pd.DataFrame中的几种索引变换的实现
目录
- 01 索引简介与样例数据
- 02 reindex和rename
- 03 index.map
- 04 set_index与reset_index
- 05 stack与unstack
导读:pandas中最常用的数据结构是DataFrame,而DataFrame相较于嵌套list或者二维numpy数组更好用的原因之一在于其提供了行索引和列名。本文主要介绍行索引的几种变换方式,包括rename与reindex、index.map、set_index与reset_index、stack与unstack等。
惯例开局一张图
01 索引简介与样例数据
Series和DataFrame是pandas中的主要数据结构类型(老版本中曾有三维数据结构Panel,是DataFrame的容器,后被取消),而二者相较于传统的数组或list而言,最大的便利之处在于其提供了索引,DataFrame中还有列标签名,这些都使得在操作一行或一列数据中非常方便,包括在数据访问、数据处理转换等。关于索引的详细介绍可参考前文:python数据科学系列:pandas入门详细教程。
这里,为了便于后文举例解释,给出基本的DataFrame样例数据如下:
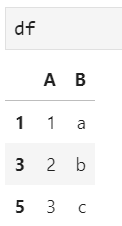
后文将以此作为操作对象,针对索引的几种常用变换进行介绍。
注:这里的索引应广义的理解为既包扩行索引,也包括列标签。
02 reindex和rename
学习pandas之初,reindex和rename容易使人混淆的一组接口,就其具体功能来看:
- reindex执行的是索引重组操作,接收一组标签序列作为新索引,既适用于行索引也适用于列标签名,重组之后索引数量可能发生变化,索引名为传入标签序列
- rename执行的是索引重命名操作,接收一个字典映射或一个变换函数,也均适用于行列索引,重命名之后索引数量不发生改变,索引名可能发生变化
另外二者执行功能和接收参数的套路也是很为相近的,均支持两种变换方式:
- 一种是变换内容+axis指定作用轴(可选0/1或index/columns);
- 另一种是直接用index/columns关键字指定作用轴
具体而言,reindex执行索引重组操作,以新接收的一组标签序列作为索引,当原DataFrame中存在该索引时则提取相应行或列,否则赋值为空或填充指定值。对于前面介绍的示例数据df,以重组行索引为例,两种可选方式为:

注意到原df中行索引为[1, 3, 5],而新重组的目标索引为[1, 2, 3],其中[1, 3]为已有索引直接提取,[2, 4]在原df中不存在,所以填充空值;同时,原df中索引[5]由于不在指定索引中,所以遭舍弃。进一步地,由于重组后可能存在空值,reindex提供了填充空值的可选参数fill_value和method,二者用法与fillna方法一致,前者用于指定固定值填充,后者用于指定填充策略,例如:

rename用法套路与reindex很为相近,但执行功能完全不同,主要用于执行索引重命名操作,接收一个字典或一个重命名规则的函数类型,示例如下:

03 index.map
针对DataFrame中的数据,pandas中提供了一对功能有些相近的接口:map和apply,以及applymap,其中map仅可用于DataFrame中的一列(也即即Series),可接收字典或函数完成单列数据的变换;apply既可用于一列(即Series)也可用于多列(即DataFrame),但仅可接收函数作为参数,当作用于Series时对每个元素进行变换,作用于DataFrame时对其中的每一行或每一列进行变换;而applymap则仅可作用于DataFrame,且作用对象是对DataFrame中的每个元素进行变换。也就是说,三者的最大不同在于作用范围以及变换方式的不同。
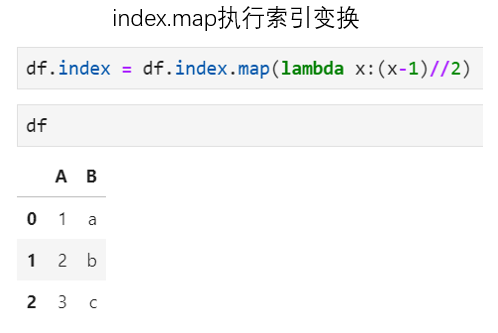
实际上,apply和map还有一个细微区别在于:同样是可作用于单列对象,apply适用于索引这种特殊的单列,而map则不适用。所以,对索引执行变换的另一种可选方式是用map函数,其具体操作方式与DataFrame常规map操作一致,接收一个函数作为参数即可:
04 set_index与reset_index
set_index和reset_index是一对互逆的操作,其中前者用于置位索引——将DataFrame中某一列设置为索引,同时丢弃原索引;而reset_index用于复位索引——将索引加入到数据中作为一列或直接丢弃,可选drop参数。二者是非常常用的一组操作,例如在执行groupby操作后一般会得到一个series类型,此时增加一个reset_index操作即可实现series转换为DataFrame。当然转换的操作不止这一种。

05 stack与unstack
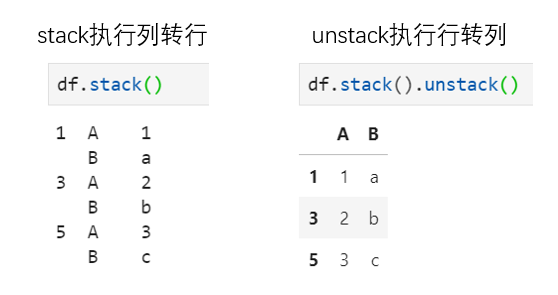
这也是一对互逆的操作,其中stack原义表示堆叠,实现将所有列标签堆叠到行索引中;unstack即解堆,用于将复合行索引中的一个维度索引平铺到列标签中。实际上,二者的操作即是SQL中经典的行转列与列转行,也即在长表与宽表之间转换。
当然,实现unstack操作的方式还有pivot,此处不再展开。
到此这篇关于pd.DataFrame中的几种索引变换的实现的文章就介绍到这了,更多相关pd.DataFrame 索引变换内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对pandas通过索引提取dataframe的行方法详解
一.假设有这样一个原始dataframe 二.提取索引 (已经做了一些操作将Age为NaN的行提取出来并合并为一个dataframe,这里提取的是该dataframe的索引,道理和操作是相似的,提取的代码没有贴上去是为了不显得太繁杂让读者看着繁琐) >>> index = unknown_age_Mr.index.tolist() #记得转换为list格式 三.提取索引对应的原始dataframe的行 使用iloc函数将数据块提取出 >>> age_df.iloc[in
-
pandas.dataframe按行索引表达式选取方法
需要把一个从csv文件里读取来的数据集等距抽样分割,这里用到了列表表达式和dataframe.iloc 先生成索引列表: index_list = ['%d' %i for i in range(df.shape[0]) if i % 3 == 0] 在dataframe中选取 sample_df = df.iloc[index_list] 合起来 sample_df = df.iloc[['%d' %i for i in range(df.shape[0]) if i % 3 == 0]] 各
-
pandas DataFrame索引行列的实现
python版本: 3.6 pandas版本: 0.23.4 行索引 索引行有三种方法,分别是 loc iloc ix import pandas as pd import numpy as np index = ["a", "b", "c", "d"] data = np.random.randint(10, size=(4, 3)) df = pd.DataFrame(data, index=index) "&q
-
Pandas之DataFrame对象的列和索引之间的转化
约定: import pandas as pd DataFrame对象的列和索引之间的转化 我们常常需要将DataFrame对象中的某列或某几列作为索引,或者将索引转化为对象的列.pandas提供了set_index()/reset_index() 来供我们使用. 一.列转化为索引 df1=pd.DataFrame({'X':range(5),'Y':range(5),'S':list("aaabb"),'Z':[1,1,2,2,2]}) df1 代码结果: S X Y Z 0 a 0
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-
pandas将DataFrame的列变成行索引的方法
pandas提供了set_index方法可以将DataFrame的列(多列)变成行索引,通过reset_index方法可以将层次化索引的级别会被转移到列里面. 1.DataFrame的set_index方法 data = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
-
pandas DataFrame 行列索引及值的获取的方法
pandas DataFrame是二维的,所以,它既有列索引,又有行索引 上一篇里只介绍了列索引: import pandas as pd df = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]}) print df # 结果: A B 0 0 3 1 1 4 2 2 5 行索引自动生成了 0,1,2 如果要自己指定行索引和列索引,可以使用 index 和 column 参数: 这个数据是5个车站10天内的客流数据: ridership_df = pd
-
pandas.dataframe中根据条件获取元素所在的位置方法(索引)
在dataframe中根据一定的条件,得到符合要求的某行元素所在的位置. 代码如下所示: df = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],'attr': [22, 33, 22, 44, 66]}, index=[10,20,30,40,50]) print(df) a = df[(df.BoolCol==3)&(df.attr==22)].index.tolist() print(a) df如下所示,以上通过选取"BoolCol"取
-
在Python中pandas.DataFrame重置索引名称的实例
例子: 创建DataFrame ### 导入模块 import numpy as np import pandas as pd import matplotlib.pyplot as plt test = pd.DataFrame({'a':[11,22,33],'b':[44,55,66]}) """ a b 0 11 44 1 22 55 2 33 66 """ 更改列名方法一:rename test.rename(columns={'a':
-

pd.DataFrame中的几种索引变换的实现
目录 01 索引简介与样例数据 02 reindex和rename 03 index.map 04 set_index与reset_index 05 stack与unstack 导读:pandas中最常用的数据结构是DataFrame,而DataFrame相较于嵌套list或者二维numpy数组更好用的原因之一在于其提供了行索引和列名.本文主要介绍行索引的几种变换方式,包括rename与reindex.index.map.set_index与reset_index.stack与unstack等.
-
Oracle CBO优化模式中的5种索引访问方法浅析
本文主要讨论以下几种索引访问方法: 1.索引唯一扫描(INDEX UNIQUE SCAN) 2.索引范围扫描(INDEX RANGE SCAN) 3.索引全扫描(INDEX FULL SCAN) 4.索引跳跃扫描(INDEX SKIP SCAN) 5.索引快速全扫描(INDEX FAST FULL SCAN) 索引唯一扫描(INDEX UNIQUE SCAN) 通过这种索引访问数据的特点是对于某个特定的值只返回一行数据,通常如果在查询谓语中使用UNIQE和PRIMARY KEY索引的列作为条件的
-
MongoDB中哪几种情况下的索引选择策略
目录 一.MongoDB如何选择索引 二.数据准备 三.正则对index的使用 四.$or从句对索引的利用 五.sort对索引的利用 六.搜索数据对索引命中的影响 总结 一.MongoDB如何选择索引 如果我们在Collection建了5个index,那么当我们查询的时候,MongoDB会根据查询语句的筛选条件.sort排序等来定位可以使用的index作为候选索引:然后MongoDB会创建对应数量的查询计划,并分别使用不同线程执行查询计划,最终会选择一个执行最快的index:但是这个选择也不是一
-
Pandas中DataFrame的基本操作之重新索引讲解
目录 Pandas DataFrame之重新索引 1.reindex可以对行和列索引 2.reindex插值处理 Pandas DataFrame重置索引案例 Pandas DataFrame之重新索引 1.reindex可以对行和列索引 默认对行索引,加上关键字columns对列索引. import pandas as pd data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]] df = pd.DataFrame(data,index=['d','b',
-
Pandas DataFrame中的tuple元素遍历的实现
pandas中遍历dataframe的每一个元素 假如有一个需求场景需要遍历一个csv或excel中的每一个元素,判断这个元素是否含有某个关键字 那么可以用python的pandas库来实现. 方法一: pandas的dataframe有一个很好用的函数applymap,它可以把某个函数应用到dataframe的每一个元素上,而且比常规的for循环去遍历每个元素要快很多.如下是相关代码: import pandas as pd data = [["str","ewt"
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
Python 处理 Pandas DataFrame 中的行和列
目录 处理列 处理行 前言: 数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐.我们可以对行/列执行基本操作,例如选择.删除.添加和重命名.在本文中,我们使用的是nba.csv文件. 处理列 为了处理列,我们对列执行基本操作,例如选择.删除.添加和重命名. 列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列. # Import pandas package import pandas as pd # 定义包含员工数据的字典 data =
-
DataFrame中去除指定列为空的行方法
一次,笔者在处理数据时想去除DataFrame中指定列的值为空的这一行,采用了如下做法,但是怎么都没有成功: # encoding: utf-8 import pandas as pd import math import numpy as np data = pd.read_csv('mydata.csv') print len(data) for i in range(len(data)): if (data['导演'][i] == ''): data = data.drop(i) data