Python3.x+迅雷x 自动下载高分电影的实现方法
快要过年了,大家都在忙些什么呢?一到年底公司各种抢票,备年货,被这过年的气氛一烘,都归心似箭,哪还有心思上班啊。归心似箭=产出低下=一行代码十个错=无聊。于是想起了以前学过一段时间的Python,自己平时也挺爱看电影的,手动点进去看电影详情然后一部一部的去下载太烦了,何不用Python写个自动下载电影的工具呢?诶,这么一想就不无聊了。以前还没那么多XX会员的时候,想看看电影都是去XX天堂去找电影资源,大部分想看的电影还是有的,就它了,爬它!
话说以前玩Python的时候爬过挺多网站的,都是在公司干的(Python不属于公司的业务范围,纯属自己折腾着好玩),我那个负责运维的同事天天跑过来说:你又在爬啥啊,你去看看新闻,某某爬东西又被抓了!出了事你自己负责啊!哎呀我的娘亲,吓的都没继续玩下去了。这个博客是爬取某天堂的资源(具体是哪个天堂下面的代码里会有的),会不会被抓啊?单纯的作为技术讨论,个人练手,不做商业用途应该没事吧?写到这里小手不禁微微颤抖...
得嘞,死就死吧,我不入地狱谁入地狱,先看最终实现效果:
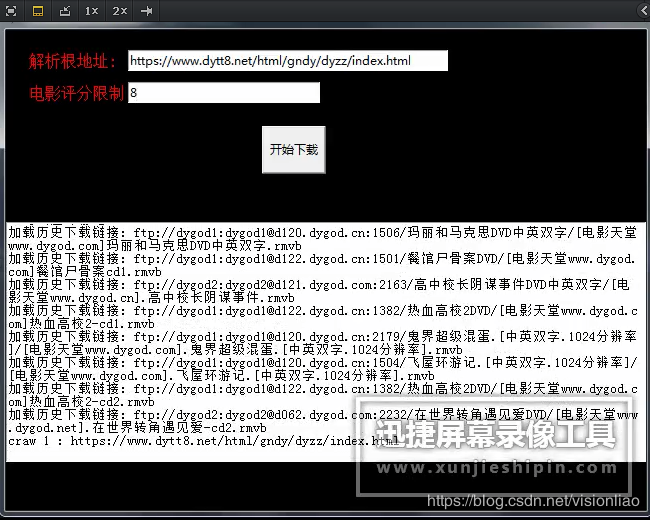
如上,这个下载工具是有界面的(牛皮吧),只要输入一个根地址和电影评分,就可以自动爬电影了,要完成这个工具需要具备以下知识点:
- PyCharm的安装和使用 这个不多说,猿们都懂,不属于猿类的我也没办法科普了,就是个IDE
- tkinter 这是个Python GUI开发的库,图中这个简陋的可怜的界面就是基于TK开发的,不想要界面也可以去掉,丝毫不影响爬电影,加上用户界面可以显得屌一点,当然最主要的是我想学习一点新知识静态网页的分析技巧 相对于动态网站的爬取,静态网站的爬取就显得小菜了,F12会按吧,右键查看网页源代码会吧,通过这些简单的操作就可以查看网页的排版布局规则,然后根据这些规则写爬虫,soeasy
- 数据持久化 已经下载过的电影,下次再爬电影的时候不希望再下载一次吧,那就把下载过的链接存储起来,下载电影之前去比对是否下载过,以过滤重复下载
- 迅雷X的下载安装 这个就更不用多说了,作为当代社会主义有为青年,谁没用过迅雷?谁的硬盘里没有几部动作类型的片子?
差不多就这些了,至于实现的技术细节的话,也不多,requests+BeautifulSoup的使用,re正则,Python数据类型,Python线程,dbm、pickle等数据持久化库的使用,等等,这个工具也就这么些知识范畴了。当然,Python是面向对象的,编程思想是所有语言通用的,这个不是一朝一夕的事,也没办法通过语言描述清楚。各位对号入座,以上哪个知识面不足的自己去翻资料学习,我可是直接贴代码的。
说到Python的学习还是多说两句吧,以前学习Python爬虫的时候看的是 @工匠若水 https://blog.csdn.net/yanbober的博客,这哥们的Python文章写的真不错,对于有过编程经验却从没接触过Python的人很有帮助,基本上很快就能上手一个小项目。得嘞,撸代码:
import url_manager
import html_parser
import html_download
import persist_util
from tkinter import *
from threading import Thread
import os
class SpiderMain(object):
def __init__(self):
self.mUrlManager = url_manager.UrlManager()
self.mHtmlParser = html_parser.HtmlParser()
self.mHtmlDownload = html_download.HtmlDownload()
self.mPersist = persist_util.PersistUtil()
# 加载历史下载链接
def load_history(self):
history_download_links = self.mPersist.load_history_links()
if history_download_links is not None and len(history_download_links) > 0:
for download_link in history_download_links:
self.mUrlManager.add_download_url(download_link)
d_log("加载历史下载链接: " + download_link)
# 保存历史下载链接
def save_history(self):
history_download_links = self.mUrlManager.get_download_url()
if history_download_links is not None and len(history_download_links) > 0:
self.mPersist.save_history_links(history_download_links)
def craw_movie_links(self, root_url, score=8):
count = 0;
self.mUrlManager.add_url(root_url)
while self.mUrlManager.has_continue():
try:
count = count + 1
url = self.mUrlManager.get_url()
d_log("craw %d : %s" % (count, url))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Referer': url
}
content = self.mHtmlDownload.down_html(url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_urls, next_link = self.mHtmlParser.parser_movie_link(doc)
if movie_urls is not None and len(movie_urls) > 0:
for movie_url in movie_urls:
d_log('movie info url: ' + movie_url)
content = self.mHtmlDownload.down_html(movie_url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_name, movie_score, movie_xunlei_links = self.mHtmlParser.parser_movie_info(doc, score=score)
if movie_xunlei_links is not None and len(movie_xunlei_links) > 0:
for xunlei_link in movie_xunlei_links:
# 判断该电影是否已经下载过了
is_download = self.mUrlManager.has_download(xunlei_link)
if is_download == False:
# 没下载过的电影添加到迅雷下载列表
d_log('开始下载 ' + movie_name + ', 链接地址: ' + xunlei_link)
self.mUrlManager.add_download_url(xunlei_link)
os.system(r'"D:\迅雷\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link))
# 每下载一部电影都实时更新数据库,这样可以保证即使程序异常退出也不会重复下载该电影
self.save_history()
if next_link is not None:
d_log('next link: ' + next_link)
self.mUrlManager.add_url(next_link)
except Exception as e:
d_log('错误信息: ' + str(e))
def runner(rootLink=None, scoreLimit=None):
if rootLink is None:
return
spider = SpiderMain()
spider.load_history()
if scoreLimit is None:
spider.craw_movie_links(rootLink)
else:
spider.craw_movie_links(rootLink, score=float(scoreLimit))
spider.save_history()
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/index.html'
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/list_23_207.html'
def start(rootLink, scoreLimit):
loop_thread = Thread(target=runner, args=(rootLink, scoreLimit,), name='LOOP THREAD')
#loop_thread.setDaemon(True)
loop_thread.start()
#loop_thread.join() # 不能让主线程等待,否则GUI界面将卡死
btn_start.configure(state='disable')
# 刷新GUI界面,文字滚动效果
def d_log(log):
s = log + '\n'
txt.insert(END, s)
txt.see(END)
if __name__ == "__main__":
rootGUI = Tk()
rootGUI.title('XX电影自动下载工具')
# 设置窗体背景颜色
black_background = '#000000'
rootGUI.configure(background=black_background)
# 获取屏幕宽度和高度
screen_w, screen_h = rootGUI.maxsize()
# 居中显示窗体
window_x = (screen_w - 640) / 2
window_y = (screen_h - 480) / 2
window_xy = '640x480+%d+%d' % (window_x, window_y)
rootGUI.geometry(window_xy)
lable_link = Label(rootGUI, text='解析根地址: ',\
bg='black',\
fg='red', \
font=('宋体', 12), \
relief=FLAT)
lable_link.place(x=20, y=20)
lable_link_width = lable_link.winfo_reqwidth()
lable_link_height = lable_link.winfo_reqheight()
input_link = Entry(rootGUI)
input_link.place(x=20+lable_link_width, y=20, relwidth=0.5)
lable_score = Label(rootGUI, text='电影评分限制: ', \
bg='black', \
fg='red', \
font=('宋体', 12), \
relief=FLAT)
lable_score.place(x=20, y=20+lable_link_height+10)
input_score = Entry(rootGUI)
input_score.place(x=20+lable_link_width, y=20+lable_link_height+10, relwidth=0.3)
btn_start = Button(rootGUI, text='开始下载', command=lambda: start(input_link.get(), input_score.get()))
btn_start.place(relx=0.4, rely=0.2, relwidth=0.1, relheight=0.1)
txt = Text(rootGUI)
txt.place(rely=0.4, relwidth=1, relheight=0.5)
rootGUI.mainloop()
spider_main.py,主代码入口,主要是tkinter 实现的一个简陋的界面,可以输入根地址,电影最低评分。所谓的根地址就是某天堂网站的一类电影的入口,比如进入首页有如下的分类,最新电影、日韩电影、欧美影片、2019精品专区,等等。这里以2019精品专区为例(https://www.dytt8.net/html/gndy/dyzz/index.html),当然,用其它的分类地址入口也是可以的。评分就是个过滤电影的条件,要学会对垃圾电影说不,浪费时间浪费表情,你可以指定大于等于8分的电影才下载,也可以指定大于等于9分等,必须输入数字哈,输入些乱七八糟的东西进去程序会崩溃,这个细节我懒得处理。
'''
URL链接管理类,负责管理爬取下来的电影链接地址,包括新解析出来的链接地址,和已经下载过的链接地址,保证相同的链接地址只会下载一次
'''
class UrlManager(object):
def __init__(self):
self.urls = set()
self.used_urls = set()
self.download_urls = set()
def add_url(self, url):
if url is None:
return
if url not in self.urls and url not in self.used_urls:
self.urls.add(url)
def add_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_url(url)
def has_continue(self):
return len(self.urls) > 0
def get_url(self):
url = self.urls.pop()
self.used_urls.add(url)
return url
def get_download_url(self):
return self.download_urls
def has_download(self, url):
return url in self.download_urls
def add_download_url(self, url):
if url is None:
return
if url not in self.download_urls:
self.download_urls.add(url)
url_manager.py,注释里写的很清楚了,基本上每个py文件的关键地方我都写了比较详细的注释
import requests
from requests import Timeout
'''
HtmlDownload,通过一个链接地址将该html页面整体down下来,然后通过html_parser.py解析其中有价值的信息
'''
class HtmlDownload(object):
def __init__(self):
self.request_session = requests.session()
self.request_session.proxies
def down_html(self, url, retry_count=3, headers=None, proxies=None, data=None):
if headers:
self.request_session.headers.update(headers)
try:
if data:
content = self.request_session.post(url, data=data, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
else:
content = self.request_session.get(url, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
except (ConnectionError, Timeout) as e:
print('HtmlDownload ConnectionError or Timeout: ' + str(e))
if retry_count > 0:
self.down_html(url, retry_count-1, headers, proxies, data)
return None
except Exception as e:
print('HtmlDownload Exception: ' + str(e))
html_download.py,就是用requests将静态网页的内容整体down下来
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
import urllib.parse
import base64
'''
html页面解析器
'''
class HtmlParser(object):
# 解析电影列表页面,获取电影详情页面的链接
def parser_movie_link(self, content):
try:
urls = set()
next_link = None
doc = BeautifulSoup(content, 'lxml')
div_content = doc.find('div', class_='co_content8')
if div_content is not None:
tables = div_content.find_all('table')
if tables is not None and len(tables) > 0:
for table in tables:
link = table.find('a', class_='ulink')
if link is not None:
print('movie name: ' + link.text)
movie_link = urljoin('https://www.dytt8.net', link.get('href'))
print('movie link ' + movie_link)
urls.add(movie_link)
next = div_content.find('a', text=re.compile(r".*?下一页.*?"))
if next is not None:
next_link = urljoin('https://www.dytt8.net/html/gndy/dyzz/', next.get('href'))
print('movie next link ' + next_link)
return urls, next_link
except Exception as e:
print('解析电影链接地址发生错误: ' + str(e))
# 解析电影详情页面,获取电影详细信息
def parser_movie_info(self, content, score=8):
try:
movie_name = None # 电影名称
movie_score = 0 # 电影评分
movie_xunlei_links = set() # 电影的迅雷下载地址,可能存在多个
doc = BeautifulSoup(content, 'lxml')
movie_name = doc.find('title').text.replace('迅雷下载_电影天堂', '')
#print(movie_name)
div_zoom = doc.find('div', id='Zoom')
if div_zoom is not None:
# 获取电影评分
span_txt = div_zoom.text
txt_list = span_txt.split('◎')
if txt_list is not None and len(txt_list) > 0:
for tl in txt_list:
if 'IMDB' in tl or 'IMDb' in tl or 'imdb' in tl or 'IMdb' in tl:
txt_score = tl.split('/')[0]
print(txt_score)
movie_score = re.findall(r"\d+\.?\d*", txt_score)
if movie_score is None or len(movie_score) <= 0:
movie_score = 1
else:
movie_score = movie_score[0]
print(movie_name + ' IMDB影片分数: ' + str(movie_score))
if float(movie_score) < score:
print('电影评分低于' + str(score) + ', 忽略')
return movie_name, movie_score, movie_xunlei_links
txt_a = div_zoom.find_all('a', href=re.compile(r".*?ftp:.*?"))
if txt_a is not None:
# 获取电影迅雷下载地址,base64转成迅雷格式
for alink in txt_a:
xunlei_link = alink.get('href')
'''
这里将电影链接转换成迅雷的专用下载链接,后来发现不转换迅雷也能识别
xunlei_link = urllib.parse.quote(xunlei_link)
xunlei_link = xunlei_link.replace('%3A', ':')
xunlei_link = xunlei_link.replace('%40', '@')
xunlei_link = xunlei_link.replace('%5B', '[')
xunlei_link = xunlei_link.replace('%5D', ']')
xunlei_link = 'AA' + xunlei_link + 'ZZ'
xunlei_link = base64.b64encode(xunlei_link.encode('gbk'))
xunlei_link = 'thunder://' + str(xunlei_link, encoding='gbk')
'''
print(xunlei_link)
movie_xunlei_links.add(xunlei_link)
return movie_name, movie_score, movie_xunlei_links
except Exception as e:
print('解析电影详情页面错误: ' + str(e))
html_parser.py,用bs4解析down下来的html页面内容,根据网页规则过去我们需要的东西,这是爬虫最重要的地方,写爬虫的目的就是想要取出对我们有用的东西。
import dbm
import pickle
import os
'''
数据持久化工具类
'''
class PersistUtil(object):
def save_data(self, name='No Name', urls=None):
if urls is None or len(urls) <= 0:
return
try:
history_db = dbm.open('downloader_history', 'c')
history_db[name] = str(urls)
finally:
history_db.close()
def get_data(self):
history_links = set()
try:
history_db = dbm.open('downloader_history', 'r')
for key in history_db.keys():
history_links.add(str(history_db[key], 'gbk'))
except Exception as e:
print('遍历dbm数据失败: ' + str(e))
return history_links
# 使用pickle保存历史下载记录
def save_history_links(self, urls):
if urls is None or len(urls) <= 0:
return
with open('DownloaderHistory', 'wb') as pickle_file:
pickle.dump(urls, pickle_file)
# 获取保存在pickle中的历史下载记录
def load_history_links(self):
if os.path.exists('DownloaderHistory'):
with open('DownloaderHistory', 'rb') as pickle_file:
return pickle.load(pickle_file)
else:
return None
persist_util.py,数据持久化工具类。
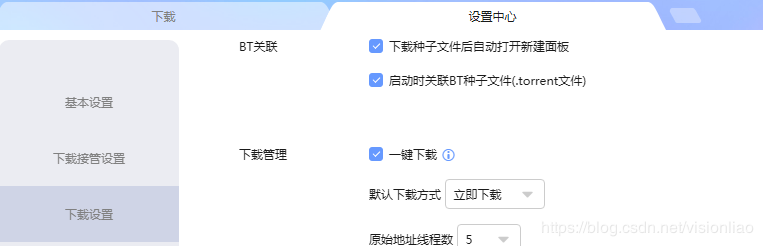
这样代码部分就完成了,说下迅雷,我安装的是最新版的迅雷X,一定要如下图一样在迅雷设置打开一键下载功能,否则每次新增一个下载任务都会弹出用户确认框的,还有就是调用迅雷下载资源的代码:os.system(r'"D:\迅雷\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link)),一定要去到迅雷安装目录找到Thunder.exe文件,不能用快捷方式的地址(我的电脑->迅雷->右键属性->目标,迅雷X这里显示的路径是快捷方式的路径,不能用这个),否则找不到程序。
到这里你应该就可以电影爬起来了,妥妥的。当然,你想要优化也可以,程序有很多可以优化的地方,比如线程那一块,比如数据持久化那里..... 初学者可以通过这个练手,然后自己去分析分析静态网站的规则,把解析html那一块的代码改改就可以爬其它的网站了,比如那些有着危险动作的电影... 不过这类电影还是少看为妙,要多读书,偶尔看了也要擦擦干净,洗洗干净,要讲卫生。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python爬虫实现百度图片自动下载
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载. 搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看: 随便搜索几个关键字,可以看到已经搜索出来很多张图片: 分析网页 我们点击右键,查看源代码: 打开源代码之后,发现一堆源代码比较难找出我们想要的资源. 这个时候,就
-
使用python采集脚本之家电子书资源并自动下载到本地的实例脚本
jb51上面的资源还比较全,就准备用python来实现自动采集信息,与下载啦. Python具有丰富和强大的库,使用urllib,re等就可以轻松开发出一个网络信息采集器! 下面,是我写的一个实例脚本,用来采集某技术网站的特定栏目的所有电子书资源,并下载到本地保存! 软件运行截图如下: 在脚本运行时期,不但会打印出信息到shell窗口,还会保存日志到txt文件,记录采集到的页面地址,书籍的名称,大小,服务器本地下载地址以及百度网盘的下载地址! 实例采集并下载我们的python栏目电子书资源: #
-
Python FTP文件定时自动下载实现过程解析
这篇文章主要介绍了Python FTP文件定时自动下载实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.需求: 某数据公司每日15:00~17:00之间,在其FTP发布当日数据供下载,我方需及时下载当日数据至指定本地目录. 二.分析: 1.需实现FTP登陆.查询.下载功能: 解答:使用内置的ftplib模块中FTP类: 2.需判断文件是否下载: 解答:使用os模块中path.exists方法: 3.需判断在指定时间段内才执行下载任
-
Python实现115网盘自动下载的方法
本文实例讲述了Python实现115网盘自动下载的方法.分享给大家供大家参考.具体实现方法如下: 实例中的1.txt,是网页http://bbs.pediy.com/showthread.php?t=144788另存为1.txt 通过每3秒钟复制一个下载链接到粘贴板,复制时会自动调用115客户端下载,每下载10个文件会手工输入一个字符,防止一下下载太多,卡死机器 具体代码如下: import re, os, time import webbrowser import urllib if __na
-
Python3.x+迅雷x 自动下载高分电影的实现方法
快要过年了,大家都在忙些什么呢?一到年底公司各种抢票,备年货,被这过年的气氛一烘,都归心似箭,哪还有心思上班啊.归心似箭=产出低下=一行代码十个错=无聊.于是想起了以前学过一段时间的Python,自己平时也挺爱看电影的,手动点进去看电影详情然后一部一部的去下载太烦了,何不用Python写个自动下载电影的工具呢?诶,这么一想就不无聊了.以前还没那么多XX会员的时候,想看看电影都是去XX天堂去找电影资源,大部分想看的电影还是有的,就它了,爬它! 话说以前玩Python的时候爬过挺多网站的,都是在公司
-
详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
Python3实现Web网页图片下载
先来介绍一些python web编程基础知识 1. GET与POST区别 1)POST是被设计用来向web服务器上放东西的,而GET是被设计用来从服务器取东西的,GET也能够向服务器传送较少的数据,而Get之所以也能传送数据,只是用来设计告诉服务器,你到底需要什么样的数据.POST的信息作为HTTP 请求的内容,而GET是在HTTP 头部传输的: 2)POST与GET在HTTP 中传送的方式不同,GET的参数是在HTTP 的头部传送的,而Post的数据则是在HTTP 请求的内容里传送; 3)PO
-
Centos7下源码安装Python3 及shell 脚本自动安装Python3的教程
一.源码安装 首先安装开发工具包 yum groupinstall -y "Development tools" 安装依赖软件包 yum -y install gcc gcc-c++ zlib-devel bzip2-devel openssl-devel sqlite-devel readline-devel libffi-devel wget 上Python 官网 找源码包的下载地址 wget https://www.python.org/ftp/python/3.7.6/Pyth
-
python实现自动下载sftp文件
本文实例为大家分享了python实现自动下载sftp文件的具体代码,供大家参考,具体内容如下 实现功能:利用python自动连接sftp,并下载sftp中指定目录下的所有目录及文件 系统环境:centos7 python版本:python3 使用模块包:paramiko ,若未安装,可使用 pip install paramiko 进行安装 需求实例:sftp中的文件如下 将sftp根目录中的所有文件下载到本地 /data/test 目录中 实现代码: #!/usr/bin/python # c
-
php实现把url转换迅雷thunder资源下载地址的方法
本文实例讲述了php实现把url转换迅雷thunder资源下载地址的方法.分享给大家供大家参考.具体方法分析如下: 如果你知道迅雷地址的生成规则你就不觉得迅雷的url资源下载地址有多么复杂了, 其实雷的地址就是原url前面带AA后面带BB之后再base64_encode编码即可 如下例子所示: 复制代码 代码如下: <?php function Thunder($url, $type='en') { $url ='http://www.jb51.net'; if($type =='en'){ r
-
CodeIgniter实现从网站抓取图片并自动下载到文件夹里的方法
本文实例讲述了CodeIgniter实现从网站抓取图片并自动下载到文件夹里的方法.分享给大家供大家参考.具体如下: 因为某网站看图比较坑爹,要一页一页的翻页....所以....就写了这么个东西 (我是产品不是程序员)运行速度简直无法忍受,而且经常会有错误发生,所以希望大家帮忙改进(PHP). 当然也欢迎看到PYTHON,GOLANG的版本~~^_^ 1. controllers: $this->load->helper('date'); $this->load->helper('p
-
js自动下载文件到本地的实现代码
复制代码 代码如下: <html> <head> <title>js自动下载文件到本地</title> <script language="javascript" type="text/javascript"> function InitAjax() { var ajax; if(window.ActiveXObject){ var versions = ['Microsoft.XMLHTTP', 'MSX
-
FlashGet远程控制自动下载的软件与方法
FlashGet是大家经常使用的一款下载软件,它强大的下载功能以及高速度,高效率,多任务管理等附加功能受到用户的青睐,这也是它为何能在大型软件下载网站占据首位的原因.那你有没有想过,只要通过一封电子邮件,就可以让远在千里的电脑自动下载你所让它下载的东西呢?当然这个软件不是黑客所使用的远程控制软件,而是笔者今天要为大家介绍的一款FlashGet的扩展程序--FlashCheck. 软件资料 软件名称:FlashCheck 软件版本:V 0.57b 软件大小:390KB 软件性质:共享软件 支持平台