Pytorch 如何加速Dataloader提升数据读取速度
在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘。
很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做 Backpropagation 。
这种症状的体现是使用 Nividia-smi 查看 GPU 使用率时,Memory-Usage 占用率很高,但是 GPU-Util 时常为 0% ,如下图所示:
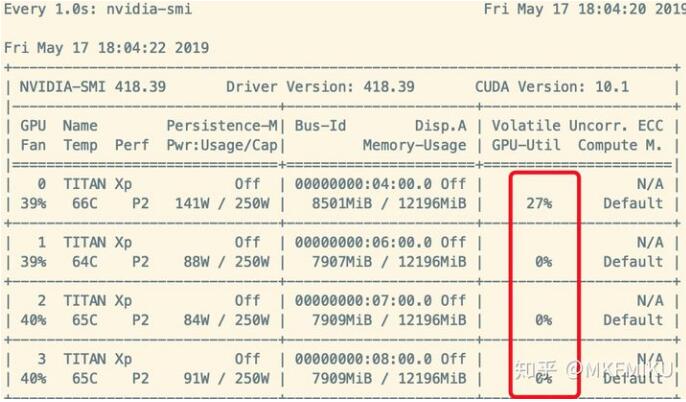
如何解决这种问题呢?
在 Nvidia 提出的分布式框架 Apex 里面,我们在源码里面找到了一个简单的解决方案:
https://github.com/NVIDIA/apex/blob/f5cd5ae937f168c763985f627bbf850648ea5f3f/examples/imagenet/main_amp.py#L256
class data_prefetcher():
def __init__(self, loader):
self.loader = iter(loader)
self.stream = torch.cuda.Stream()
self.mean = torch.tensor([0.485 * 255, 0.456 * 255, 0.406 * 255]).cuda().view(1,3,1,1)
self.std = torch.tensor([0.229 * 255, 0.224 * 255, 0.225 * 255]).cuda().view(1,3,1,1)
# With Amp, it isn't necessary to manually convert data to half.
# if args.fp16:
# self.mean = self.mean.half()
# self.std = self.std.half()
self.preload()
def preload(self):
try:
self.next_input, self.next_target = next(self.loader)
except StopIteration:
self.next_input = None
self.next_target = None
return
with torch.cuda.stream(self.stream):
self.next_input = self.next_input.cuda(non_blocking=True)
self.next_target = self.next_target.cuda(non_blocking=True)
# With Amp, it isn't necessary to manually convert data to half.
# if args.fp16:
# self.next_input = self.next_input.half()
# else:
self.next_input = self.next_input.float()
self.next_input = self.next_input.sub_(self.mean).div_(self.std)
我们能看到 Nvidia 是在读取每次数据返回给网络的时候,预读取下一次迭代需要的数据,
那么对我们自己的训练代码只需要做下面的改造:
training_data_loader = DataLoader(
dataset=train_dataset,
num_workers=opts.threads,
batch_size=opts.batchSize,
pin_memory=True,
shuffle=True,
)
for iteration, batch in enumerate(training_data_loader, 1):
# 训练代码
#-------------升级后---------
data, label = prefetcher.next()
iteration = 0
while data is not None:
iteration += 1
# 训练代码
data, label = prefetcher.next()
这样子我们的 Dataloader 就像打了鸡血一样提高了效率很多,如下图:
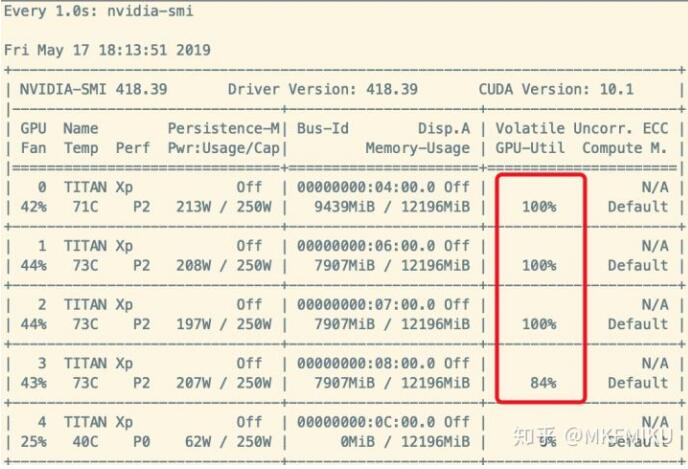
当然,最好的解决方案还是从硬件上,把读取速度慢的机械硬盘换成 NVME 固态吧~
补充:Pytorch设置多线程进行dataloader时影响GPU运行
使用PyTorch设置多线程(threads)进行数据读取时,其实是假的多线程,他是开了N个子进程(PID是连续的)进行模拟多线程工作。
以载入cocodataset为例
DataLoader
dataloader = torch.utils.data.DataLoader(COCODataset(config["train_path"],
(config["img_w"], config["img_h"]),
is_training=True),
batch_size=config["batch_size"],
shuffle=True, num_workers=32, pin_memory=True)
numworkers就是指定多少线程的参数,原为32。
检查GPU是否运行该程序
查看运行在gpu上的所有程序:
fuser -v /dev/nvidia*
如果没有返回,则该程序并没有在GPU上运行
指定GPU运行
将num_workers改成0即可
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

我对PyTorch dataloader里的shuffle=True的理解
对shuffle=True的理解: 之前不了解shuffle的实际效果,假设有数据a,b,c,d,不知道batch_size=2后打乱,具体是如下哪一种情况: 1.先按顺序取batch,对batch内打乱,即先取a,b,a,b进行打乱: 2.先打乱,再取batch. 证明是第二种 shuffle (bool, optional): set to ``True`` to have the data reshuffled at every epoch (default: ``False``). if
-
Pytorch数据读取之Dataset和DataLoader知识总结
一.前言 确保安装 scikit-image numpy 二.Dataset 一个例子: # 导入需要的包 import torch import torch.utils.data.dataset as Dataset import numpy as np # 编造数据 Data = np.asarray([[1, 2], [3, 4],[5, 6], [7, 8]]) Label = np.asarray([[0], [1], [0], [2]]) # 数据[1,2],对应的标签是[0],数据
-
Pytorch自定义Dataset和DataLoader去除不存在和空数据的操作
[源码GitHub地址]:点击进入 1. 问题描述 之前写了一篇关于<pytorch Dataset, DataLoader产生自定义的训练数据>的博客,但存在一个问题,我们不能在Dataset做一些数据清理,如果我们传递给Dataset数据,本身存在问题,那么迭代过程肯定出错的. 比如我把很多图片路径都传递给Dataset,如果图片路径都是正确的,且图片都存在也没有损坏,那显然运行是没有问题的: 但倘若传递给Dataset的图片路径有些图片是不存在,这时你通过Dataset读取图片数据,然后
-
pytorch DataLoader的num_workers参数与设置大小详解
Q:在给Dataloader设置worker数量(num_worker)时,到底设置多少合适?这个worker到底怎么工作的? train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4) 参数详解: 1.每次dataloader加载数据时:dataloader一次性创建num_worker个worker,(也可以说dataloader一次
-
pytorch Dataset,DataLoader产生自定义的训练数据案例
1. torch.utils.data.Dataset datasets这是一个pytorch定义的dataset的源码集合.下面是一个自定义Datasets的基本框架,初始化放在__init__()中,其中__getitem__()和__len__()两个方法是必须重写的. __getitem__()返回训练数据,如图片和label,而__len__()返回数据长度. class CustomDataset(data.Dataset):#需要继承data.Dataset def __init_
-
PyTorch实现重写/改写Dataset并载入Dataloader
前言 众所周知,Dataset和Dataloder是pytorch中进行数据载入的部件.必须将数据载入后,再进行深度学习模型的训练.在pytorch的一些案例教学中,常使用torchvision.datasets自带的MNIST.CIFAR-10数据集,一般流程为: # 下载并存放数据集 train_dataset = torchvision.datasets.CIFAR10(root="数据集存放位置",download=True) # load数据 train_loader = t
-
Pytorch 如何加速Dataloader提升数据读取速度
在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘. 很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做 Backpropagation . 这种症状的体现是使用 Nividia-smi 查看 GPU 使用率时,Memory-Usage 占用率很高,但是 GPU-Util 时常为 0% ,如下图所示: 如何解决这种问题呢? 在 Nvidia 提出的分布式框架 Apex 里面,我们在源码里面找到了一个简单的解决方案: htt
-
mysql数据库插入速度和读取速度的调整记录
(1)提高数据库插入性能中心思想:尽量将数据一次性写入到Data File和减少数据库的checkpoint 操作.这次修改了下面四个配置项: 1)将 innodb_flush_log_at_trx_commit 配置设定为0:按过往经验设定为0,插入速度会有很大提高. 0: Write the log buffer to the log file and flush the log file every second, but do nothing at transaction commit.
-
PyTorch数据读取的实现示例
前言 PyTorch作为一款深度学习框架,已经帮助我们实现了很多很多的功能了,包括数据的读取和转换了,那么这一章节就介绍一下PyTorch内置的数据读取模块吧 模块介绍 pandas 用于方便操作含有字符串的表文件,如csv zipfile python内置的文件解压包 cv2 用于图片处理的模块,读入的图片模块为BGR,N H W C torchvision.transforms 用于图片的操作库,比如随机裁剪.缩放.模糊等等,可用于数据的增广,但也不仅限于内置的图片操作,也可以自行进行图片数
-
Pytorch数据读取与预处理该如何实现
在炼丹时,数据的读取与预处理是关键一步.不同的模型所需要的数据以及预处理方式各不相同,如果每个轮子都我们自己写的话,是很浪费时间和精力的.Pytorch帮我们实现了方便的数据读取与预处理方法,下面记录两个DEMO,便于加快以后的代码效率. 根据数据是否一次性读取完,将DEMO分为: 1.串行式读取.也就是一次性读取完所有需要的数据到内存,模型训练时不会再访问外存.通常用在内存足够的情况下使用,速度更快. 2.并行式读取.也就是边训练边读取数据.通常用在内存不够的情况下使用,会占用计算资源,如果分
-
如何使用PyTorch实现自由的数据读取
目录 前言 PyTorch数据读入函数介绍 ImageFolder Dataset DataLoader 问题来源 自定义数据读入的举例实现 总结 前言 很多前人曾说过,深度学习好比炼丹,框架就是丹炉,网络结构及算法就是单方,而数据集则是原材料,为了能够炼好丹,首先需要一个使用称手的丹炉,同时也要有好的单方和原材料,最后就需要炼丹师们有着足够的经验和技巧掌握火候和时机,这样方能炼出绝世好丹. 对于刚刚进入炼丹行业的炼丹师,网上都有一些前人总结的炼丹技巧,同时也有很多炼丹师的心路历程以及丹师对整个
-
pytorch制作自己的LMDB数据操作示例
本文实例讲述了pytorch制作自己的LMDB数据操作.分享给大家供大家参考,具体如下: 前言 记录下pytorch里如何使用lmdb的code,自用 制作部分的Code code就是ASTER里数据制作部分的代码改了点,aster_train.txt里面就算图片的完整路径每行一个,图片同目录下有同名的txt,里面记着jpg的标签 import os import lmdb # install lmdb by "pip install lmdb" import cv2 import n
-
详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
pytorch多进程加速及代码优化方法
目标:优化代码,利用多进程,进行近实时预处理.网络预测及后处理: 本人尝试了pytorch的multiprocessing,进行多进程同步处理以上任务. from torch.multiprocessing import Pool,Manager 为了进行各进程间的通信,使用Queue,作为数据传输载体. manager = Manager() input_queue = manager.Queue() output_queue = manager.Queue() show_queue = ma
-
pytorch 批次遍历数据集打印数据的例子
我就废话不多说了,直接上代码吧! from os import listdir import os from time import time import torch.utils.data as data import torchvision.transforms as transforms from torch.utils.data import DataLoader def printProgressBar(iteration, total, prefix='', suffix='', d