); int index=strResult.indexOf("[");
-
Android通过json向MySQL中读写数据的方法详解【写入篇】
本文实例讲述了Android通过json向MySQL中写入数据的方法.分享给大家供大家参考,具体如下: 先说一下如何通过json将Android程序中的数据上传到MySQL中: 首先定义一个类JSONParser.Java类,将json上传数据的方法封装好,可以直接在主程序中调用该类,代码如下 public class JSONParser { static InputStream is = null; static JSONObject jObj = null; static String j
-
Go语言中的数据竞争模式详解
目录 前言 Go在goroutine中通过引用来透明地捕获自由变量 切片会产生难以诊断的数据竞争 并发访问Go内置的.不安全的线程映射会导致频繁的数据竞争 Go开发人员常在pass-by-value时犯错并导致non-trivial的数据竞争 消息传递(通道)和共享内存的混合使用使代码变得复杂且易受数据竞争的影响 Add和Done方法的错误放置会导致数据竞争 并发运行测试会导致产品或测试代码中的数据竞争 小结 前言 本文主要基于在Uber的Go monorepo中发现的各种数据竞争模式,分析了其
-
MySQL 5.7中的关键字与保留字详解
前言 MySQL和Oracle的关键字还是不尽相同的,在Oracle数据库中,我们的数据表中定义了大量的code字段用来表示主键,但是在MySQL中code是关键字,使用以前的处理方法就有些"水土不服". 下面我们来了解一下MySQL中的关键字和保留字. 什么是关键字和保留字 关键字是指在SQL中有意义的字. 某些关键字(例如SELECT,DELETE或BIGINT)是保留的,需要特殊处理才能用作表和列名称等标识符. 这一点对于内置函数的名称也适用. 如何使用关键字和保留字 非保留关键
-
C++中的数据对齐示例详解
前言 对于C/C++程序员来说,掌握数据对齐是很有必要的,因为只有了解了这个概念,才能知道编译器在什么时候会偷偷的塞入一些字节(padding)到我们的结构体(struct/class),也唯有这样我们才能更好的理解.优化结构体和内存. 几个栗子 看看几个简单的Struct,能猜出他们的SIZE吗?(运行于64Bit win10 vs2017) struct A { char c1; }; struct B { int i1; }; struct C { char c1; int i1; };
-
如何在Vue.js中实现标签页组件详解
前言 标签页组件,即实现选项卡切换,常用于平级内容的收纳与展示. 因为每个标签页的内容是由使用组件的父级控制的,即这部分内容为一个 slot.所以一般的设计方案是,在 slot 中定义多个 div,然后在接到切换消息时,再显示或隐藏相关的 div.这里面就把相关的交互逻辑也编写进来了,我们希望在组件中处理这些交互逻辑,slot 只单纯处理业务逻辑.这可以通过再定义一个 pane 组件来实现,pane 组件嵌在 tabs 组件中. 1 基础版 因为 tabs 组件中的标题是在 pane 组件中定义