python与xml数据的交互详解
目录
- 一 什么是XML?
- 二 XML语法规则
- 1. xml语法规则
- 2. xml与html的区别
- 三 python与xml的交互
- 1. 获取标签对内的数据
- 2. 获取标签属性值
一 什么是XML?
python与json数据的交互详情 在这篇文章中我们介绍了json是一种独立于编程语言和平台的数据存储和交换方式(格式),其实xml和json基本一样,也是一种用于进行数据存储和交换的方式,并且也独立于编程语言和平台。
XML可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言,是从标准通用标记语言(SGML)中简化修改出来的。XML设计的宗旨就是用来传输数据的。
二 XML语法规则
1. xml语法规则
xml的语法规则和html的语法规则很像,但却有着明显的差别。相同的是它们都用标签对来存储数据,但是html的标签都是预定义的,而xml的标签则完全是由编辑者自己定义的。
xml的语法规则如下:
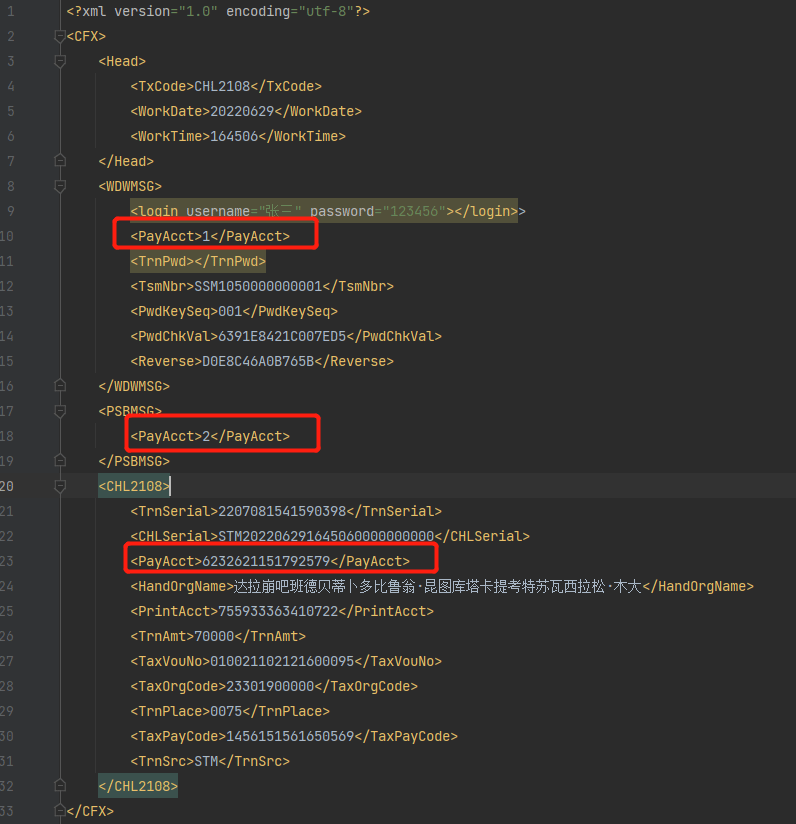
<?xml version="1.0" encoding="utf-8"?>
<CFX>
<Head>
<TxCode>CHL2108</TxCode>
<WorkDate>20220629</WorkDate>
<WorkTime>164506</WorkTime>
</Head>
<WDWMSG>
<login username="张三" password="123456">张三</login>>
<PayAcct>1</PayAcct>
<TrnPwd></TrnPwd>
<TsmNbr>SSM1050000000001</TsmNbr>
<PwdKeySeq>001</PwdKeySeq>
<PwdChkVal>6391E8421C007ED5</PwdChkVal>
<Reverse>D0E8C46A0B765B</Reverse>
</WDWMSG>
<PSBMSG>
<PayAcct>2</PayAcct>
</PSBMSG>
<CHL2108>
<TrnSerial>2207081541590398</TrnSerial>
<CHLSerial>STM202206291645060000000000</CHLSerial>
<PayAcct>6232621151792579</PayAcct>
<HandOrgName>达拉崩吧班德贝蒂卜多比鲁翁·昆图库塔卡提考特苏瓦西拉松·木大</HandOrgName>
<PrintAcct>755933363410722</PrintAcct>
<TrnAmt>70000</TrnAmt>
<TaxVouNo>010021102121600095</TaxVouNo>
<TaxOrgCode>23301900000</TaxOrgCode>
<TrnPlace>0075</TrnPlace>
<TaxPayCode>1456151561650569</TaxPayCode>
<TrnSrc>STM</TrnSrc>
</CHL2108>
</CFX>
xml 必须包含根元素,它是所有其它元素的父元素,如上文中的CFXxml 标签必须是成对出现的,即必须有关关闭标签
<?xml version="1.0" encoding="utf-8"?>
上面这部分是xml的文档声明部分,包含了版本信息和编码方式,是可选的。其他
2. xml与html的区别
xml和html很像,但区别也很大,具体不同如下:
- html标签是预定义的,而xml则是由使用者自己定义
- xml被设计用来传输和存储数据,其焦点是数据的内容
- html被设计用来显示数据,其焦点是数据的外观
三 python与xml的交互
python获取xml的数据信息一般用xml.dom 来解析,具体如下
1. 获取标签对内的数据
比如提取上面xml文件中PayAcct 标签内的数据
from xml.dom import minidom
#mimidom.parse将xml文件解析成DOM文档
data = minidom.parse('../练习文件/XML练习.XML')
print(type(data))
print('*'*50)
#首先利用data.getElementsByTagName('标签名')提取出标签
payacct = data.getElementsByTagName('PayAcct')
print(type(payacct))
for i in range(len(payacct)):
print(payacct[i].toxml())#toxml还原xml格式
print('*'*50)
print('PayAcct标签内容如下:')
#再用 firstChild.data 获取标签数据值
for i in range(len(payacct)):
print(payacct[i].firstChild.data)
如上,minidom.parse()的作用是将xml文档解析成DOM文档,然后通过getElementsTagName()方法提取出标签对,最后通过firstChild.data获取标签内的数据,过程中需要注意的是getElementsTagName()方法提取出标签对返回的结果是一个列表,
结果如下:
>>>
<class 'xml.dom.minidom.Document'>
**************************************************
<class 'xml.dom.minicompat.NodeList'>
<PayAcct>1</PayAcct>
<PayAcct>2</PayAcct>
<PayAcct>6232621151792579</PayAcct>
**************************************************
PayAcct标签内容如下:
1
2
6232621151792579
2. 获取标签属性值
通过getAttribute 获取标签的属性值。如下获取login标签的属性值
<login username="张三" password="123456">张三</login>
from xml.dom import minidom
#mimidom.parse将xml文件解析成DOM文档
data = minidom.parse('../练习文件/XML练习.XML')
#首先利用data.getElementsByTagName('标签名')提取出标签
login = data.getElementsByTagName('login')
print(type(login))
print(login)
for i in range(len(login)):
print(login[i].toxml())
print('*'*50)
#再用 getAttribute('属性值') 获取标签属性值
print('login的属性值如下:')
print(login[0].getAttribute('username'))
print(login[0].getAttribute('password'))
结果如下:
>>>
<class 'xml.dom.minicompat.NodeList'>
[<DOM Element: login at 0x188b60ec048>]
<login password="123456" username="张三">张三</login>
**************************************************
login的属性值如下:
张三
123456
到此这篇关于python与xml数据的交互详解的文章就介绍到这了,更多相关python与xml数据交互内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫基于lxml解决数据编码乱码问题
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索 XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串.数值.时间的匹配以及节点.序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择 XPath
-
详细解读Python中解析XML数据的方法
Python可以使用 xml.etree.ElementTree 模块从简单的XML文档中提取数据. 为了演示,假设你想解析Planet Python上的RSS源.下面是相应的代码: from urllib.request import urlopen from xml.etree.ElementTree import parse # Download the RSS feed and parse it u = urlopen('http://planet.python.org/rss20.xm
-
Python 读取xml数据,cv2裁剪图片实例
下载的数据是pascal voc2012的数据,已经有annotation了,不过是xml格式的,训练的模型是在Google模型的基础上加了两层网络,因此要在原始图像中裁剪出用于训练的部分图像. 另外,在原来给的标注框的基础上,做了点框的移动.最后同类目标存储在同一文件夹中. from __future__ import division import os from PIL import Image import xml.dom.minidom import numpy as np ImgPa
-

Python基于dom操作xml数据的方法示例
本文实例讲述了Python基于dom操作xml数据的方法.分享给大家供大家参考,具体如下: 1.xml的内容为del.xml,如下 <?xml version="1.0" encoding="utf-8"?> <catalog> <maxid>4</maxid> <login username="pytest" passwd='123456'> <caption>Python
-
Python数据提取-lxml模块
知识点: 了解lxml模块和xpath语法的关系: 了解lxml模块的使用场景: 了解lxml模块的安装: 了解 谷歌浏览器xpath helper插件的安装和使用: 掌握xpath语法-基础节点选择语法: 掌握 xpath语法 -节点修饰语法: 掌握xpath语法 - 其他常用语法: 掌握 lmxl模块中使用xpath语法定位元素提取数学值或文本内容: 掌握lxml模块etree.tostring函数的使用: 1.了解lxml模块和xpath语法 对html或xml形式的文本提取特定的内容,就
-
Python xml、字典、json、类四种数据类型如何实现互相转换
之前都是直接拿sax,或dom等库去解析xml文件为Python的数据类型再去操作,比较繁琐,如今在写Django网站ajax操作时json的解析,发现这篇帖子对这几种数据类型的转换操作提供了另一种更简洁的方法,xmltodict和 dicttoxml等库功不可没,几种转换方式也都比较全面,转存一下以备不时之需,感谢原创整理! 注:xml.字典.json.类四种数据的转换,从左到右依次转换,即xml要转换为类时,先将xml转换为字典,再将字典转换为json, 最后将json转换为类. 1.解析x
-
Python 解析简单的XML数据
问题 你想从一个简单的XML文档中提取数据. 解决方案 可以使用 xml.etree.ElementTree 模块从简单的XML文档中提取数据.为了演示,假设你想解析Planet Python上的RSS源.下面是相应的代码: from urllib.request import urlopen from xml.etree.ElementTree import parse # Download the RSS feed and parse it u = urlopen('http://plane
-
Python大数据之使用lxml库解析html网页文件示例
本文实例讲述了Python大数据之使用lxml库解析html网页文件.分享给大家供大家参考,具体如下: lxml是Python的一个html/xml解析并建立dom的库,lxml的特点是功能强大,性能也不错,xml包含了ElementTree ,html5lib ,beautfulsoup 等库. 使用lxml前注意事项:先确保html经过了utf-8解码,即code =html.decode('utf-8', 'ignore'),否则会出现解析出错情况.因为中文被编码成utf-8之后变成 '/
-
Python 3.x基于Xml数据的Http请求方法
1. 前言 由于公司的一个项目是基于B/S架构与WEB服务通信,使用XML数据作为通信数据,在添加新功能时,WEB端与客户端分别由不同的部门负责,所以在WEB端功能实现过程中,需要自己发起请求测试,于是便选择了使用Python编写此脚本.另外由于此脚本最开始希望能在以后发展成具有压力测试的功能,所以除了基本的访问之外,添加了多线程请求. 整个脚本主要涉及到的关于Python的知识点包括: 基于urllib.request的Http访问 多线程 类与方法的定义 全局变量的定义与使用 文件的读取与写
-
python与xml数据的交互详解
目录 一 什么是XML? 二 XML语法规则 1. xml语法规则 2. xml与html的区别 三 python与xml的交互 1. 获取标签对内的数据 2. 获取标签属性值 一 什么是XML? python与json数据的交互详情 在这篇文章中我们介绍了json是一种独立于编程语言和平台的数据存储和交换方式(格式),其实xml和json基本一样,也是一种用于进行数据存储和交换的方式,并且也独立于编程语言和平台.XML可扩展标记语言(英语:Extensible Markup Language,
-
一个Python优雅的数据分块方法详解
目录 1.背景 2.islice 2.1示例 2.2只指定步长 3.iter 3.1常规使用 3.2进阶使用 4.islice 和 iter 组合使用 5.总结 1.背景 看到这个标题你可能想一个分块能有什么难度?还值得细说吗,最近确实遇到一个有意思的分块函数,写法比较巧妙优雅,所以写一个分享. 日前在做需求过程中有一个对大量数据分块处理的场景,具体来说就是几十万量级的数据,分批处理,每次处理100个.这时就需要一个分块功能的代码,刚好项目的工具库中就有一个分块的函数.拿过函数来用,发现还挺好用
-
Python处理文本数据的方法详解
目录 前言 用python处理文本数据 用python处理数值型数据 前言 HI,好久不见,今天是关闭朋友圈的第60天,我是野蛮成长的AC-Asteroid. 人生苦短,我用Python,通过短短两周时间自学,从基础知识到项目实践,在这个过程中深刻体会到这款语言的魅力,今天带来一个有趣的项目,用Python处理文本数据,一起来看看今天的问题吧. 用python处理文本数据 实验目的 熟悉python的基本数据结构,以及文件的输入与输出. 实验数据 利用xxxx年xx机器学习会议的评测数据和评测任
-
AJAX实现JSON与XML数据交换方法详解
目录 1.JS中如何创建和访问JSON对象 2.基于JSON的数据交换 3.基于XML的数据交换 1.JS中如何创建和访问JSON对象 (1)在javascript语言中怎么创建一个json对象,语法是什么? "属性名" : 属性值,"属性名" : 属性值.........的格式! 注意:属性值的数据类型随意:可能是数字,可能是布尔类型,可能是字符串,可能是数组,也可能是一个json对象..... <!DOCTYPE html> <html lan
-
SQL Server解析XML数据的方法详解
本文实例讲述了SQL Server解析XML数据的方法.分享给大家供大家参考,具体如下: --5.读取XML --下面为多种方法从XML中读取EMAIL DECLARE @x XML SELECT @x = ' <People> <dongsheng> <Info Name="Email">dongsheng@xxyy.com</Info> <Info Name="Phone">678945546</
-
Android编程使用sax解析xml数据的方法详解
本文实例讲述了Android编程使用sax解析xml数据的方法.分享给大家供大家参考,具体如下: 随着技术的发展,现在的web已经和以前不同了.web已经逐渐像移动的方向倾斜,作为程序员的确应该拓展一下自己的知识层面.学习各方面的知识,今天就接着前几天的弄一下Android的xml解析,这次就使用sax的方式解析xml.下面就一步一步的来做吧. 1. 编写一个简单的xml <?xml version="1.0" encoding="UTF-8"?> &l
-
python序列化与数据持久化实例详解
本文实例讲述了python序列化与数据持久化.分享给大家供大家参考,具体如下: 数据持久化的方式有: 1.普通文件无格式写入:将数据直接写入到文件中 2.普通序列化写入:json,pickle 3.DBM方式:shelve,dbm 相关内容: json pickle shelve dbm json: 介绍: 按照指定格式[比如格式是字典,那么文件中就是字典]将数据明文写入到文件中,类型是bytes的,比如"中文"就会变成Unicode编码 用法: 首先要导入模块import json
-
Python echarts实现数据可视化实例详解
目录 1.概述 2.安装 3.数据可视化代码 3.1柱状图 3.2折线图 3.3饼图 总结 1.概述 pyecharts 是百度开源的,适用于数据可视化的工具,配置灵活,展示图表相对美观,顺滑. 2.安装 python3环境下的安装: pip3 install pyecharts 3.数据可视化代码 3.1 柱状图 from pyecharts import options as opts from pyecharts.charts import Bar from pyecharts.faker
-
Python处理XML格式数据的方法详解
本文实例讲述了Python处理XML格式数据的方法.分享给大家供大家参考,具体如下: 这里的操作是基于Python3平台. 在使用Python处理XML的问题上,首先遇到的是编码问题. Python并不支持gb2312,所以面对encoding="gb2312"的XML文件会出现错误.Python读取的文件本身的编码也可能导致抛出异常,这种情况下打开文件的时候就需要指定编码.此外就是XML中节点所包含的中文. 我这里呢,处理就比较简单了,只需要修改XML的encoding头部. #!/
-
Python 处理数据的实例详解
Python 处理数据的实例详解 最近用python(3.2的版本)写了根据特定规则,处理数据的一个小程序,用到了一些python常用的基础知识,在此总结一下: 1,python读文件 2,python写文件 3,python的流程控制 4,python的for循环 5,python的集合,或字符串里判断是否存在某个元素 6,python的逻辑或,逻辑与 7,python的正则过滤 8,python的字符串忽略空格,和以某个字符串开头和按某个字符拆分成list python的打开文件的模式: 关